






某一天,运维团队收到告警,某业务中断,查看服务情况发现,该服务所在的k8s集群中的pod突然被OOM了,OOM killed。特殊的是这个pod所在的节点是Arm架构,以前这个pod所在的节点是x86架构,应该是集群扩容后调度到ARM节点上了,所以以前x86节点上该pod运行的好好的,同样配置搬过来也应该是没有任何问题才对,于是打算对pod在不同架构节点上的运行情况做一个初步分析。
pod的OOM机制:OOMScore 是针对 memory 的,当宿主上 memory 不足时系统会优先 kill 掉 OOMScore 值高的进程,可以使用 $ cat /proc/$PID/oom_score 查看进程的 OOMScore。对于pod,exec OOMScore 的取值范围为 [-1000, 1000],Guaranteed pod 的默认值为 -998,Burstable pod 的值为 2~999,BestEffort pod 的值为 1000,也就是说当系统 OOM 时,首先会 kill 掉 BestEffort pod 的进程,若系统依然处于 OOM 状态,然后才会 kill 掉 Burstable pod,最后是 Guaranteed pod;
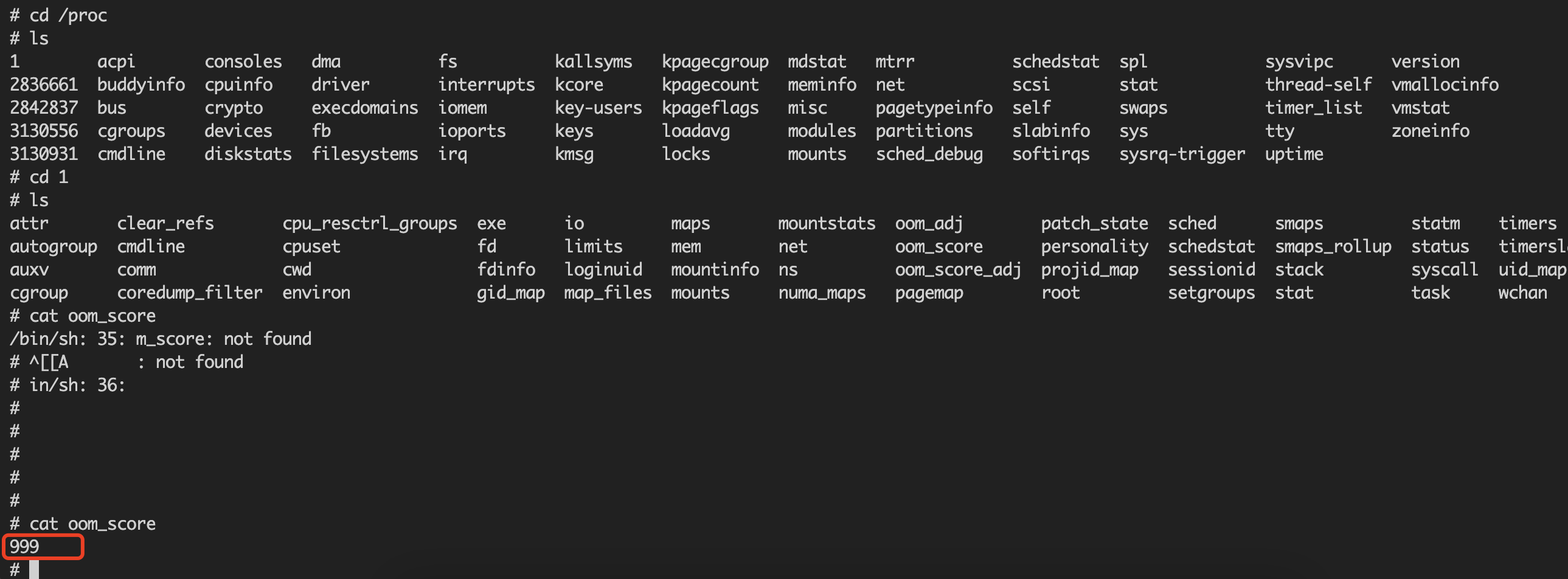
可以通过对重要pod设置合适的limits,request值,或者是更改QOS的类型Burstable,BestEffort, Guaranteed pod,从而降低某类pod的OOM发生的概率,但是治标不治本?
