




 本文探讨了网络爬虫的两大类型:通用爬虫与聚焦爬虫,详细讲解了它们的工作原理、抓取流程及限制。并通过实际案例,演示了Python爬虫的编写过程,包括需求分析、代码实现及反爬虫策略。
本文探讨了网络爬虫的两大类型:通用爬虫与聚焦爬虫,详细讲解了它们的工作原理、抓取流程及限制。并通过实际案例,演示了Python爬虫的编写过程,包括需求分析、代码实现及反爬虫策略。
通用爬虫和聚焦爬虫
根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种。
通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网 页下载到本地,形成一个互联网内容的镜像备份。通用网络爬虫从互联网中搜集网页,采集信息,这些网页信息用于为搜索引擎建立索引从而提供支持,它决定着 整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页 抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
爬虫基本工作流程图
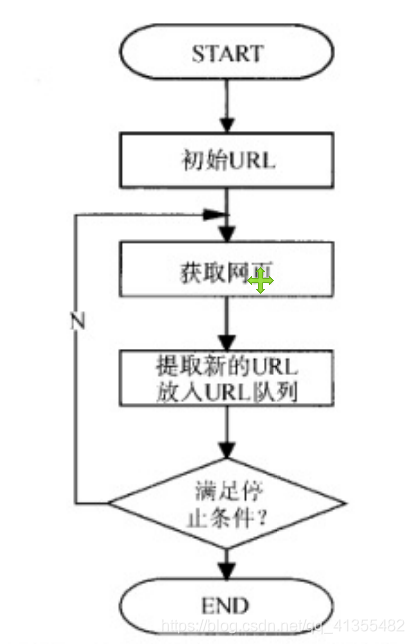
网络爬虫抓取过程可以理解为模拟浏览器操作的过程。
搜索引擎如何获取一个新网站的URL:
1. 新网站向搜索引擎主动提交网址:
2. 在其他网站上设置新网站外链
3. 和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
爬虫限制
搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容。
1. rel=“nofollow”,,告诉搜索引擎爬虫无需抓取目标页,同时告诉搜索引擎无需将的当前页的Pagerank传递到目标页.
2. Robots协议(也叫爬虫协议、机器人协议等),全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
局限性
1.大多情况下,网页里90%的内容对用户来说都是无用的。
2. 搜索引擎无法提供针对具体某个用户的搜索结果。
3. 图片、数据库、音频、视频多媒体等不能很好地发现和获取。
4. 基于关键字的检索,难以支持根据语义信息提出的查询,无法准确理解用户的具体需求。
URL(Uniform/UniversalResourceLocator的缩写):统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
客户端HTTP请求
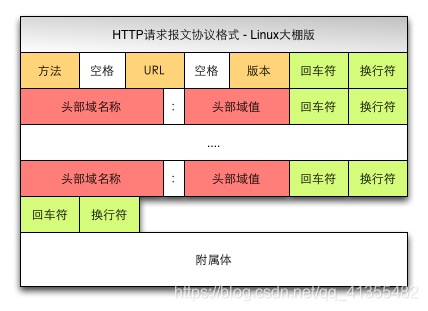
根据HTTP标准,HTTP请求可以使用多种请求方法.
