







 本文深入介绍了循环神经网络(RNN),包括其基本结构、在语言建模、图像描述、视觉问答等领域的应用。特别讨论了多层RNN和改进的结构,如LSTM和GRU,以及它们如何解决梯度消失问题。
本文深入介绍了循环神经网络(RNN),包括其基本结构、在语言建模、图像描述、视觉问答等领域的应用。特别讨论了多层RNN和改进的结构,如LSTM和GRU,以及它们如何解决梯度消失问题。
文章目录
课堂提问
- 问: RNN中某些层的激活函数为什么使用tanh?
1. 引入
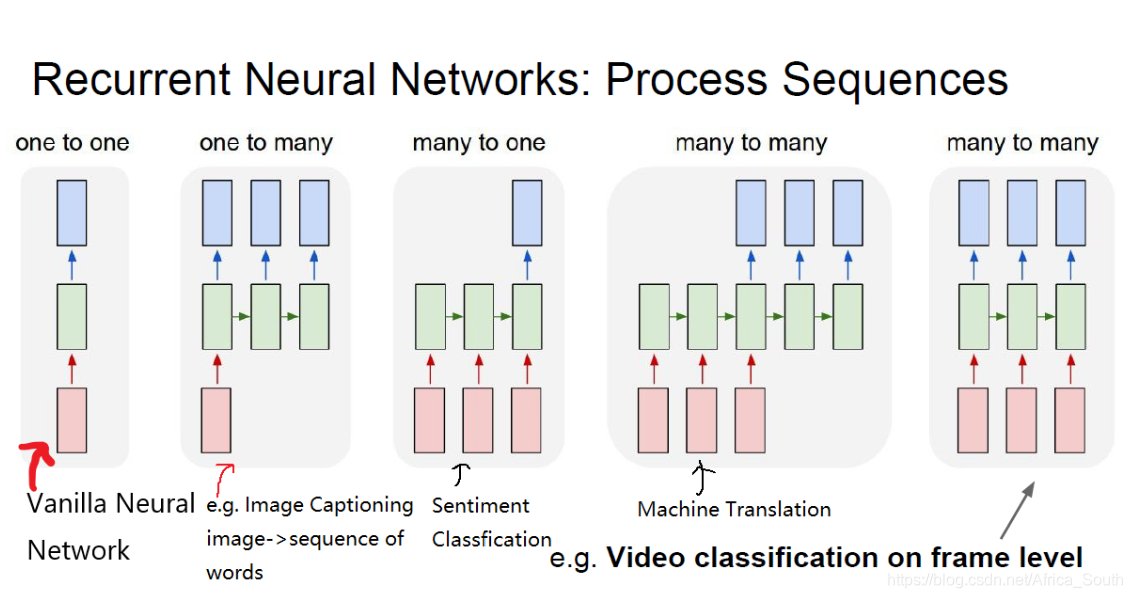
普通神经网络和循环神经网络的对比如下,他可以是多输入多输出的:
序列化
如果我们输入的数据不是像上图所示的是一个序列的,则我们需要将数据序列化。
例如我们要分类一张手写体图像,我们的输入不是整张图像,而是在图像上采样不同的子区域,然后使用RNN来进行分类:

