



人的专注力只有10分钟,今天内容非常简单:
① 推理环境与准备
② 全尺寸下载DeepSeek1.5B/7B/8B/14B/32B/72B等
③ 本地跑起来,兼容openai api格式推理
④ 将模型接入RAG-langchain中
第一部分:推理环境与准备
本次实践全程使用win11系统,具体环境与版本,是这样的:
操作系统:win11-wsl2
显卡:RTX3090*24G*2张
Python版本:3.10
依赖管理:conda
推理工具:vllm
cuda版本:12.4
pytorch版本:2.5.1
如果你还未搭建AI环境及wsl,请你到这里,先跟着操作,搭建好自己的AI环境,否则无法继续
打开你的wsl!
如果你未用过,图标是这样的:
未安装?到开头的第一个链接安装!

创建conda环境!
我们统一使用conda来管理依赖,以免版本冲突,养成习惯,你应该每做一个项目,都是新的环境!
在刚刚你打开的这个窗口,输入指令,回车!
指定环境名称“ds”,指定Python版本3.10
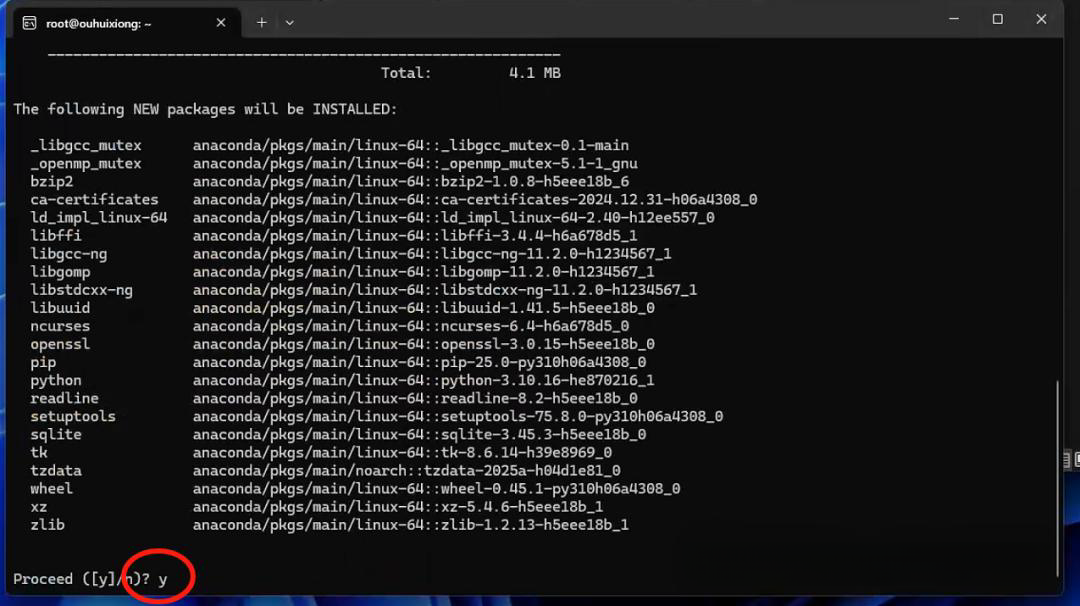
conda create --name ds python=3.10
输入“y”,回车确认!
