




 本文详细介绍了哈希(散列)的概念、哈希表的作用以及哈希函数的构造方法,包括除留余数法、数字分析法、平方取中法、分段叠加法和基数转换法。接着讨论了处理哈希冲突的开放寻址法和链地址法,并通过Python代码展示了这两种方法。最后,概述了哈希表的操作,如生成key、插入、查找和删除。
本文详细介绍了哈希(散列)的概念、哈希表的作用以及哈希函数的构造方法,包括除留余数法、数字分析法、平方取中法、分段叠加法和基数转换法。接着讨论了处理哈希冲突的开放寻址法和链地址法,并通过Python代码展示了这两种方法。最后,概述了哈希表的操作,如生成key、插入、查找和删除。
- 哈希(hash)也叫散列;是把任意长度的输入,通过哈希算法,变换成固定长度的输出,所输出的称为哈希值(哈希值所占的空间一般来说远小于输入值的空间,不同的输入可能会哈希出相同的输出)。
- 在数据结构中,使用Hash算法的数据结构叫做哈希表,也叫散列表,主要是为了提高查询的效率。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数就是hash函数,存放记录的数组叫做哈希表。在数据结构中应用时,有时需要较高的运算速度而弱化考虑抗碰撞性,可以使用自己构建的哈希函数。
1. hash函数的构造方法
hash函数的构造原则是:简单和均匀
即:
hash函数本身运算尽量简单,便于计算;
hash函数值必须在散列地址范围内,且分布均匀,冲突尽可能少;
下面是几种常用的hash函数构造方法:
- (1) 除留余数法
该方法是为简单的一种方法
h(key)=m%p ; m为表长,p为<=m的最大素数
关于p的选取:p应为不大于m的质数或不含20以下的质因子。如果p选取不当,会增加冲突的可能性
例:

- (2)数字分析法

- (3) 平方取中法
由于整数相除的运行速度通常比乘慢,因此有意识的避免除余法可以提高散列算法的运行时间。
平方取中法的具体方法是:首先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为hash值。因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址比较均匀。
例:将(0100,0110,1010,1001,0111)平方后得(0010000,0012100,1020100,1002001,0012321),若表长位1000,则取中间3位数作为散列地址,即(100,121,201,020,123)
-
(4) 分段叠加法
有时关键子所含的位数很多,平方取中法计算太复杂,则可将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分进行叠加,叠加和(舍去进位)作为散列地址。具体的叠加方式有移位叠加和折叠叠加。
例:key=926483715503
移位叠加:h(key)=627
折叠叠加:h(key)=330