分析发生故障的集群组件的内存占用情况:
组件的woring_sets_bytes指标由普罗米修斯指标采集,鲲鹏ARM上部分组件存在内存占用较高的现象。container_memory_working_set_bytes 是容器真实使用的内存量,也是 limit 限制时的 oom 判断依据。当该指标值大于limIt in bytes就有可能发生OOM了。
经分析: container_memory_working_set_bytes = container_memory_usage_bytes – total_inactive_file
container_memory_usage_bytes = container_memory_rss + container_memory_cache + kernel memory(内存占用罪魁祸首?)
x86架构下的该pod的kernel memory: 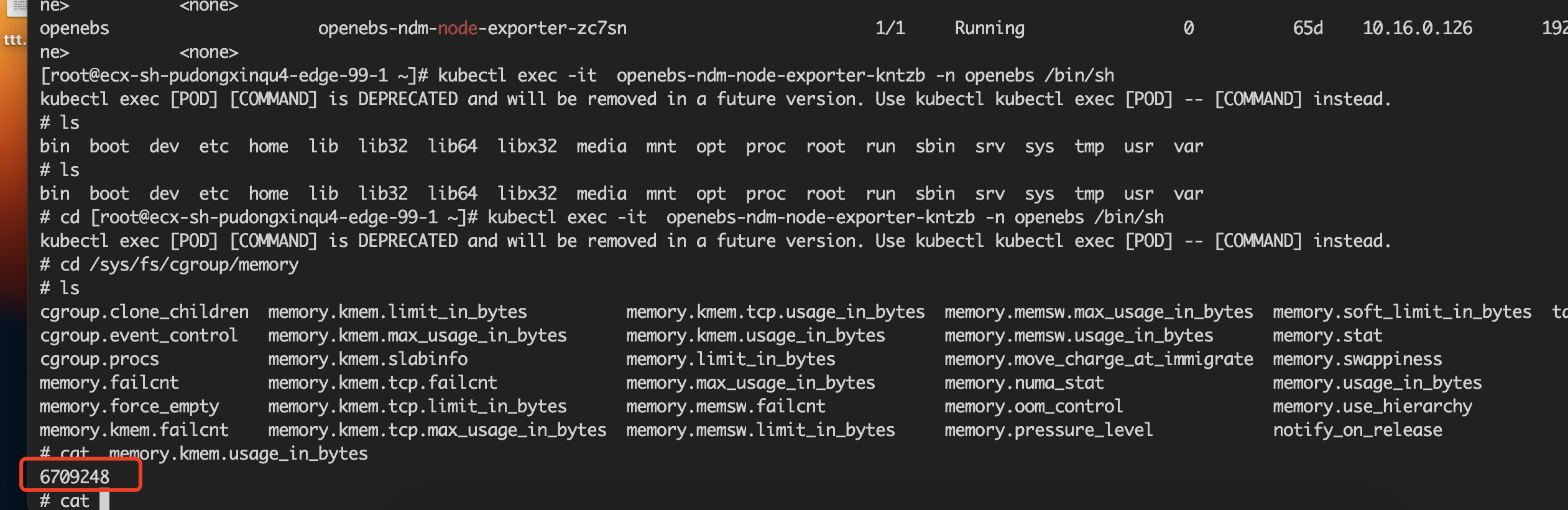
arm架构下该po的的kernel memory:
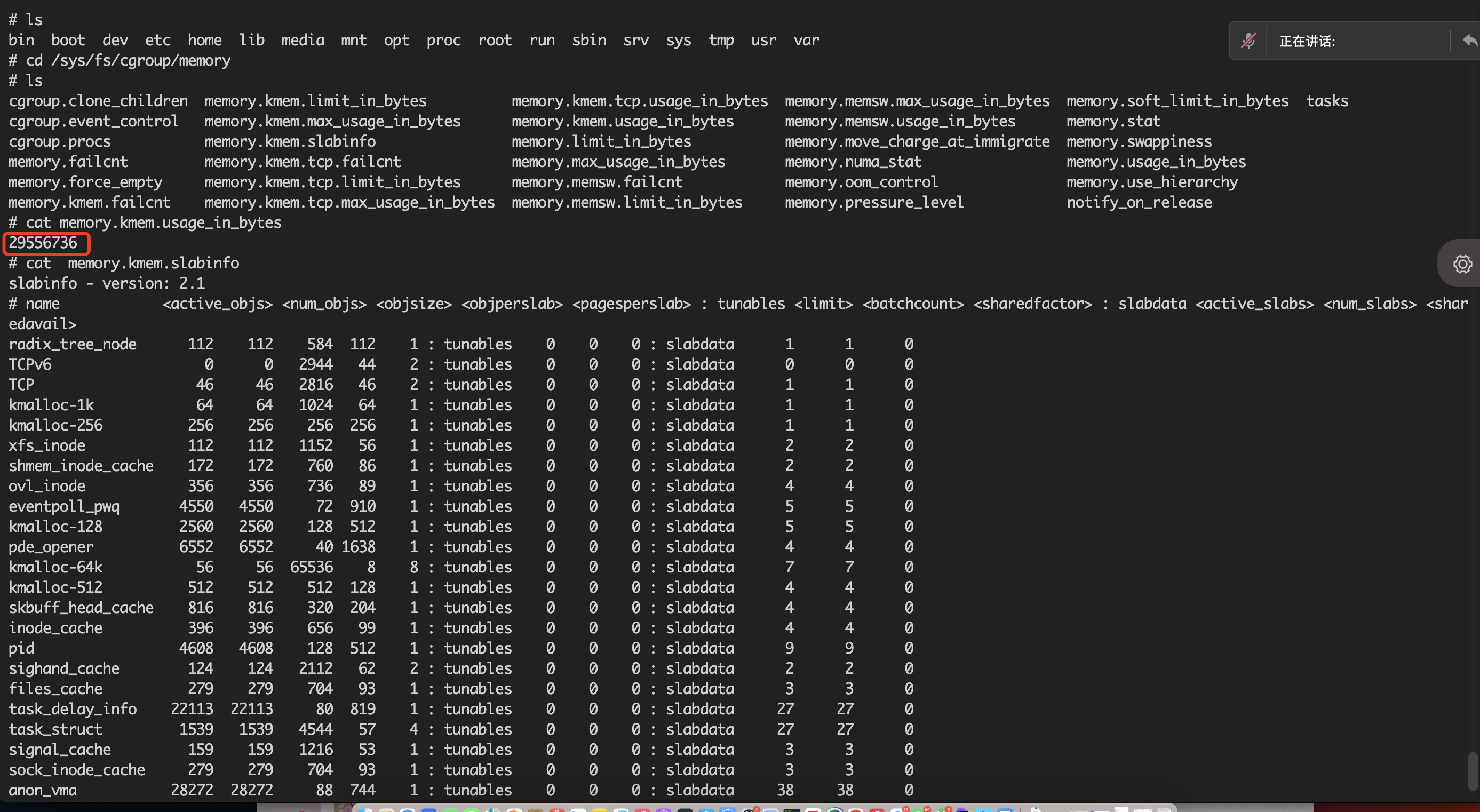
经统计分析,Arm组件的kernel memory平均值高于X86组件。由此可见,部分组件的kernel memory(ARM) >> kernel memory(x86)
然后分析了一下ARM架构下的memory.kmem.slabinfo这个有值代表存在内存泄漏的现象。发现确实存在cgroup泄漏。当前内核版本3.x或者4.x条件下,开启了kmem accounting功能,会导致memory cgroup的条目泄漏无法回收。索性关闭这功能不好吗?
关闭的几个方法:
- 升级内核 (升级系统内核至4.0以上)不保险,对业务影响较大。
2. 修改内核启动配置
kernel 提供了 cgroup.memory = nokmem 参数,关闭 kmem accounting 功能,配置该参数后,memory cgroup 就不会有单独的 slabinfo 文件,
3. 修改kubelet和runc进行关闭,kubelet在创建pod对应的cgroup目录时,也会调用libcontianer中的代码对cgroup做设置。在pkg/kubelet/cm/cgroup_manager_linux.go的Create方法中,会调用Manager.Apply方法,最终调用vendor/github.com/opencontainers/runc/libcontainer/cgroups/fs/memory.go中的MemoryGroup.Apply方法,关闭kmem accounting。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