HTTP0.9:只有基本的文本GET功能。
HTTP1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法:GET,POST和HEAD方法。
HTTP1.1:在1.0基础上进行更新,新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE和CONNECT方法。
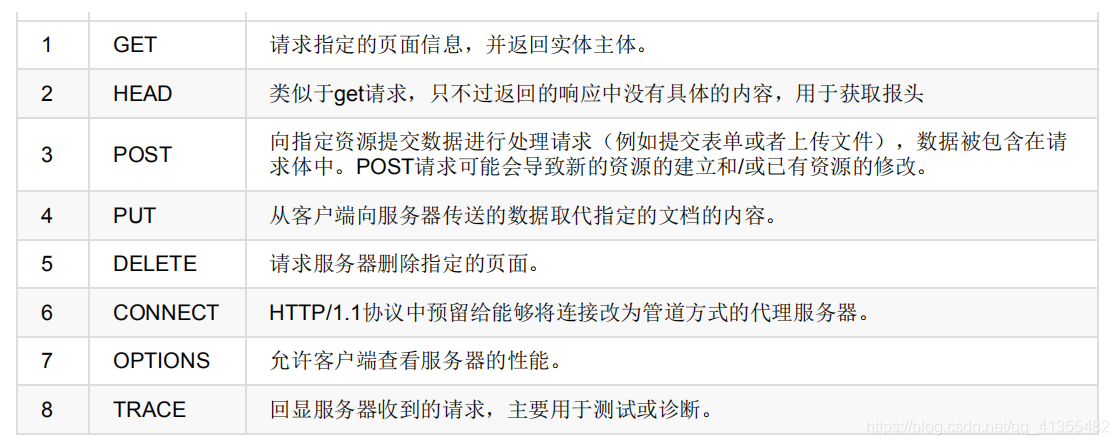
Get 和 Post 详解
- GET是从服务器上获取数据,POST是向服务器传送数据
- GET请求参数显示,都显示在浏览器网址上,即“Get”请求的参数是URL的一部分。
- POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码。
HTTP响应
HTTP响应由四个部分组成,分别是: 状态行 、 消息报头 、 空行 、 响应正文
响应状态码:
200: 请求成功
302: 请求页面临时转移至新url
307和304: 使用缓存资源
404: 服务器无法找到请求页面
403: 服务器拒绝访问,权限不够
500: 服务器遇到不可预知的情况
Cookie和Session
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在客户端记录的信息确定用户的身份。
Session:通过在服务器端记录的信息确定用户的身份。
案例:图片下载器。
首先要明确爬虫的基本步骤:
- 需求分析
- 分析网页源代码,配合F12
- 编写正则表达式或者其他解析器代码
- 正式编写python爬虫代码
需求分析:"我想要图片,我又不想上网搜“,“最好还能自动下载”。这就是需求。至少要实现两个功能,一是搜索图片,二是自动下载。
实现代码如下:
"""
Date: 2019--07 10:29
User: yz
Email: 1147570523@qq.com
Desc:
"""
"""
图片批量下载器
"""
import os
import requests
import re
def downloadPic(html,keyword):
pic_url=re.findall('"objURL":"(.*?)",',html,re.S)[:20]
count =0
print("找到关键字:"+keyword+'的图片,开始下载。')
for each in pic_url:
print("正在下载第"+str(count+1)+'张图片,图片地址:'+str(each))
try:
headers={
'User-Agent':"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
}
pic=requests.get(each,timeout=10,headers=headers)
except requests.exceptions.ConnectionError:
print("【错误】当前图片无法下载")
count+=1
continue
except Exception as e:
print("当前图片无法下载")
print(e)
continue
else:
if pic.status_code!=200:
print("请求失败!")
continue
if not os.path.exists(imgDir):
print("正在创建目录",imgDir)
os.makedirs(imgDir)
posix=each.split(".")[-1]
if posix not in ['png','jpg','gif','jpeg']:
break
name=keyword+'_'+str(count)+'.'+posix
filename=os.path.join(imgDir,name)
count+=1
with open(filename,'wb') as f:
f.write(pic.content)
if __name__ == '__main__':
imgDir='pictures'
word=input("Input key word:")
url="http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word="+word
try:
result=requests.get(url)
except Exception as e:
print(e)
content=''
else:
content=result.text
downloadPic(content,word)
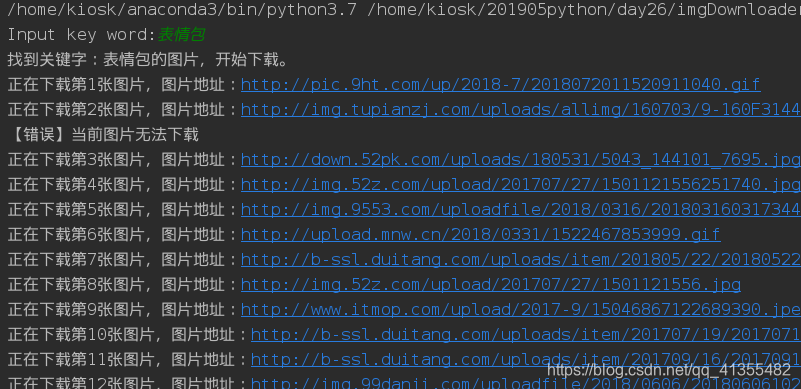
当然我们的文件夹里就有了我们的想要的图片了。

我们主要做爬中主要有两个模块。urllib和requests。
让然有些网页是不支持爬虫的,所以我们需要有相应的反爬虫方法。
urllib的第一种方式:
浏览器的模拟
应用场景:有些网页为了防止别人恶意采集其信息所以进行了一些反爬虫的设置,而我们又想进行爬取。
解决方法:设置一些Headers信息(User-Agent),模拟成浏览器去访问这些网站。
实现代码:
"""
Date: 2019--07 15:41
User: yz
Email: 1147570523@qq.com
Desc:
"""
from urllib import request
from urllib import error
from urllib import parse
try:
url = 'http://www.baidu.com:80'
obj = parse.urlparse(url)
headers = {
'User-Agent':"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
}
# 实例化请求对象, 修改请求的头部信息;
requestObj = request.Request(url, headers=headers)
response = request.urlopen(requestObj)
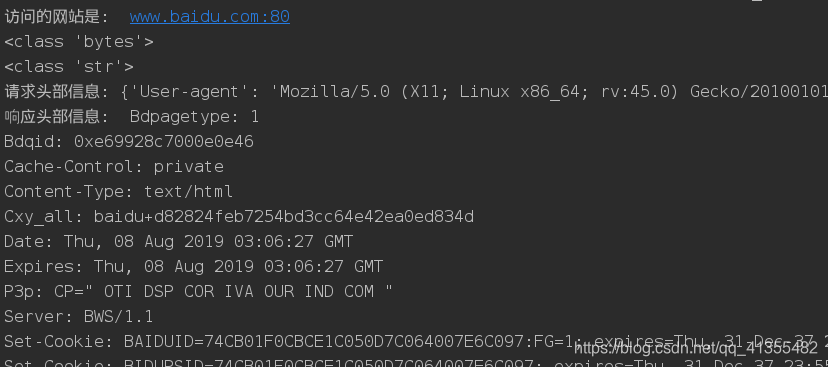
print("访问的网站是: ", obj.netloc)
except error.HTTPError as e:
print(e.code, e.reason, e.headers)
except error.URLError as e:
print(e.reason)
else:
bytes_content = response.read()
print(type(bytes_content))
str_content = bytes_content.decode('utf-8')
print(type(str_content))
print("请求头部信息:", requestObj.headers)
print("响应头部信息: ", response.headers)
print("响应的状态码: ", response.code)
当然我们还有第二种方式requests模块的。
代理服务器的设置
**应用场景:**使用同一个IP去爬取同一个网站上的网页,久了之后会被该网站服务器屏蔽。
**解决方法:**使用代理服务器。(使用代理服务器去爬取某个网站的内容的时候,在对方的网站上,显示的不是我们真实的IP地址,而是代理服务器的IP地址)
和第一种方法类似。实现如下:
"""
Date: 2019--07 15:35
User: yz
Email: 1147570523@qq.com
Desc:
"""
import requests
import random
proxies=[
{'HTTPS': '163.204.247.157:9999'},
{'HTTP': '163.204.246.39:9999'},
{'http':"163.204.246.39:8080"}
]
headers={
'User-Agent':"Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"
}
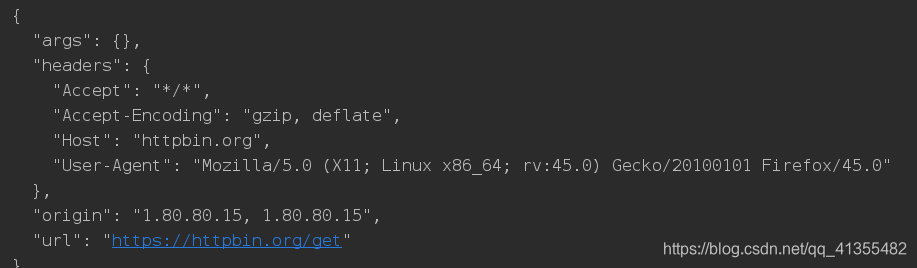
url='http://httpbin.org/get'
respose=requests.get(url,headers=headers,proxies=random.choice(proxies))
print(respose.text)

















 4132
4132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