-
(5)基数转换法

在实际应用中,根据实际情况选择采用恰当的散列方法,并用实际数据测试它的性能,,以便作出正确判定。
一般考虑以下因素:
(1) 计算hash函数所需时间
(2) 关键字长度
(3) 散列表大小
(4) 关键字分布的情况
(5) 记录查找的频率
2. 处理冲突的方法
2.1 开放寻址法
python中的字典,就是先求出散列值,然后用散列值取余就是存放的位置,有冲突时用开放寻址法解决
也叫再散列法,
基本思想:当key的初始散列地址h0出现冲突时,以h0位基础查找下一个地址h1,如果h1仍然冲突,以h0为基础产生另一个散列地址h2…直到找到不冲突的地址hi,将相应元素存入其中即可
公式:hi=(h(key)+di)%m
h(key)是哈希函数; m是表长; di为增量序列,增量有下面三种取值方式
- (1) 线性探测再散列
di=c*i
最简单的情况:c=1
冲突发生时,顺序查看表中的下一个单元,直到找到一个空单元或查遍全表
例:对关键字列表为[19,01,23,14,55,68,11,82,36],设定表长m为11;用线性探测再散列处理冲突。
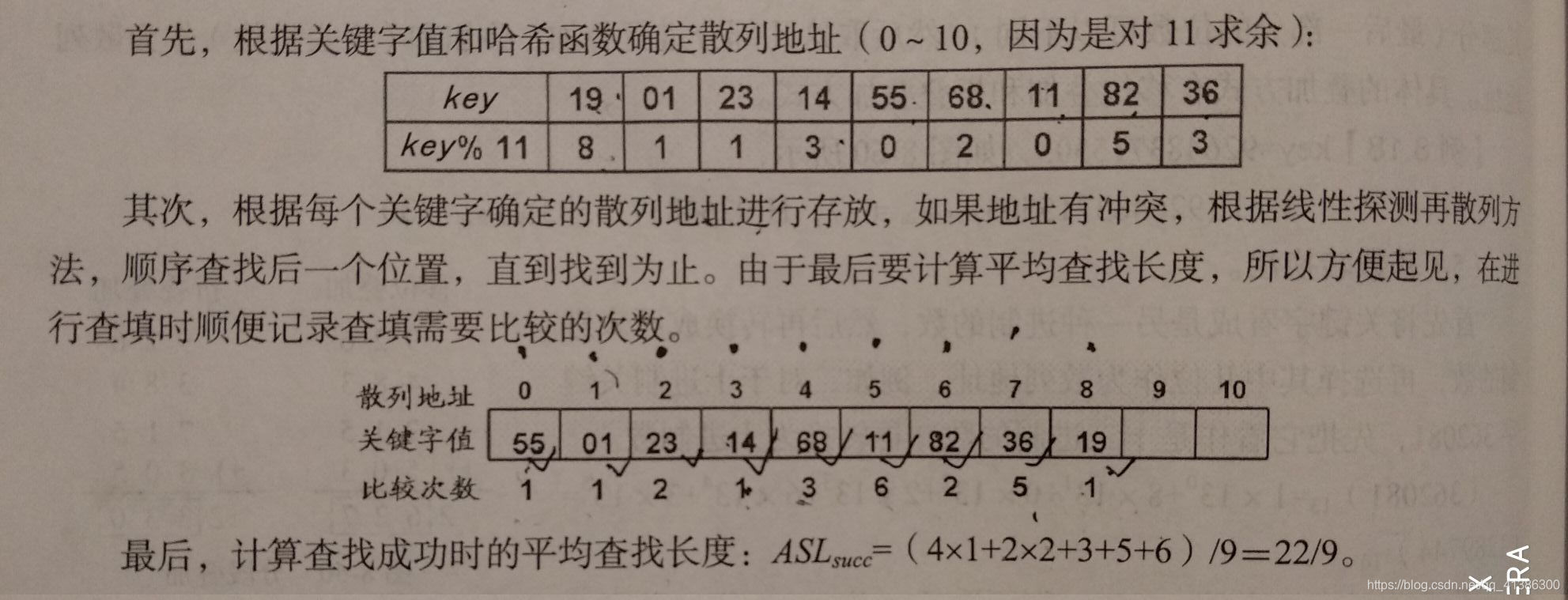
- (2)二次探测再散列
di=1 * *2,- 1 * *2,2 * *2,- 2 * *2…k * *2,- k * *2(k<=m/2)
冲突发生时,分别在左右进行跳跃式探测,较灵活,不易产生聚集,但缺点是不能探查到整个散列地址空间
对于上例,用二次探测再散列的方法解级冲突

- (3) 随机探测再散列
di=为随机数
这种方法需要一个随机数发生器,并给定一个随机数作为起始点。
2.2 链地址法
基本思想:把具有冲突的关键字链在同一个单链表中。
例:对上例,设定h(key)=key%7

