






JUC
AQS讲一下
AQS 的全称为 AbstractQueuedSynchronizer ,翻译过来的意思就是抽象队列同步器。这个类在 java.util.concurrent.locks 包下面。
AQS支持独占锁和共享锁两种模式:
互斥锁:只能被一个线程获取到(ReentrantLock)
共享锁:可以被多个线程同时获取(CountDownLatch、ReadWriteLock)
CAS过程说一下
AQS采用了一个volatile修饰的int类型的变量state用来记录锁竞争的状态。0表示当前没有任何线程竞争锁资源,而大于等于1表示已经有线程持有锁。
一个线程来获取资源的时候,首先会判断state是否为0,也就是说它是否为无锁状态,如果是则把state更新成1表示占有到锁。AQS采用了CAS机制保证state互斥变量更新的原子性。未获得锁的线程通过UnSafe类的park方法去进行阻塞,把阻塞的线程按照先进先出的原则去加入到一个双向链表的结构中。当获得锁资源的线程释放锁之后,会从这样一个双线链表的头部去唤醒下一个等待的线程再去竞争锁。
关于锁竞争的公平性和非公平性的问题,AQS的处理方式是:在竞争锁资源时候,公平锁需要去判断双向链表中否有阻塞的线程,如果有则需要去排队等待。而非公平锁的处理方式是:不管双向链表中是否存在等待竞争锁的线程,那么它都会直接去尝试更改互斥变量state去竞争锁。
锁的释放如何唤醒线程
正常公平锁会唤醒队列中头节点后的第一个线程
可重入怎么判断?
可重入锁在对象头中会存储当前线程的id,如果这个线程id和当前线程的id一致则可重入
相关问题
- 如果锁释放掉,正常公平锁会唤醒队列中头节点后的第一个线程,但此时第一个线程被cancell,应该如何唤醒线程?
会从尾部节点往前找线程去唤醒第一个非cancelled状态的线程。
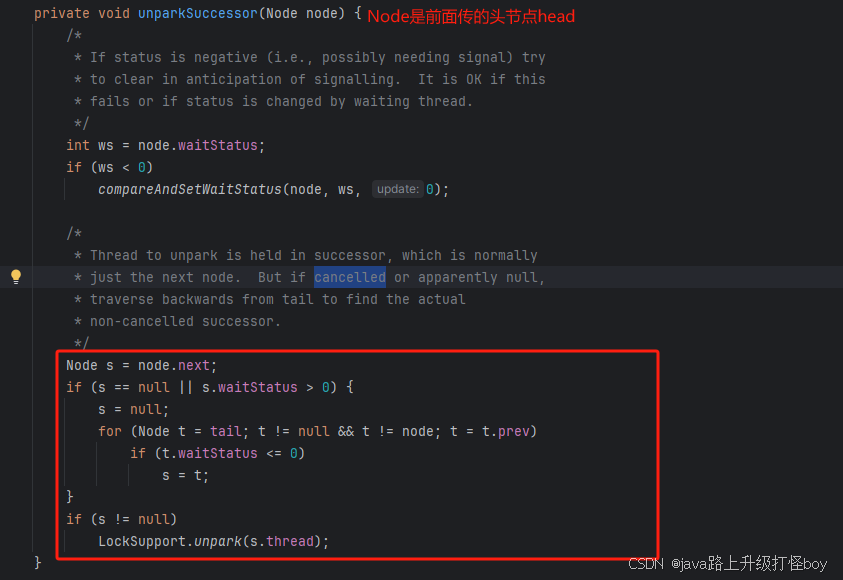
- 为什么要从尾部往前找而不是从前往后找呢?
在往队列中插入时,addWait()在并发情况下可能会造成next为null,但是prev肯定是有的。
在将节点加入队列的时候,先连接的pre,之后CAS成功后再连接next,所以pre成功连接,并不能保证节点已经加入到队列,只有next连接成功,才能说明节点成功加入队列。所以如果从前往后,取得的节点可能还没有成功连接到队列。
private Node addWaiter(Node mode) {
//用当前线程创建一个新的Node节点
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
//这里判断tail不等于null。说明队列中已经有等待的线程了,直接尝试将当前线程往队列末尾追加
if (pred != null) {
//这里追加的时候,先将新创建的节点的pre连接到队列上。
node.prev = pred;
//通过CAS替换tail,替换成功,则将队列尾节点的next指向新节点,说明加入队列成功
//如果这里替换失败,说明有其他现成因为获取锁失败了并且正在加入到队列,并且先加入成功了。
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
//队列中没有等待线程,或者加入队列失败了,都会执行enq方法
enq(node);
return node;
}
更细节的点可以看这篇文章:ReentrantLock源码分析
- 为什么要使用双向链表?
