




 本文介绍了一种基于项目的协同过滤推荐算法,该算法通过计算物品间的相似度来进行个性化推荐。利用用户-商品评分矩阵,采用余弦相似度计算方法,实现对用户未评分商品的预测评分,并据此为用户推荐其可能感兴趣的商品。
本文介绍了一种基于项目的协同过滤推荐算法,该算法通过计算物品间的相似度来进行个性化推荐。利用用户-商品评分矩阵,采用余弦相似度计算方法,实现对用户未评分商品的预测评分,并据此为用户推荐其可能感兴趣的商品。
类似于基于用户的协同过滤算法。依据是项与项之间的相似度。
算法实现:1、建立项(item)与用户之间的矩阵2、求出所需项之间的相似度3、计算推荐度,相似度与评分相乘计算加权和。比如我们要给A推荐电影,那么根据A看过的电影与其他电影相似度,进行加权评分,得出要给A推荐的电影。4、按照计算出来的推荐度从高到低对用户进行推荐
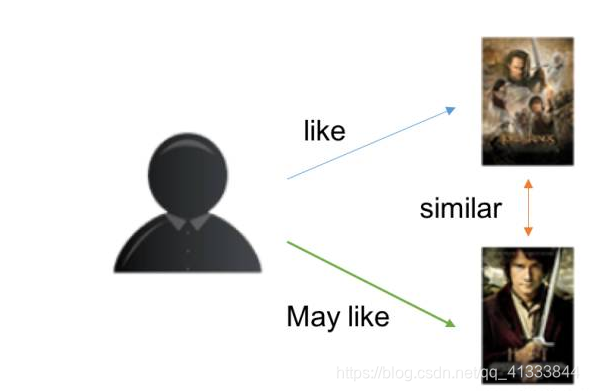
这里相似度的计算还是用余弦相似度。
code:
import math
import numpy as np
#用户-商品矩阵
def item_CF(R):
m, n = R.shape #m行用户*n列电影
for k in range(m):
one = [] #有评分项
zero = [] #无评分项
for i in range(n):
if R[k,i]:
one.append(i)#第k个用户评分过的电影
else:
zero.append(i)#第k个用户没有评分过的电影
_map = {}
for i in zero:
sum = 0
for j in one:
sum += similiar(R[:,i],R[:,j])*R[k,j] #加权相加 相似度*评分 与看过的电影求相似度
_map[i]=sum
sorted__map2list = sorted(_map.items(), key=lambda x: x[1], reverse=True) #按照推荐度从高到低进行排序 返回的是列表
print('对{}用户优先推荐商品编号依次是:'.format(k),end='')
if sorted__map2list:
for i in sorted__map2list:
print(i[0],'该电影的推荐度是',i[1],end=', ') #1 (0,4)
print()
else:
print('该用户所有的电影都看过了无法进行推荐')
#用余弦相似度计算两个电影之间的相似度
def similiar(a,b):
x = np.dot(a, b)
y = 0
z = 0
la = len(a)
lb = len(b)
for i in range(la):
y += pow(a[i], 2)
y = math.sqrt(y)
for i in range(lb):
z += pow(b[i], 2)
z = math.sqrt(z)
return x / (y * z)
def solve():
R = np.array([[1, 1, 1, 1, 0],
[0, 0, 1, 1, 0],
[0, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
])
item_CF(R)
if __name__ == '__main__':
solve()
运行结果:

更新:虽然网上代码不少是使用【相似度*评价值】作为推荐度的衡量标准,但是为了达到更加准确的进行推荐,并且对矩阵中未评分项进行预测,对预测结果进行评估不建议使用。
学长讲的是这个公式

















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