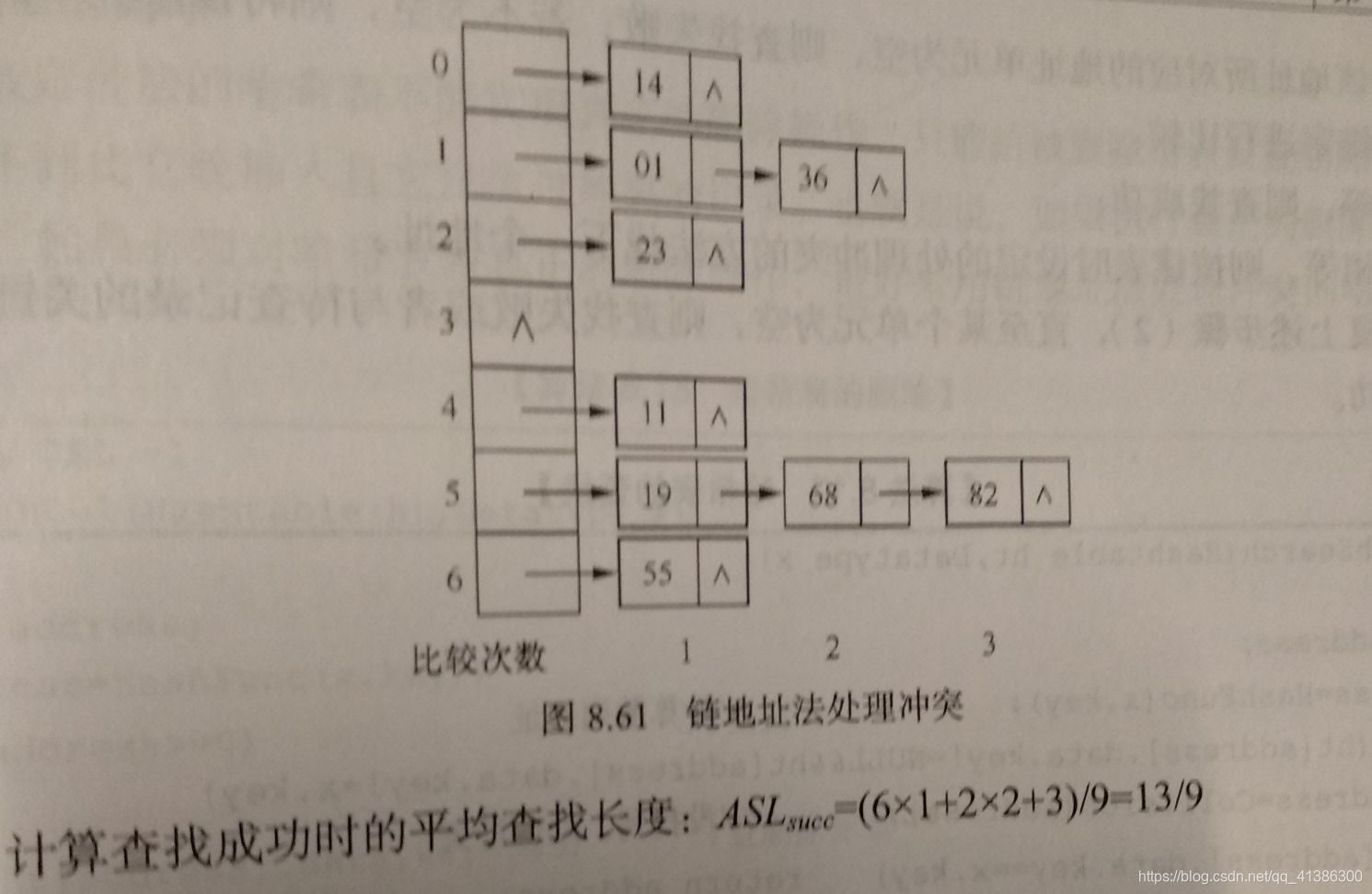
3. 操作
结点属性:
class Hash(object):
def __init__(self):
# 存放 开放定址法的哈希键值
self.data={}
# 存放链地址法的哈希键值
self.data_map={}
# 可在这里指定m
# self.length=m
3.1 生成新的key
也就是hash函数h(key)
def change_key(self,key,m,di):
#因为负数的%运算和我们预期的结果不一样,需要调整
if key+di<0:
return -(((-di)-key)%m)
return (key+di)%m
3.2 插入
- 根据开放定址处理冲突法 插入
基本思想:待插数据的key冲突时,根据 开放定址法生成新的key,继续比较…直至key不冲突,把值填入即可
# 开放定址法插入
def insert(self,value,m):
key=value%m
while key in self.data:
# 如果某个值是DEL,说明它被删掉了
if self.data[key]=='DEL':
self.data[key] = value
return
#线性探测再散列
key=self.change_key(key,m,1)
self.data[key]=value
- 根据链地址处理冲突法 插入
基本思路:根据待插值生成key,如果key已经存在,把值加入到key对应的链表中,如过不存在,给这个key新建一个链表,把值加入即可
# 链地址法插入,key对应的值是一个列表,里面存放的是key冲突的值
def insert2(self,value,m):
key=value%m
# 已经存在的话,直接加入列表中即可
if key in self.data_map:
self.data_map[key].append(value)
# 第一次出现需要建一个列表
else:
temp=[]
temp.append(value)
self.data_map[key]=temp
3.3 查找
- 线性探测再散列方法查找:
基本思想:根据待查找的值生成key,如果key对应的值和待查找的值不同时,继续生成新的key,直至找到返回
# 查找--线性探测再散列
def find(self,value,m):
key=value%m
while key in self.data:
if self.data[key]==value:
return key
# 线性探测再散列
key=self.change_key(key,m,1)
return False
- 二次探测再散列的方法查找
#查找--二次探测再散列的方法
def find2(self,value,m):
key=value%m
key_new=key
i=1
j=1
while key_new in self.data:
if self.data[key_new]==value:
return key_new
#j用来控制正负
di=i*i*j
key_new=self.change_key(key,m,di)
# key<时,找到对应的key
if key_new<0:
key_new=len(self.data)+key_new+1
if j>0:
j=-1
else:
i+=1
j=1
return False
3.4 删除
- 开放定址法的 删除
基本思路,找到要删除的数的key,把key对应的值设置成‘DEL‘,注意,这里不能删除,因为会找不到它之后插入的冲突的数
# 删除
def delete(self,value,m):
key=self.find(value,m)
if key:
self.data[key]='DEL'
else:
print('%s不存在' %(value))
- 链地址法的删除
根据值生成key,遍历key对应的链,找到后删掉就好
def delete_map(self,value,m):
key=value%m
print(key)
if key in self.data_map:
for i in self.data_map[key]:
if i==value:
del i
return
全部代码
class Hash(object):
def __init__(self):
# 存放 开放定址法的哈希键值
self.data={}
# 存放链地址法的哈希键值
self.data_map={}
# 可在这里指定m
# self.length=m
def change_key(self,key,m,di):
#因为负数的%运算和我们预期的结果不一样,需要调整
if key+di<0:
return -(((-di)-key)%m)
return (key+di)%m