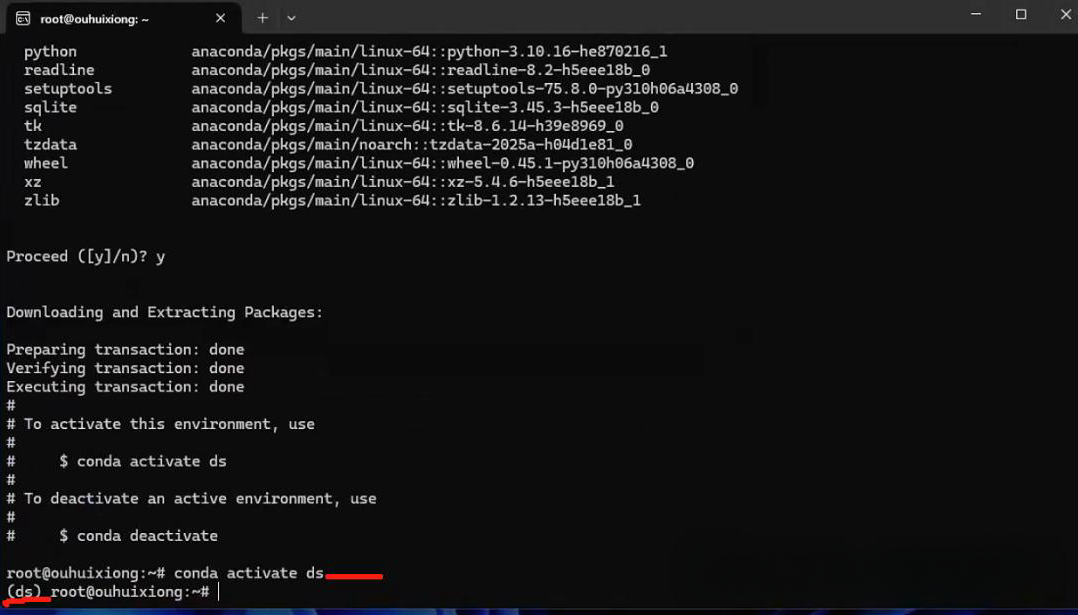
激活进入“ds”环境!
等待几秒后,激活当前的环境!
conda activate ds
激活后,前面会多一个环境名称,说明进入成功了!
安装pytorch!
我们cuda是12.4版本,现在,我们要安装对应的版本才行!
在环境中输入以下指令,回车安装!
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia
如果你的是其他版本的cuda,比如11.8/12.1,你可以到这里下载!
https://pytorch.org/get-started/previous-versions/
这里看网速了,网速越快,耗时越短!
安装vllm!
直接安装最新版本即可!兼容!
在同一个命令窗,输入以下指令,回车!
pip install vllm -i https://pypi.tuna.tsinghua.edu.cn/simple
这里,我们使用清华源下载,避免网络不畅,网速慢问题!
到这里,环境,全部搞掂!
如果你有任何报错,请你确认,是否进入了新的conda环境!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

第二部分:全尺寸模型下载!
授人以鱼不如授人以渔
模型下载,你可以自己在hugging face或魔搭下载!
hugging face:https://huggingface.co/models
魔搭:https://www.modelscope.cn/organization/deepseek-ai
假设你已经拿到了所有下载连接,你可以根据自己算力,选择合适的参数,下载到本地!
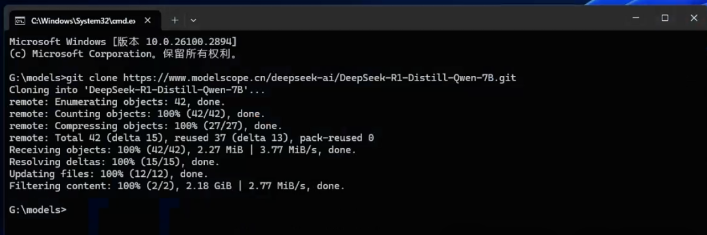
比如我要下载7B的,下载连接就是这个:
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B.git
还是在这个窗口,粘贴以上链接,回车!
会自动下载!
模型文件保存到当前文件夹!
第三部分:讲模型推理起来,暴露API供下游调用!
万事具备
还是在这个窗口!
输入以下指令,回车!推理!
vllm serve /root/model/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --max-model-len 4096 --api-key token-abc123 --enable-auto-tool-choice --tool-call-parser hermes
出现这样,就说明推理成功了!
