







 本文深入探讨Spark的运行机制,解析RDD构建过程,DAG的形成与切分标准,以及Task的调度与执行,揭示Spark高效并行计算的秘密。
本文深入探讨Spark的运行机制,解析RDD构建过程,DAG的形成与切分标准,以及Task的调度与执行,揭示Spark高效并行计算的秘密。
Spark-core原理初步学习小结[一]
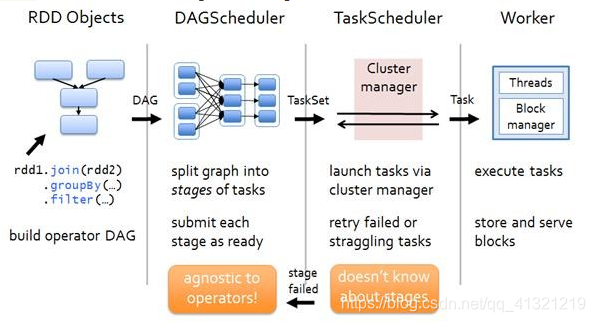
RDD Objects 阶段
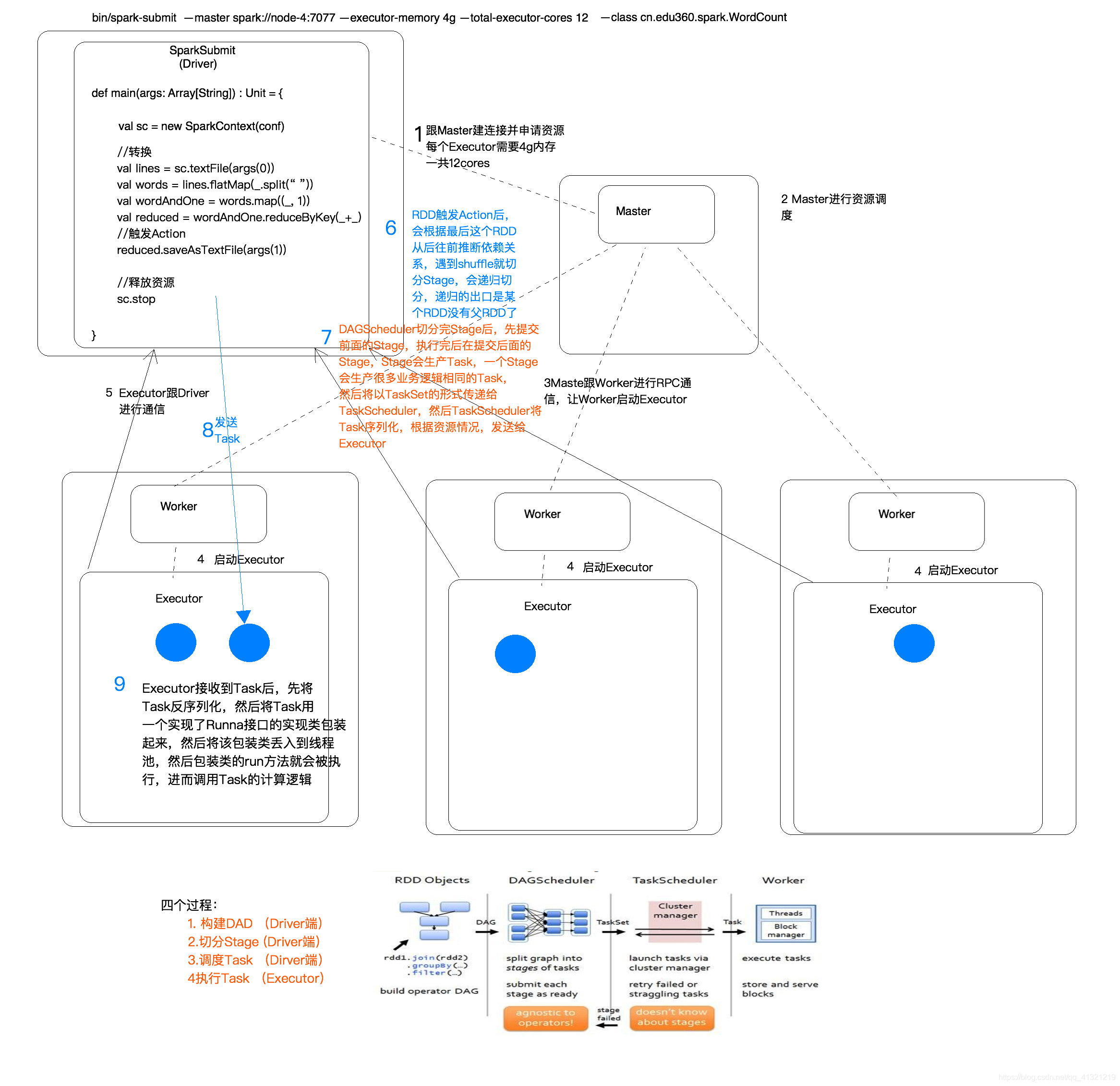
在这个阶段主要对各个RDD进行构建(对各个规则进行定制,实现完整执行流程),生成DAG(有向无环图)
DAG是有边界的:开始(通过SparkContext创建的RDD),结束(触发Action,调用run Job就是一个完整的DAG就形成了,一旦触发Action就形成了一个完整的DAG)
RDD的概念
RDD是一个基本的抽象,操作RDD就像操作一个本地集合一样,降低了编程的复杂度
RDD的算子分为两类,一类是Transformation(lazy),一类是Action(触发任务执行),也就t说Transformation的算子不会立刻执行,而是等待一个Action,遇到Action后会执行上一个Action到这一个Action以后的所有Transformation
RDD不存真正要计算的数据,而是记录了RDD的转换关系(调用了什么方法,传入什么函数),也就是说在RDD中只记录了运算规则,并没有实际的进行计算,而是在后面将这些规则分发到各个node的executor中对这些规则进行执行
DAG Scheduler 阶段
这个阶段主要是对上个阶段生成的DAG进行切分,切成若干Stage
切分Stage的标准
切分Stage的标准是有无Shuffle(宽依赖),也就是说切分一个Stage就是切从上一个Shuffle到下一个Shuffle内的所有Transformation
切分Stage的原因
一个复杂的业务逻辑(将多台机器上具有相同属性的数据聚合到一台机器上:shuffle)
如果有shuffle,那么就意味着前面阶段产生的结果后,才能执行下一个阶段,下一个阶段的计算要依赖上一个阶段的数据。
在同一个Stage中,会有多个算子,可以合并在一起,我们称其为pipeline(流水线:严格按照流程、顺序执行)
切分Stage后输出
切分成Stage后会生成Task(Task可以说是任务执行的基本单位,一个Task在一个节点的一个分区中),然后将生成的TaskSet传向下一个阶段
TaskScheduler 阶段
这个阶段主要是对Task进行调度,将这些Task根据资源的情况调度到各个Execute中(Task调度会尽可能的在各个node本地对本地存储的内容进行执行)
Work 阶段
这个阶段就是对Task进行执行,执行方式就是将各个Task丢入线程池中进行执行

















 2096
2096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