# 开放定址法插入
def insert(self,value,m):
key=value%m
while key in self.data:
# 如果某个值是DEL,说明它被删掉了
if self.data[key]=='DEL':
self.data[key] = value
return
#线性探测再散列
key=self.change_key(key,m,1)
self.data[key]=value
# 链地址法插入,key对应的值是一个列表,里面存放的是key冲突的值
def insert2(self,value,m):
key=value%m
# 已经存在的话,直接加入列表中即可
if key in self.data_map:
self.data_map[key].append(value)
# 第一次出现需要建一个列表
else:
temp=[]
temp.append(value)
self.data_map[key]=temp
#输出存放 开放定址法的哈希键值
def print_hash(self):
for h in self.data:
print(h,':',self.data[h])
# 输出存放 链地址法的哈希键值
def print_hash_map(self):
for h in self.data_map:
print(h,':',self.data_map[h])
# 查找--线性探测再散列
def find(self,value,m):
key=value%m
while key in self.data:
if self.data[key]==value:
return key
# 线性探测再散列
key=self.change_key(key,m,1)
return False
#查找--二次探测再散列的方法
def find2(self,value,m):
key=value%m
key_new=key
i=1
j=1
while key_new in self.data:
if self.data[key_new]==value:
return key_new
#j用来控制正负
di=i*i*j
key_new=self.change_key(key,m,di)
# key<时,找到对应的key
if key_new<0:
key_new=len(self.data)+key_new+1
if j>0:
j=-1
else:
i+=1
j=1
return False
# 删除
def delete(self,value,m):
key=self.find(value,m)
if key:
self.data[key]='DEL'
else:
print('%s不存在' %(value))
def delete_map(self,value,m):
key=value%m
print(key)
if key in self.data_map:
for i in self.data_map[key]:
if i==value:
del i
return
if __name__ == '__main__':
h=Hash()
m=11
h.insert(1,m)
h.insert(23,m)
h.insert(12,m)
h.delete(1,m)
h.print_hash()
h.insert(1,m)
h.print_hash()
print(h.find(23,m))
# h.insert(13,m)
# h.insert(28,m)
#
# h.print_hash()
# print('--------------')
# h.insert2(2,m)
# h.insert2(13,m)
# h.insert2(15,m)
# h.insert2(4,m)
# h.print_hash_map()
# print('-------------')
# print(h.find(2,m))
# print(h.find(18,m))
# print('------------')
# print(h.find2(13,m))
# print((-(-4)-2)%11)
# print('--------------')
# h.delete(15,m)
# h.print_hash()
# h.insert2(11,m)
# h.insert2(8,m)
# h.insert2(22,m)
# h.insert2(15,m)
# h.delete_map(11,m)
# h.print_hash_map()

















 5444
5444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