基本结构
RNN的基本单元如下图右侧所示:
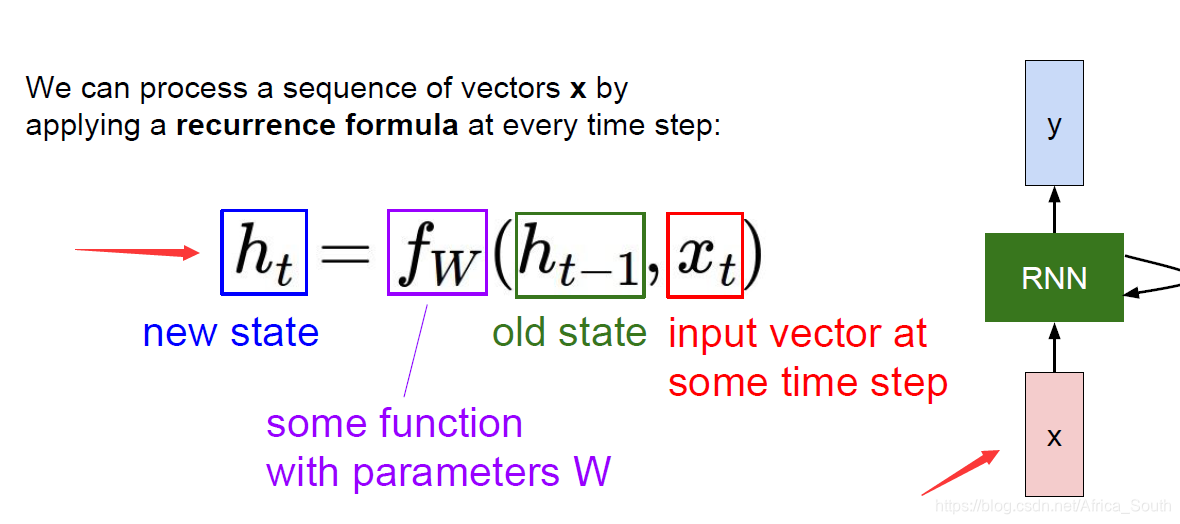
- 其每次接收到当前输入的X,然后将其计算后存储在中间隐藏状态(internal hidden state),并将结果按照某种方式反馈给模型,最后得出输出Y
- 上述过程被形式的描述成左侧公式(注意我们每一步产生输出都是使用相同的W和 f W f_W fW)
举个例子,一个简单的RNN单元如下图:其接收输入、更新隐藏状态、产生输出:
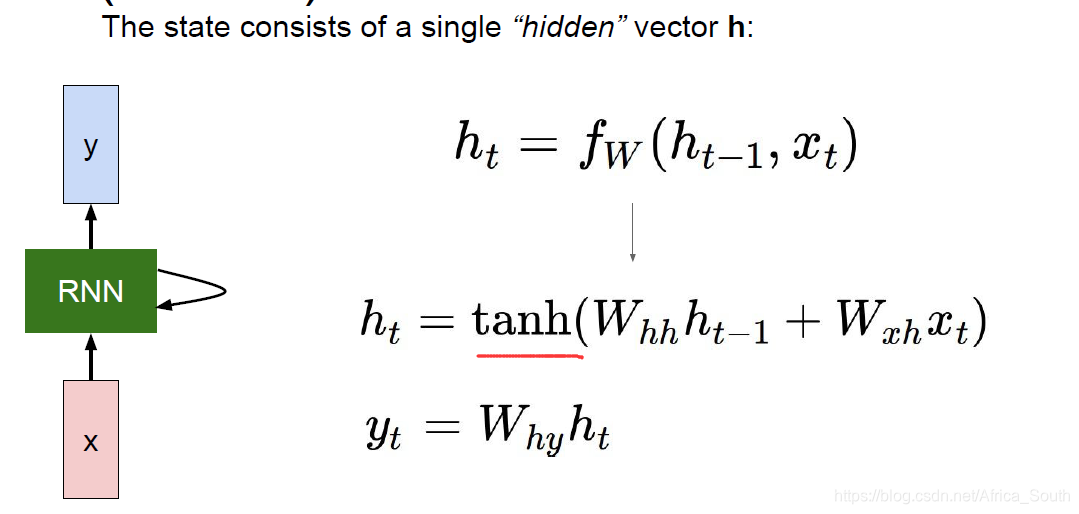
将其 计算图 展开我们能得到下图:
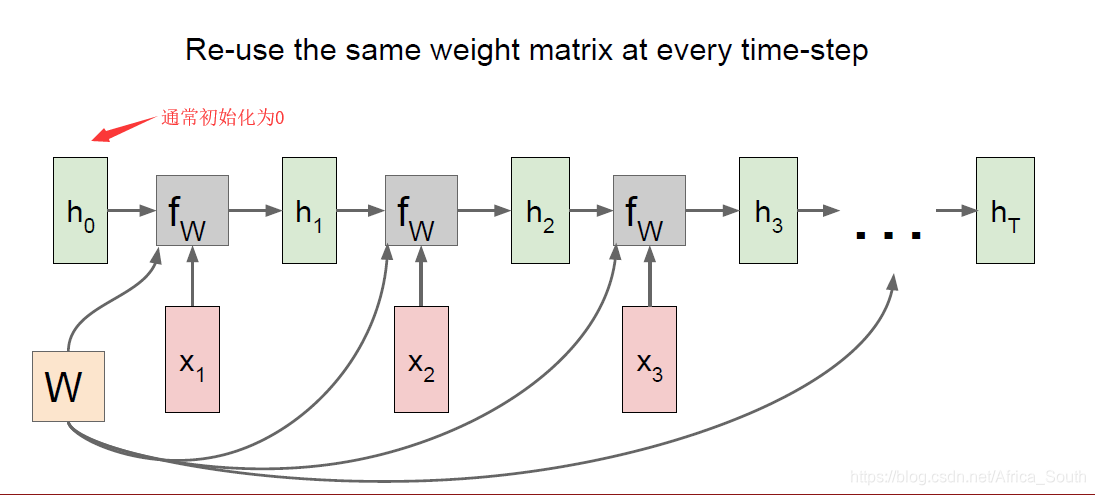
可以看到,我们每个时刻的状态不仅与当前输入有关,而且还与之前的输入有关。如果,我们每个时间点都产生一个输出,则有下面的计算图:
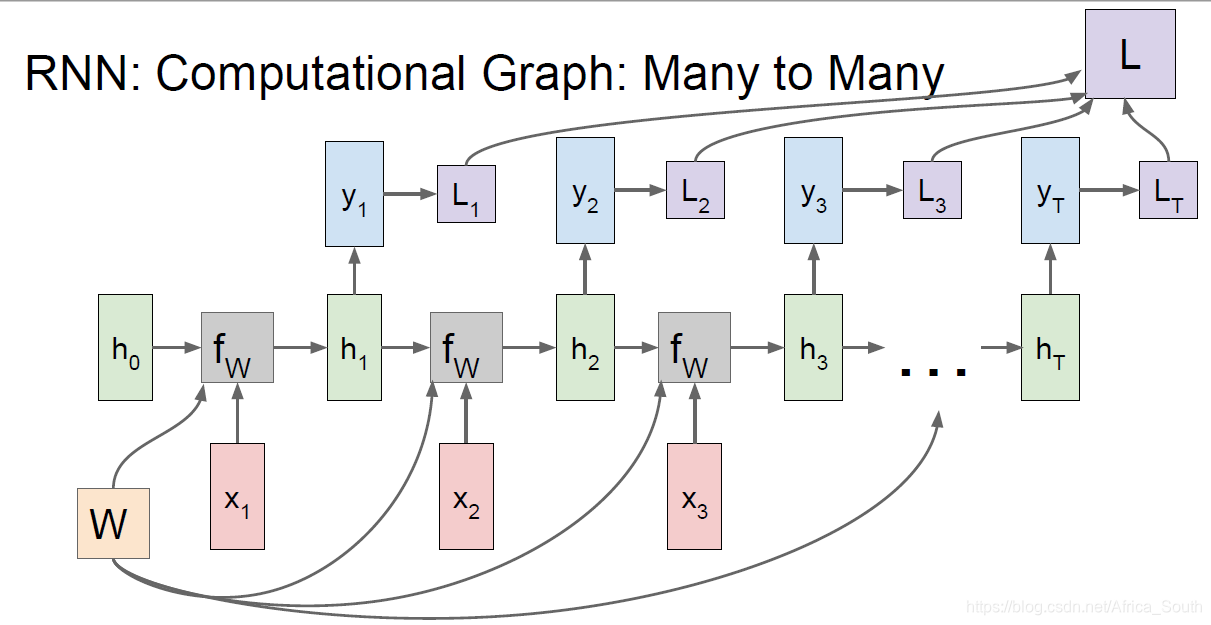
同样的,一对多,多对一的过程与上图类似,例如我们在机器翻译中,最常见的做法是:接收不定长的输入,然后编码(encode)到一个隐藏状态,最后再解码(decode)产生多个输出:
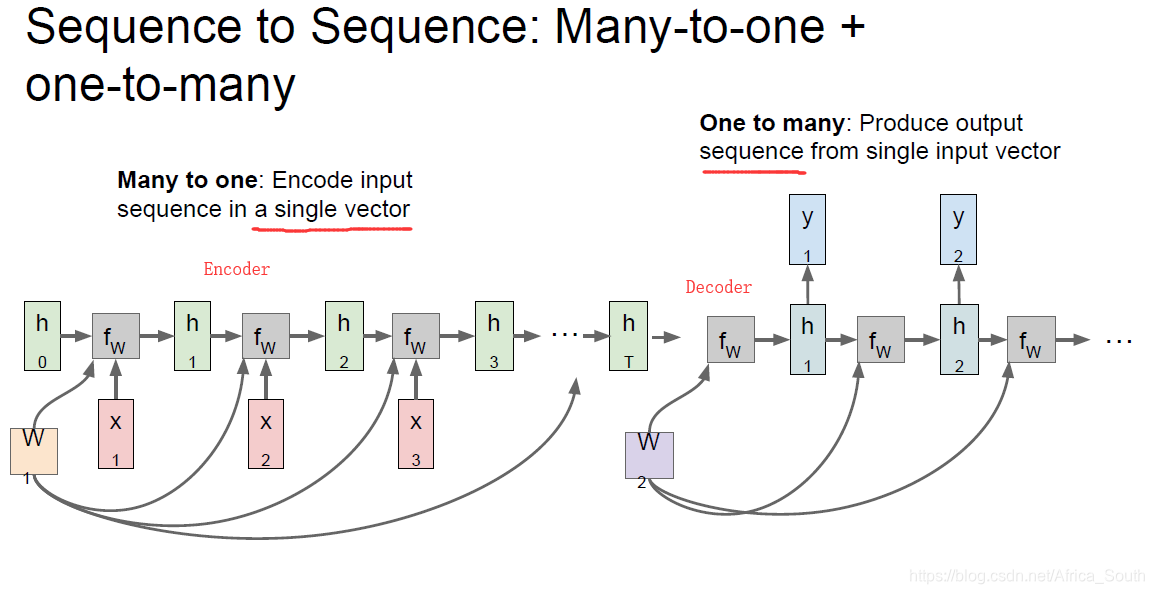
则我们在反向传播时,所有时序步都有梯度反向传播到共享权重W
2. 语言建模
RNN常见的应用就是语言建模,例如输入一串字符或者单词,然后预测下一个字符和单词:
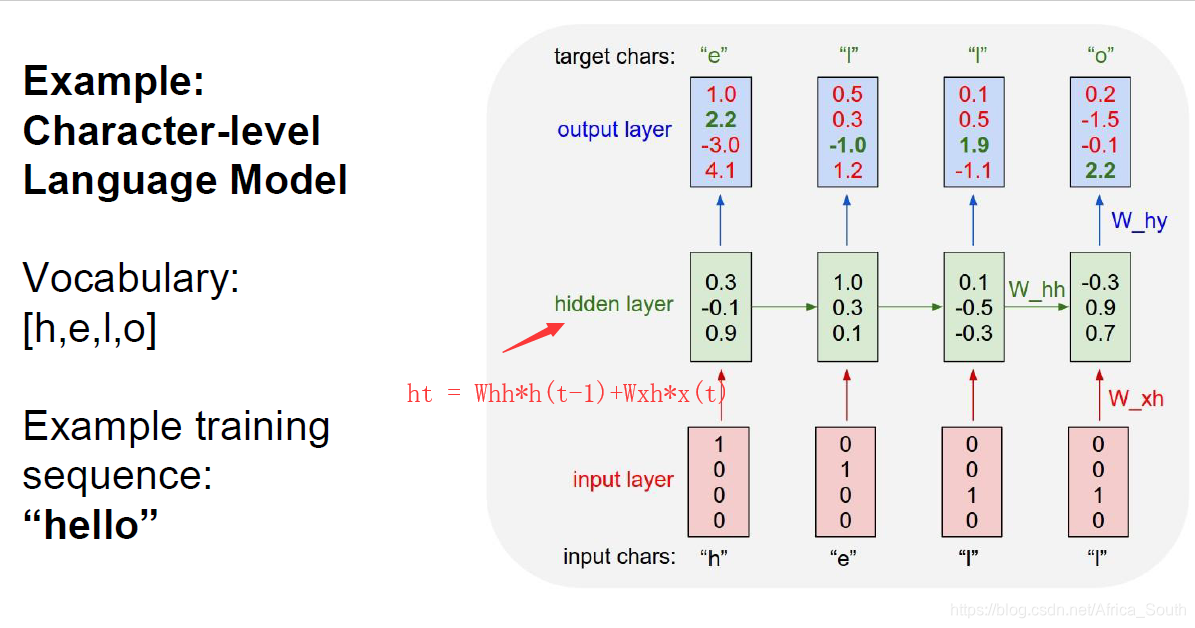
在训练的时候,我们每次输入一个字符,然后输出其可能的下一字符,并会进行一系列输入和输出。(因为我们输入的是一个字符串来作为训练)
