






 本文介绍如何利用iText库在Java后端生成包含页码、随机编号和当前日期的PDF文档,同时提供了生成指定长度随机数的方法及PDF页码的实现技巧。
本文介绍如何利用iText库在Java后端生成包含页码、随机编号和当前日期的PDF文档,同时提供了生成指定长度随机数的方法及PDF页码的实现技巧。
使用itext在java后端生成pdf,采用的jar包注意依赖问题,下面是我使用的
<!-- pdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.10</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
pdf生成
/**
* 创建pdf
* @param examjson
* @param paperid
* @param path
* @param pathimg
* @return
*/
public String createPdfAdd1(String examjson , Integer paperid , String path ,String pathimg){
//Map<String, Object> exam = JSONObject.parseObject(examjson, new TypeReference<Map<String, Object>>() { });
String examPath = "";
try{
//创建文件
Document document = new Document();
//设置字体
BaseFont bfChinese = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
//文件路径
examPath = path+"/exam-"+paperid;
File files = new File(examPath);
if(! files.exists() && !files.isDirectory()) { //判断目录是否存在
files.mkdir();
}
//创建PDF
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(examPath+"/test.pdf"));
// 设置页面布局
writer.setViewerPreferences(PdfWriter.PageLayoutOneColumn);
// 页码
writer.setPageEvent(new PageXofYTest());
//打开文件
document.open();
//图片1
Image image1 = Image.getInstance(pathimg+"/zy3.jpg");
//设置图片的宽度和高度
//image1.scaleAbsolute(140, 40);
//将图片1添加到pdf文件中
document.add(image1);
//标题
Paragraph paragraph = new Paragraph(150);//段落的间距
//1 2 3 中右左
paragraph.setAlignment(1); //对齐方式
Font font = new Font(bfChinese);//字体
font.setSize(22);//字体大小
paragraph.setFont(font);//设置段落字体
Chunk chunk = new Chunk("Test");
paragraph.add(chunk);
document.add(paragraph);
Paragraph paragraph1 = new Paragraph(40);
//1 2 3 中右左
paragraph1.setAlignment(1); //对齐方式
Font font1 = new Font(bfChinese);//字体
font1.setSize(20);
paragraph1.setFont(font1);
Chunk chunk1 = new Chunk("Test1");
paragraph1.add(chunk1);
//paragraph1.setSpacingBefore(-15);
//paragraph1.setSpacingAfter(-50);//往下距离200
document.add(paragraph1);
//点线
DottedLineSeparator line = new DottedLineSeparator();
//下移5个单位
line.setOffset(-15);
//设置点之间的距离
//line.setGap(20);
document.add(line);
Paragraph paragraph3 = new Paragraph(150);
//1 2 3 中右左
paragraph3.setAlignment(1); //对齐方式
Font font3 = new Font(bfChinese);//字体
font3.setSize(12);
paragraph3.setFont(font3);
Chunk chunk3 = new Chunk("编号:"+getRandom(17));
paragraph3.add(chunk3);
paragraph3.setSpacingAfter(5);
document.add(paragraph3);
Paragraph paragraph4 = new Paragraph(15);
//1 2 3 中右左
paragraph4.setAlignment(1); //对齐方式
Font font4 = new Font(bfChinese);//字体
font4.setSize(12);
paragraph4.setFont(font4);
SimpleDateFormat df = new SimpleDateFormat("yyyy年MM月dd日");
Chunk chunk4 = new Chunk("文档生成日期:"+df.format(System.currentTimeMillis()));
paragraph4.add(chunk4);
