







1.作者
浦项科技大学 韩国大学(长见识了) qs81
2.贡献
1.提出了multi-layer deconvolution network(由 deconvolution ,unpooling 和 Relu 组成) 个人认为这就是最主要的贡献点
3. 网络结构
其实和我之前看的SegNet差不多

一些比较明显的区别 没有全连接层 可能减少了下采样的次数来达到减少参数的目的。
下面重点介绍我想说的知识点
- Unpooling
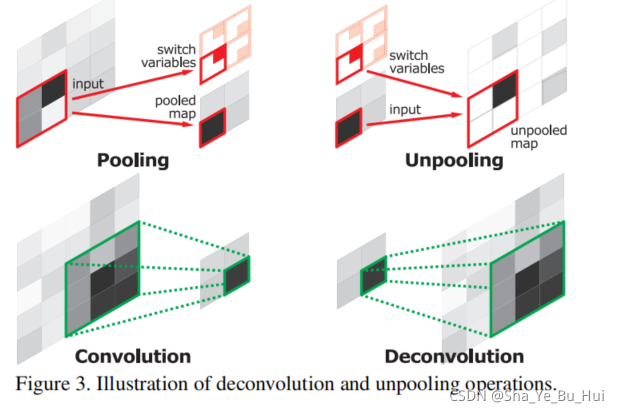
这个不跟和SegNet 没有区别的。。。。
通常来说反卷积应该是扩大图像的面积的这里我的理解就是和保证卷积大小不变的方法一保证不变让原本的稀疏矩阵变为稠密矩阵
在我分析SegNet的文章中我们可以看到感觉这种做法好像没有太大的意义他们都把后面变为再过一遍卷积了
4.其他值得注意的细节问题
- two-stage train
- 先用easy examples train
- 再用更具挑战性的examples fine-tune
构造第一阶段的训练样本:用ground-truth标注crop object instances ,使得物体位于裁剪的bbox的中心。通过减少物体位置和大小的变化,可以减少语义分割搜索空间,减少训练样本的数量;
第二阶段构造挑战性样本:
这应该是类似yolo的思想(但是看不懂
ref:https://blog.youkuaiyun.com/wgf5845201314/article/details/64541617
和FCN结合起来获得更好的结果 (雾 那为啥SegNet删除了 我愿称之为玄学)

















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