在 测试的时候,我们会输入一个字符,然后不断地将其输出当成后续的输入:
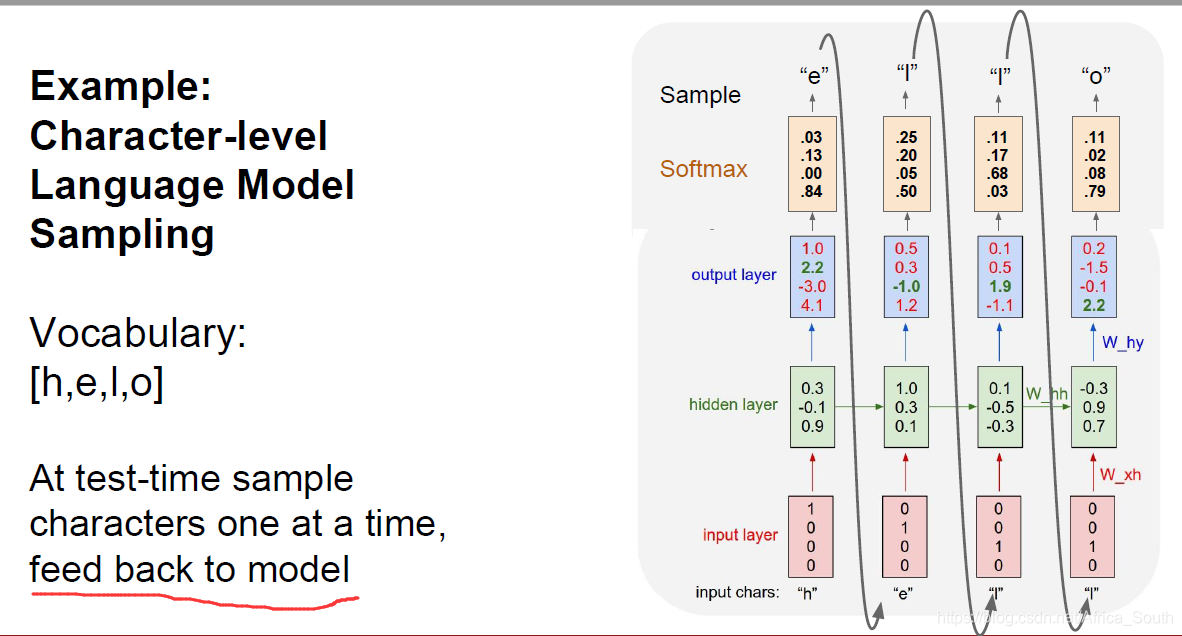
Q: 为什么将其输出还要继续输入,而不是直接输出一个得分最高的字母?
A: 因为有时候我们的任务是一对多的。(例如,我们后面将的Image Caption)。
Q: 为什么不将Softmax的输出直接当下一次的输入,而是转换成字符的特征表示?
A:
- 1.和训练阶段所使用的数据不一致;
- 2.我们的词库可能很大,所以我们需要用稀疏的One-hot编码来表示一个字符或者单词,否则Softmax的输出可能会出现很多位置都很接近的情况 。
但是,上述形式还会产生其它问题:
例如,我们在前向传播的时候是按照时序进行的,所以反向传播需要按照时序逆行(因为当前隐藏状态受之前隐藏状态的影响)。但是,当我们的输入序列长度很长的时候,反向传播将会比较麻烦。