paragraph4.setSpacingAfter(5);
document.add(paragraph4);
document.newPage(); //换页
Paragraph answerPar = new Paragraph(20); //标准答案
answerPar.setAlignment(3); //对齐方式
Font answerfont = new Font(bfChinese);//字体
answerfont.setSize(12);
answerPar.setFont(answerfont);
Chunk answerchunk = new Chunk(examjson);
answerPar.add(answerchunk);
answerPar.setSpacingAfter(5);
document.add(answerPar);
//关闭文档
document.close();
//关闭书写器
writer.close();
}catch(Exception e){
e.printStackTrace();
}
ZIPUtil.compress(examPath,path+"/exam-"+paperid+".zip" ); //压缩
return "ok";
}
调用方法后生成文件夹及压缩文件
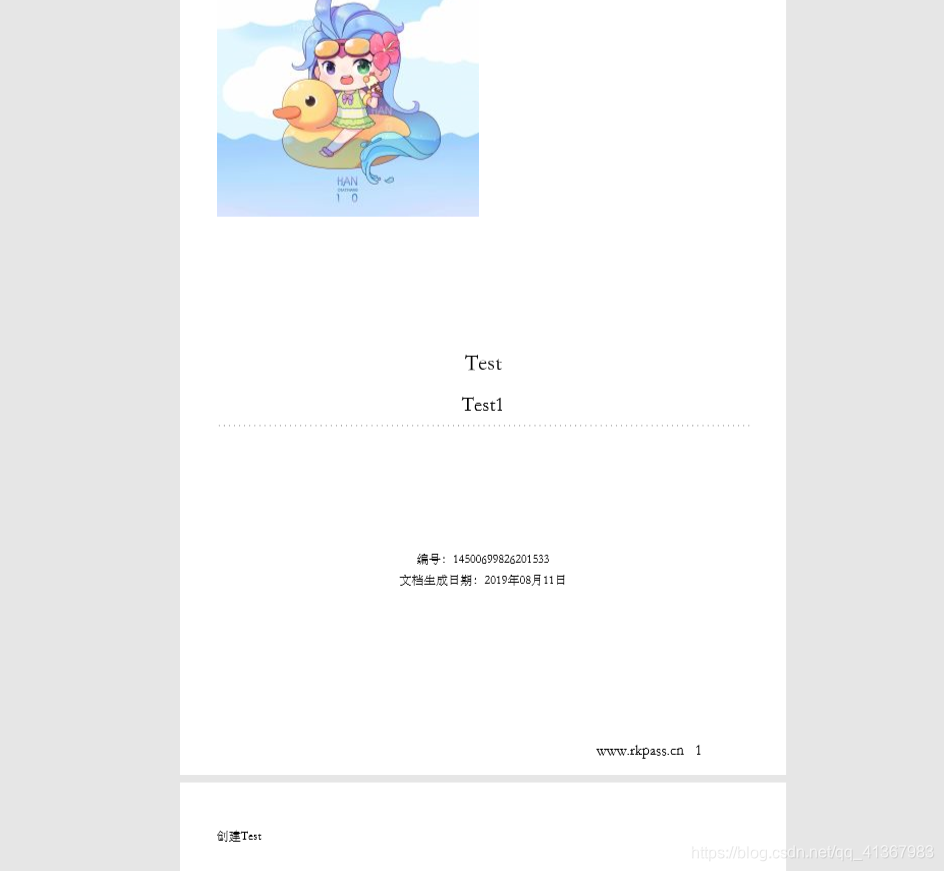
pdf效果如下:
生成指定位数的随机数
/**
* 生成指定位数的随机数
* @param length
* @return
*/
public static String getRandom(int length){
String val = "";
Random random = new Random();
for (int i = 0; i < length; i++) {
val += String.valueOf(random.nextInt(10));
}
return val;
}
页码
参考https://www.cnblogs.com/lyb0103/p/10218039.html
效果: 当前页/总页数,我进行了简单的修改,只显示当前页。
//页码事件
private static class PageXofYTest extends PdfPageEventHelper{
public PdfTemplate total;
public BaseFont bfChinese;
/**
* 重写PdfPageEventHelper中的onOpenDocument方法
*/
@Override
public void onOpenDocument(PdfWriter writer, Document document) {
// 得到文档的内容并为该内容新建一个模板
total = writer.getDirectContent().createTemplate(500, 500);
try {
String prefixFont = "";
String os = System.getProperties().getProperty("os.name");
if(os.startsWith("win") || os.startsWith("Win")){
prefixFont = "C:\\Windows\\Fonts" + File.separator;
}else {
prefixFont = "/usr/share/fonts/chinese" + File.separator;
}
// 设置字体对象为Windows系统默认的字体
//bfChinese = BaseFont.createFont(prefixFont + "simsun.ttc,0", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
bfChinese = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
} catch (Exception e) {
throw new ExceptionConverter(e);
}
}
/**
* 重写PdfPageEventHelper中的onEndPage方法
*/
@Override
public void onEndPage(PdfWriter writer, Document document) {
// 新建获得用户页面文本和图片内容位置的对象
PdfContentByte pdfContentByte = writer.getDirectContent();
// 保存图形状态
pdfContentByte.saveState();
String text ="www.rkpass.cn "+ writer.getPageNumber();
// 获取点字符串的宽度
float textSize = bfChinese.getWidthPoint(text, 15);
pdfContentByte.beginText();
// 设置随后的文本内容写作的字体和字号
pdfContentByte.setFontAndSize(bfChinese, 15);
// 定位'X/'
//System.out.println(document.right() +"...."+ document.left());
// float x = (document.right() + document.left())/2;
float x = (document.right()-150f);
float y = 20f;
pdfContentByte.setTextMatrix(x, y);
pdfContentByte.showText(text);
pdfContentByte.endText();
// 将模板加入到内容(content)中- // 定位'Y'
pdfContentByte.addTemplate(total, x + textSize, y);
pdfContentByte.restoreState();
}
/**
* 重写PdfPageEventHelper中的onCloseDocument方法
*/