双向链表有两个指针,一个指向前置节点,一个指向后继节点。所以双向链表可以支持复杂度为o(1)的情况下找到前驱节点,因此双向链表再插入和删除操作要比单向链表简单高效。
AQS使用双向链表有两方面的原因:
- 没有竞争到锁的线程加入到阻塞队列,并且阻塞等待的前提是当前线程所在节点的前置节点是正常状态,这样设计是为了避免链表存在异常线程导致无法唤醒后续线程的问题,所以,线程阻塞之前需要判断前置节点的状态,如果没有指针指向前置节点,就需要从head节点开始遍历,性能非常低。
- 在Lock接口中有一个lockInterruptibly()方法,这个方法表示处于锁阻塞的线程允许被中断。也就是说没有竞争到锁的线程加入到同步队列中等待以后,是允许外部线程通过interrupt()方法触发唤醒并中断的,此时,被中断的线程状态会修改为cancelled,而被标记为cancelled的线程是不需要去竞争锁的,但它还在同步队列中,这就意味着在后续的锁竞争中,需要把这个节点从链表中移除,否则会导致锁阻塞的线程无法被正确唤醒,在这种情况下,如果是单向链表,就需要从head节点开始逐个遍历,找到并移除异常状态的节点,效率低还会造成锁唤醒的操作和遍历操作之间的竞争。
-
Condition 和 AQS 有什么关系?
Condition 是基于 AQS 实现的,Condition 的实现类 ConditionObject 是 AQS 的一个内部类,在里面共用了一部分 AQS 的逻辑。 -
Condition 的实现原理是什么?
Condition 内部维护一个条件队列,在获取锁的情况下,线程调用 await,线程会被放置在条件队列中并被阻塞。直到调用 signal、signalAll 唤醒线程,此后线程唤醒,会放入到 AQS 的同步队列,参与争抢锁资源。 -
Condition 的等待队列和 AQS 的同步队列有什么区别和联系?
Condition 的等待队列是单向链表,AQS 的是双向链表。二者之间并没有什么明确的联系。仅仅在节点从阻塞状态被唤醒后,会从等待队列挪到同步队列中。
计算机网络
TCP的连接和释放过程
三次握手和四次挥手
为什么是四次挥手而不是三次?
原因:服务端收到客户端发送的FIN包后,可能还有没有发送完的数据,所以先回复一个ACK确认包,表示已经收到了FIN包,等服务端将剩余数据发送完毕之后再发送一个FIN包给客户端表示已经没有要发送的数据了,可以结束了连接了。所以是四次挥手而不是三次。
网络基本模型
TCP和UDP区别
- 是否连接
• TCP是面向连接的,UDP是面向无连接的 - 是否可靠
• TCP是可靠的,UDP是不可靠的 - 连接对象的个数
• TCP只支持一对一通信,而UDP支持一对一、一对多、多对一、多对多通信。 - 传输方式
• TCP是面向字节流的,UDP是面向报文的。 - 首部开销
• TCP首部开销大,最小20字节,但是UDP首部仅8字节。 - 应用场景
• TCP适用于可靠传输的场景比如支付场景,UDP适合实时应用,例如视频会议直播。
UDP讲一下
数据结构
二叉树的遍历,主要考察栈和队列
深度优先遍历
@Data
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
public TreeNode(int val) { this.val = val; }
public TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
非递归-使用栈
// 先序遍历
public static void depthFirstTravel(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur !=null || !stack.isEmpty()) {
if(cur != null) {
res.add(cur.val);
stack.push(cur);
cur = cur.left;
} else {
TreeNode node = stack.pop();
cur = node.right;
}
}
}
// 中序遍历
public static void depthSecondTravel(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()) {
if (cur != null) {
stack.push(cur);
cur = cur.left;
} else {
TreeNode node = stack.pop();
res.add(node.val);
cur = node.right;
}
}
}
// 后序遍历
public static void depthThirdTravel(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()) {
TreeNode node = null;
if (cur != null) {
stack.push(cur);
cur = cur.left;
} else {
node = stack.pop();
cur = node.right;
}
if (node != null && node.right == null) {
res.add(node.val);
} else if (node != null) {
node.setRight(null);
stack.push(node);
}
}
递归
public static void dfs(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
res.add(root.val);
dfs(root.left, res);
dfs(root.right, res);
}