所以,一般我们采用子序列截断的方法:即前向传播若干步,然后计算一次损失进行反向传播,依此类推。
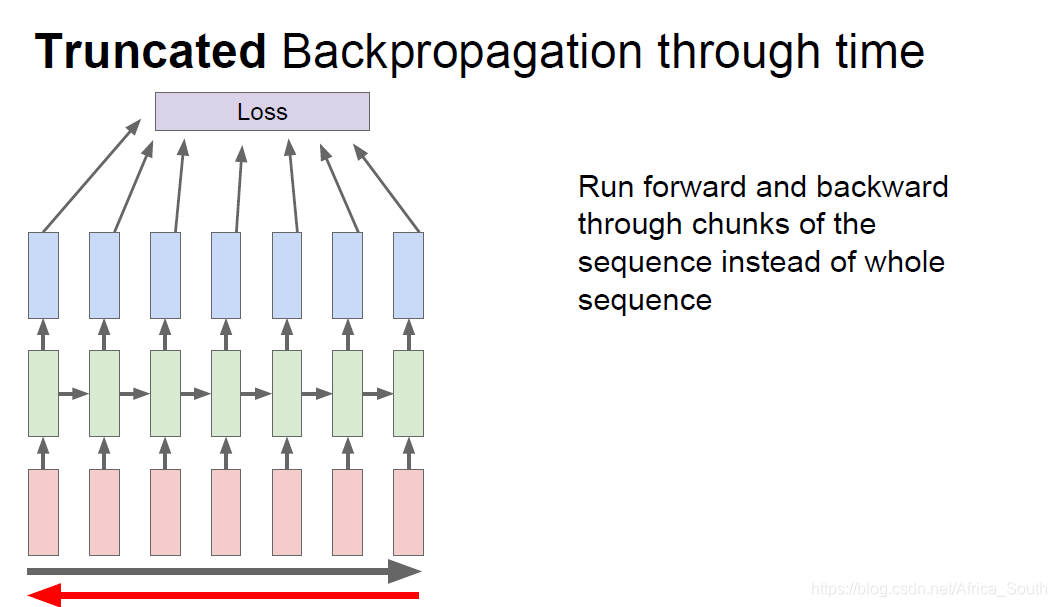
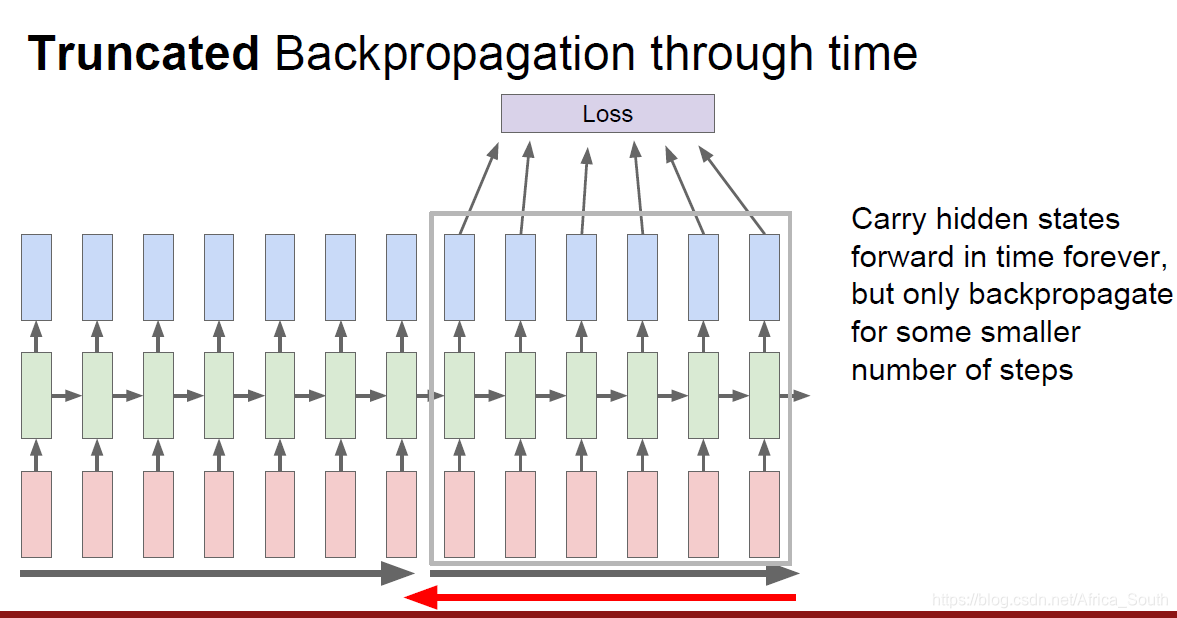
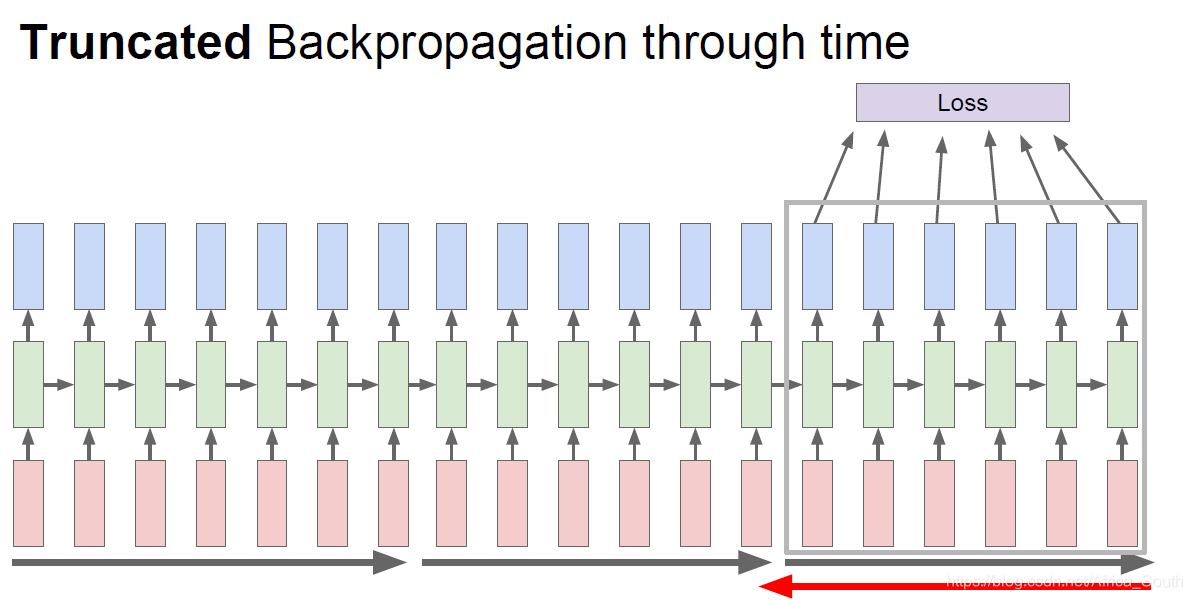
这有点类似于我们更新梯度的时候不适用全部样本,而是小批量更新(mini-batch)。
示例代码 min-char-rnn.py
这种预测字符下一个字符的模型还是非常有用的,它能让我们学习到某种格式的文本的内部结构,例如学习C语言的结构,莎士比亚的十四行诗的结构,然后模仿产生类似的文本。
可解释性
Karpathy, Johnson, and Fei-Fei: Visualizing and Understanding Recurrent Networks, ICLR Workshop 2016