/* @Override
public void onCloseDocument(PdfWriter writer, Document document) {
total.beginText();
try {
String prefixFont = "";
String os = System.getProperties().getProperty("os.name");
if(os.startsWith("win") || os.startsWith("Win")){
prefixFont = "C:\\Windows\\Fonts" + File.separator;
}else {
prefixFont = "/usr/share/fonts/chinese" + File.separator;
}
bfChinese = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
total.setFontAndSize(bfChinese, 15);
} catch (DocumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
total.setTextMatrix(0, 0);
// 设置总页数的值到模板上,并应用到每个界面
total.showText(String.valueOf(writer.getPageNumber() - 1));
total.endText();
}*/
}
压缩
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class ZIPUtil {
private static Logger logger = LoggerFactory.getLogger(ZIPUtil.class);
/**s
* 压缩文件
* @param srcFilePath 压缩源路径
* @param destFilePath 压缩目的路径
*/
public static void compress(String srcFilePath, String destFilePath) {
//
File src = new File(srcFilePath);
if (!src.exists()) {
throw new RuntimeException(srcFilePath + "不存在");
}
File zipFile = new File(destFilePath);
try {
FileOutputStream fos = new FileOutputStream(zipFile);
ZipOutputStream zos = new ZipOutputStream(fos);
String baseDir = "";
compressbyType(src, zos, baseDir);
zos.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 按照原路径的类型就行压缩。文件路径直接把文件压缩,
* @param src
* @param zos
* @param baseDir
*/
private static void compressbyType(File src, ZipOutputStream zos,String baseDir) {
if (!src.exists())
return;
logger.info("压缩路径" + baseDir + src.getName());
//判断文件是否是文件,如果是文件调用compressFile方法,如果是路径,则调用compressDir方法;
if (src.isFile()) {
//src是文件,调用此方法
compressFile(src, zos, baseDir);
} else if (src.isDirectory()) {
//src是文件夹,调用此方法
compressDir(src, zos, baseDir);
}
}
/**
* 压缩文件
*/
private static void compressFile(File file, ZipOutputStream zos,String baseDir) {
if (!file.exists())
return;
try {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file));
ZipEntry entry = new ZipEntry(baseDir + file.getName());
zos.putNextEntry(entry);
int count;
byte[] buf = new byte[1024];
while ((count = bis.read(buf)) != -1) {
zos.write(buf, 0, count);
}
bis.close();
} catch (Exception e) {
// TODO: handle exception
}
}
/**
* 压缩文件夹
*/
private static void compressDir(File dir, ZipOutputStream zos,String baseDir) {
if (!dir.exists())
return;
File[] files = dir.listFiles();
if(files.length == 0){
try {
zos.putNextEntry(new ZipEntry(baseDir + dir.getName()+File.separator));
} catch (IOException e) {
e.printStackTrace();
}
}
for (File file : files) {
compressbyType(file, zos, baseDir + dir.getName() + File.separator);
}
}
}

















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