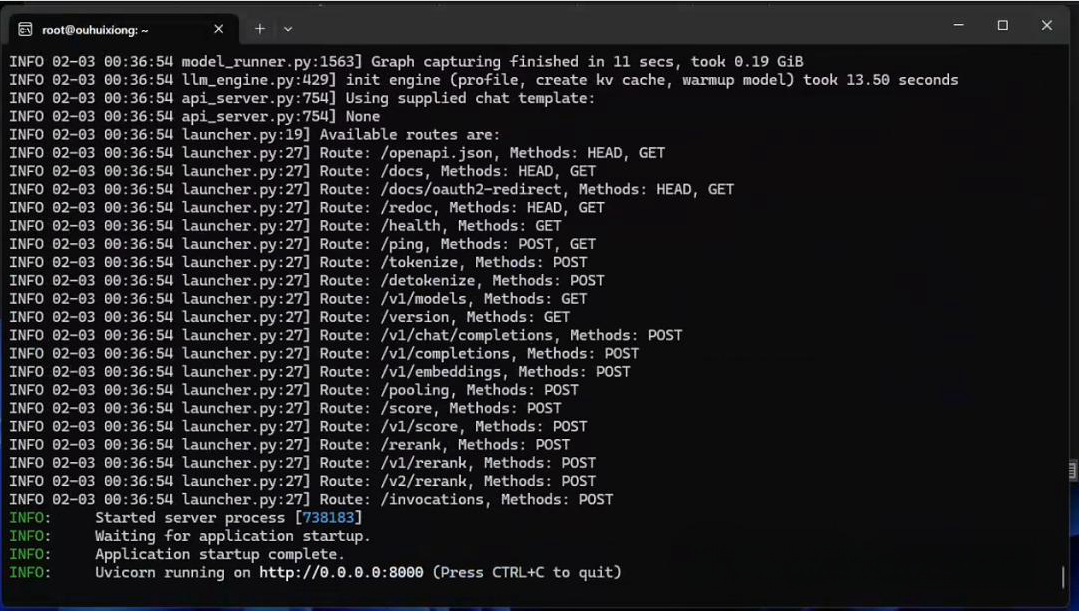
简单说一下参数吧!
–served-model-name DeepSeek-R1-Distill-Qwen-7B
API 中使用的模型名称。如果提供了多个名称,则服务器将响应提供的任何名称。响应的 model 字段中的模型名称将是此列表中的第一个名称。如果未指定,则模型名称将与参数相同。
–max-model-len 4096:
最大模型长度:指定模型能够处理的最大序列长度。在这里,最大长度设置为4096个词元(tokens),增加这个值可以让模型处理更长的文本,但同时也需要更多的计算资源和时间
–api-key token-abc123:
API密钥:用于身份验证的密钥,以确保只有授权用户能够访问模型服务。在这里,API密钥是“token-abc123”
–enable-auto-tool-choice
为支持的模型启用自动工具选择。用于指定要使用的解析器,–tool-call-parser
–tool-call-parser
根据您使用的模型选择工具调用解析器。这用于将模型生成的工具调用解析为 OpenAI API 格式,需要:–enable-auto-tool-choice
如果你想了解更多参数,可以到这里:
https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html!
第四部分:如何接入RAG-langchain中
因为上面,我们已经完全本地部署了
兼容openai api格式
理论上,你可以接到任何的应用中
现在演示如何接入langchain中!
from langchain_community.llms import VLLMOpenAI
llm = VLLMOpenAI(
openai_api_key="token-abc123",
openai_api_base="http://localhost:8000/v1",
model_name="DeepSeek-R1-Distill-Qwen-7B",
model_kwargs={"stop": ["."]},
)
print(llm.invoke("1+1等于几?"))
就如此简单!
后面,我们会使用这个模型,接入到agent,测试DeepSeek-R1-Distill系列的函数调用能力!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料。包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程扫描领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程扫描领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程扫描领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程扫描领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程扫描领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓


















 2101
2101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