一篇论文从RNN模型中的隐藏层状态中抽取固定位置的激活值,然后观察一个序列输入过程中其大小的变化,发现某些位置是有一定语义的,例如:
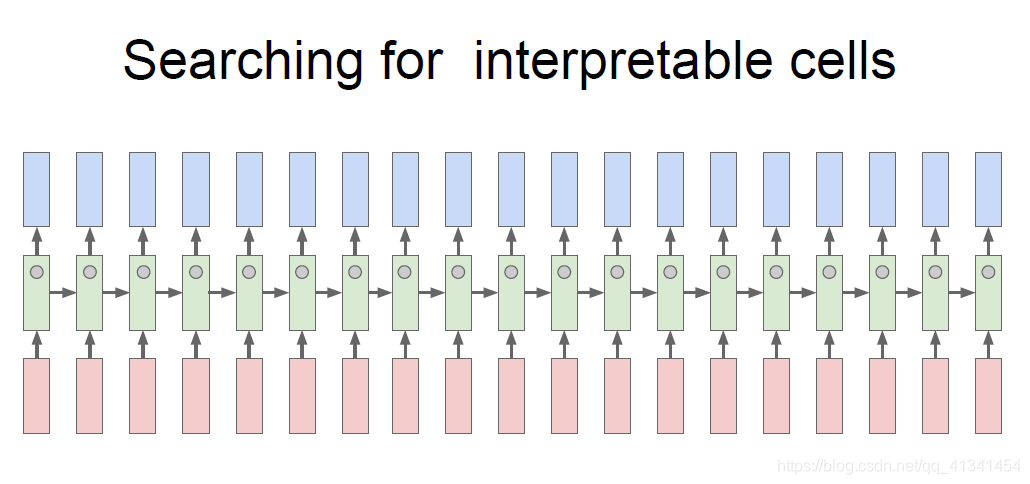
- 下面这个单元在寻找引号(前引号输入后开始激活,直到后引号为止,输入值变小)

- 再例如判断if语句的神经元:

下面开始介绍RNN在计算机视觉上的应用:
3. 图像描述(Image Caption)
3.1 基础模型结构
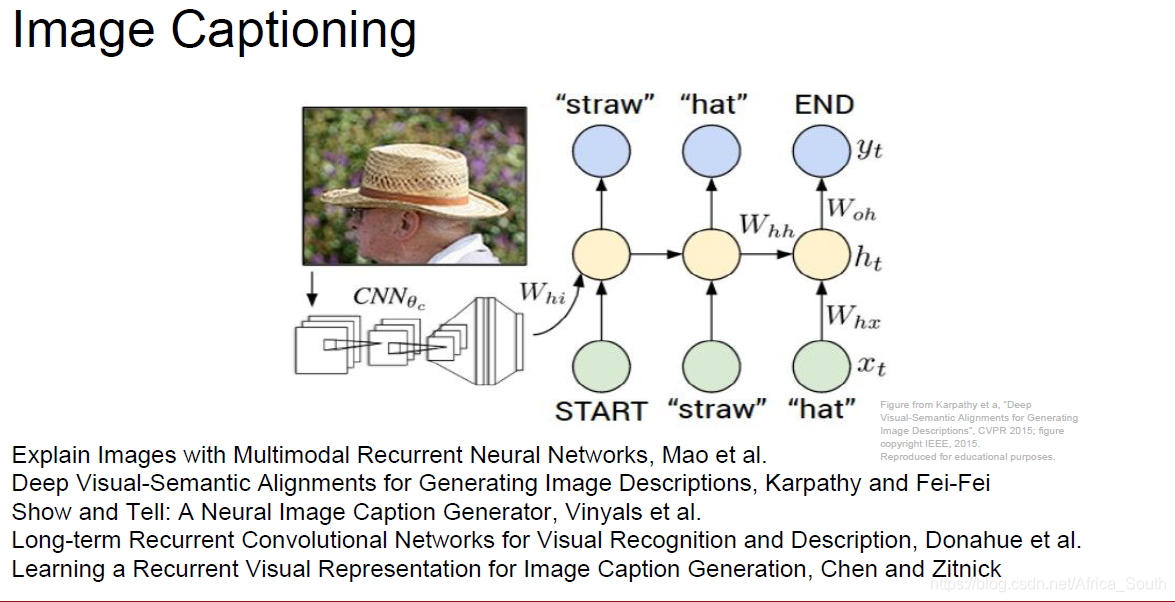
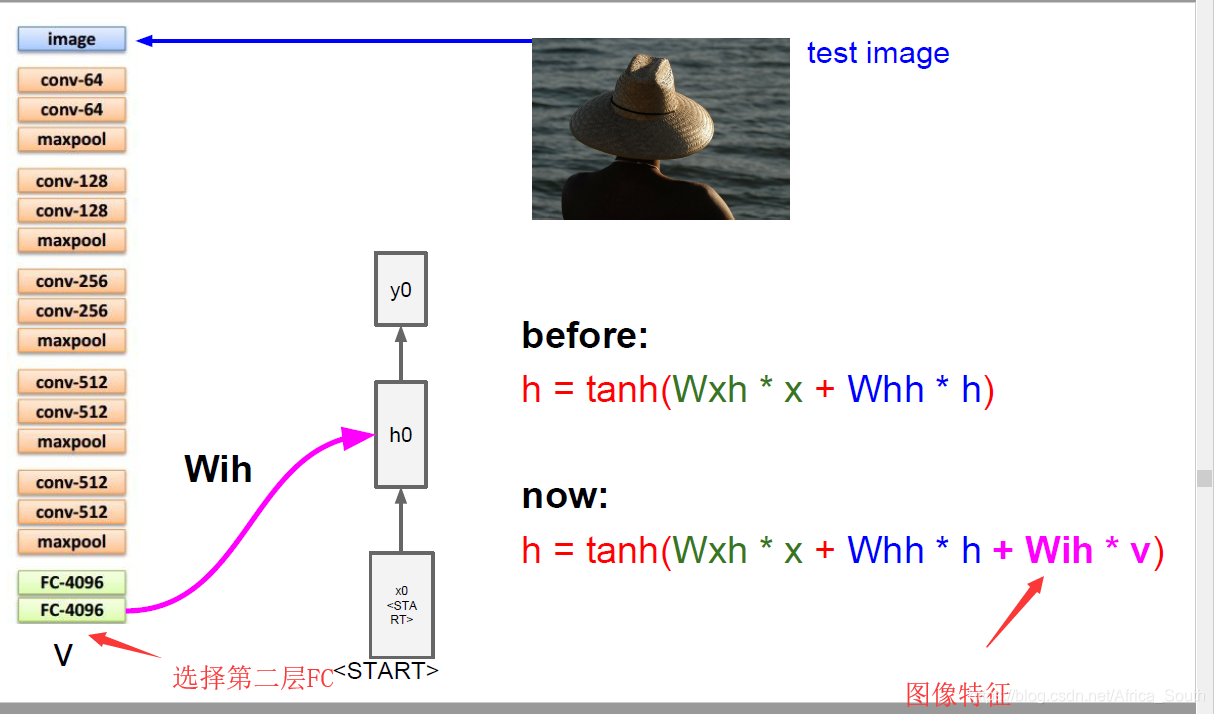
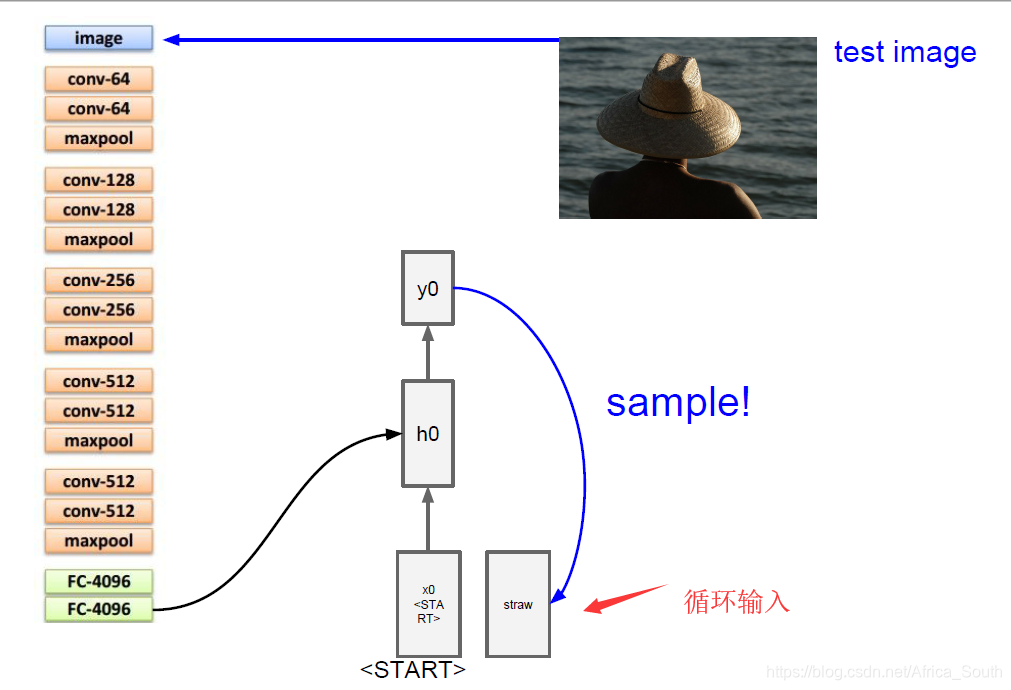