广度优先遍历
非递归版
public static void breadthFirstTravel(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode cur = queue.remove();
res.add(cur.val);
if (cur.left != null) {
queue.add(cur.left);
}
if (cur.right != null) {
queue.add(cur.right);
}
}
}
递归版
// 这个要在主方法里把根节点放进去
public static void main(String[] args) {
TreeNode root = new TreeNode(1, new TreeNode(2, new TreeNode(4, null, null), new TreeNode(5, null, null)), new TreeNode(3, new TreeNode(6, null,null),null));
List<Integer> res = new ArrayList<>();
res.add(root.val);
guangdu(root, res);
System.out.println(Arrays.toString(res.toArray()));
}
public static void guangdu(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
if (root.left != null) {
res.add(root.left.val);
}
if (root.right != null) {
res.add(root.right.val);
}
guangdu(root.left, res);
guangdu(root.right, res);
}
反转链表
//非递归
public static ListNode reverse(ListNode root) {
ListNode cur = root;
ListNode pre = null;
ListNode tmp = null;
while (cur != null) {
tmp = cur;
cur = cur.next;
tmp.next = pre;
pre = tmp;
}
return tmp;
}
// 递归
public static ListNode reverse2(ListNode head) {
if(head == null || head.next == null) {
return head;
}
ListNode node = reverse2(head.next);
head.next.next = head;
head.next = null;
return node;
}
链表获取倒数第k个元素,只能遍历一次
快慢指针,快指针都末尾,慢指针指向倒数第k个。
public int kthToLast(ListNode head, int k) {
if (head == null) {
return -1;
}
ListNode slow = head;
ListNode fast = head;
int i =0;
while(fast != null) {
fast = fast.next;
if (i < k) {
i++;
} else {
slow = slow.next;
}
}
return slow.val;
}
两个链表是否有相交
说成环形链表的思路了,哭死…
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode a = headA, b = headB;
while(a != b) {
a = a == null ? headB : a.next;
b = b == null ? headA : b.next;
}
return a;
}
判断环形链表,快慢指针
public ListNode detectCycle(ListNode head) {
if(head == null || head.next == null) {
return null;
}
ListNode fast = head, slow = head;
while(fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if(slow == fast) {
break;
}
}
if (slow != fast) return null;
fast = head;
while(slow != fast){
fast = fast.next;
slow = slow.next;
}
return slow; // return fast也可以
}
JVM
java内存模型
Java 内存模型和 Java 的并发编程相关,抽象了线程和主内存之间的关系就比如说线程之间的共享变量必须存储在主内存中,规定了从 Java 源代码到 CPU 可执行指令的这个转化过程要遵守哪些和并发相关的原则和规范,其主要目的是为了简化多线程编程,增强程序可移植性的。
给了一段日志,问有没有见过,大概是这个
2022-01-11T17:51:35.992-0800: 47.713: [GC (Allocation Failure) [PSYoungGen: 1280509K->89599K(1308160K)] 1396384K->217194K(1509376K), 0.0251936 secs] [Times: user=0.08 sys=0.01, real=0.02 secs]
打印如上日志要家的启动参数