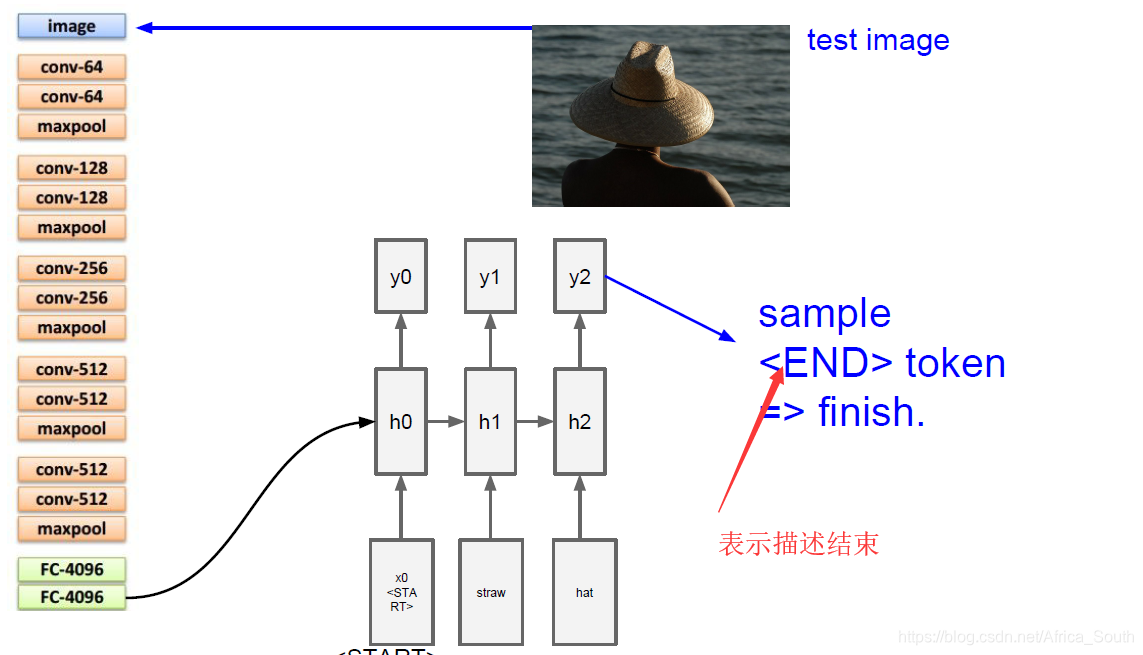
如上图,Image Caption的常见情景就是输入一张图片,然后输出描述这张图片的文字,由于输出是不固定的,所以非常适合使用CNN+RNN的结构。即先用CNN提取图像的一个特征表示,在像之前预测字符一样输出到RNN,循环产生输出。
而在实际操作的使用,我们输入一个指示符START表示我们的输入开始,而且每个隐藏层的状态不仅由上一隐藏层和当前输入单词决定,还要输入我们的 图像特征。
3.2 带有注意力的模型
比之前的模型稍微复杂一点,即在产生描述的时候允许注意力引导模型关注到图像中的关键部分。
其一般做法如下:
Xu et al, “Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention”, ICML 2015
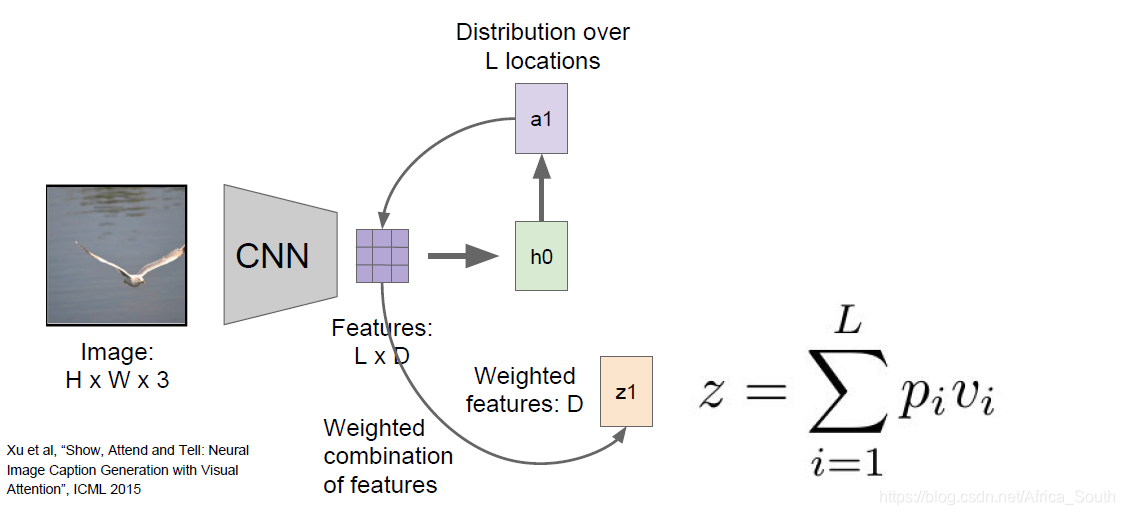
- 表示图像不是由一个一维向量完成的,而是一个向量的序列构成二维网格(L * D)
- 然后每次计算出我们的单词概率分布的同时会产生一个网格的注意力矩阵 a i a_i ai,它指示了我们应该更多的注意的区域(值越大一般注意力越大)。
- 然后下一次输入特征的时候,这个注意力矩阵会加权原始特征矩阵 并和我们的 单词一起输入影响隐藏状态的更新:
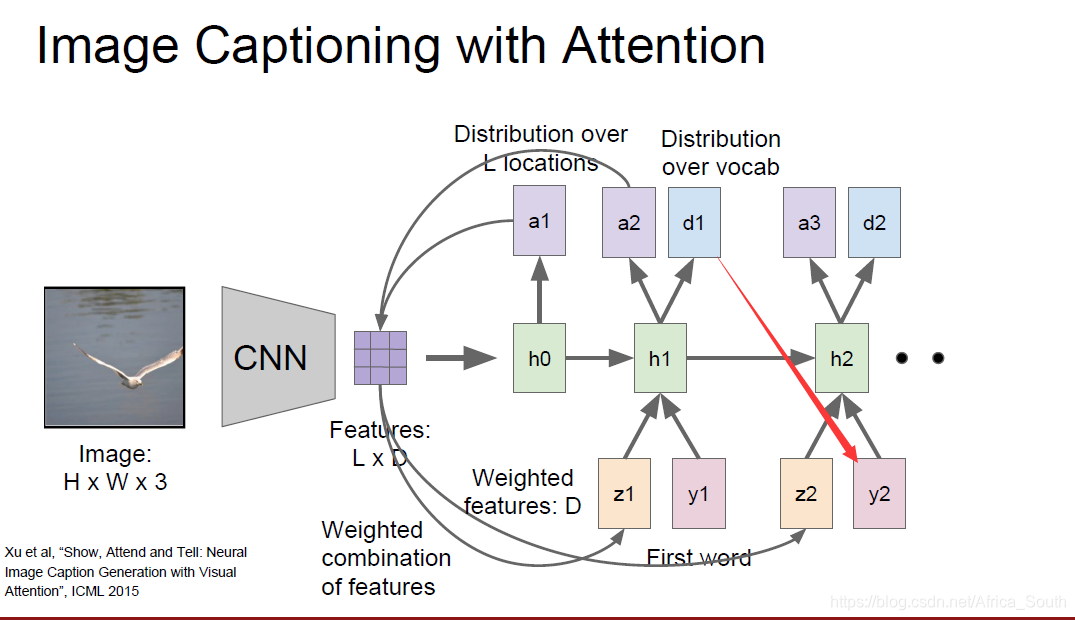
- 训练完成后,我们也能看到在产生单词的时候,注意力会在图像中转移

注:软注意力(Soft attention)即将图像特征进行加权组合,就会有一些特征权重大,一些权重小;硬注意力(hard
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