‐Xloggc:./gc‐%t.log ‐XX:+PrintGCDetails ‐XX:+PrintGCDateStamps ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCCause ‐XX:+UseGCLogFileRotation ‐XX:NumberOfGCLogFiles=10 ‐XX:GCLogFileSize=100M
- ‐Xloggc参数:指定gc日志的保存地址。这里指定的是当前目录,文件名以gc-+时间戳.log打印。%t表示时间戳
- ‐XX:+PrintGCDetails:在日志中打印GC详情。
- ‐XX:+PrintGCDateStamps:在日志中打印GC的时间
- ‐XX:+PrintGCTimeStamps:在日志中打印GC耗时
- ‐XX:+PrintGCCause : [这个参数没查到]
- ‐XX:+UseGCLogFileRotation:这个参数表示以滚动文件的形式打印日志
- ‐XX:NumberOfGCLogFiles:GC日志文件的最大个数,这里设置10个
- ‐XX:GCLogFileSize:GC日志每个文件的最大容量,这里是100M
日志内容:
- 2022-01-11T17:51:35.992-0800:能够打印这个时间是因为设置了‐XX:+PrintGCDateStamps参数。打印日志输出的时间
- 47.713:从jvm启动直到垃圾收集发生所经历的时间。这个时间是因为设置了‐XX:+PrintGCTimeStamps参数
- GC:表示这是一次Minor GC(新生代垃圾收集);
- (Allocation Failure):触发GC的原因是,给Young Gen内存分配失败导致的
- [PSYoungGen: 1280509K->89599K(1308160K)] 提供了新生代空间的信息,PSYoungGen,表示新生代使用的是多线程垃圾收集器Parallel Scavenge。1280509K表示垃圾收集之前新生代占用空间,89599K表示垃圾收集之后新生代的空间。括号里的1308160K表示整个年轻代的大小。
- 新生代又细分为一个Eden区和两个Survivor区, Minor GC之后Eden区为空,6577K就是Survivor占用的空间。
- 1396384K->217194K(1509376K)
1396384K:表示垃圾收集之前Java堆占用的大小,217194K:表示垃圾收集之后Java堆占用的大小,1509376K:总堆大小1509376K,包括新生代和年老代 - 0.0251936 secs:表示垃圾收集过程所消耗的时间。
- [Times: user=0.08 sys=0.01, real=0.02 secs]:提供cpu使用及时间消耗
- user是用户模式垃圾收集消耗的cpu时间,实例中垃圾收集器消耗了0.08秒用户态cpu时间
- sys是消耗系统态cpu时间
- real是指垃圾收集器消耗的实际时间
- 由新生代和Java堆占用大小可以算出年老代占用空间,
- Java堆空间总大小1509376K,新生代空间总大小1308160K,那么老年代空间总大小是1509376K-1308160K=201216K;
- 垃圾收集之前老年代占用的空间为1396384K-1280509K=115875K
- 垃圾收集之后老年代占用空间217194K-89599K=127595k.
Spring
bean的管理
Spring IOC容器的加载流程
Spring IOC容器的加载过程包括以下几个关键步骤:
-
定义Bean
首先需要定义要被IOC容器管理的Java对象,即Bean。通过@Component 等注解或者xml配置来实现。 -
加载配置文件
从xml配置中获取元数据信息, BeanDefinationReader的作用就是加载配置元信息,并将其转化为内存形式的BeanDefination。 -
注册BeanDefinition
将BeanDefination注册到BeanDefinationRegistry中,BeanDefinationRegistry就是一个存放BeanDefination的大篮子,它也是一种键值对的形式,通过特定的Bean定义的id,映射到相应的BeanDefination。 -
加载bean
spring主要通过BeanFactory接口的getBean方法来从IOC容器,即BeanFactory的实现类中获取某个bean对象实例,如果获取不到就调用createBean()方法实例化 bean -
实例化Bean
容器在加载配置文件后,会根据配置信息实例化每个Bean。这包括创建对象、设置属性值等。这个涉及到bean的生命周期。

-
依赖注入
最后,容器会将Bean之间的依赖关系注入到它们之中。这可以通过构造函数注入、setter方法注入或字段注入来实现
一个接口多个实现类或者autowird注入bean,是通过什么方式去区分的呢
这个问题应该是回答三级缓存吧,先从一级缓存获取已初始化好的bean,从ConcurrentHashMap的容器map通过beanName获取。(不太确定是不是从这个角度回答)
Resource byName 通过getBean(String beanName);
Autowired 先byType 通过getBean(Class type);
然后getBean的时候会去一二三级缓存中获取
Mysql
B+树索引介绍,和B树的区别
淘宝地址怎么建创建索引
Redis
缓存穿透和缓存击穿介绍和处理
击穿除了分布式锁的缓存预热还有什么办法
redis分布式锁,redissionClient.tryLock底层介绍
看这篇:Redisson分布式锁底层原理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









