




YOLOV8目标检测主干网络改进实例与创新改进专栏
目录
论文地址:2303.08810![]() https://arxiv.org/pdf/2303.08810
https://arxiv.org/pdf/2303.08810
1.完整代码获取
此专栏提供完整的改进后的YOLOv11项目文件,你也可以直接下载到本地,然后打开项目,修改数据集配置文件以及合适的网络yaml文件即可运行,操作很简单!订阅专栏的小伙伴可以私信博主,或者直接联系博主,加入yolov11改进交流群;
+Qq:1921873112
2.Biformer主干网络介绍
- BiFormer(Bilinear Attention Transformer)主干网络是一种创新的神经网络架构,主要用于计算机视觉任务,如目标检测、图像分类等。它融合了 Transformer 架构的自注意力机制优势和一些针对视觉任务的高效设计,以提高模型在视觉数据处理上的性能。
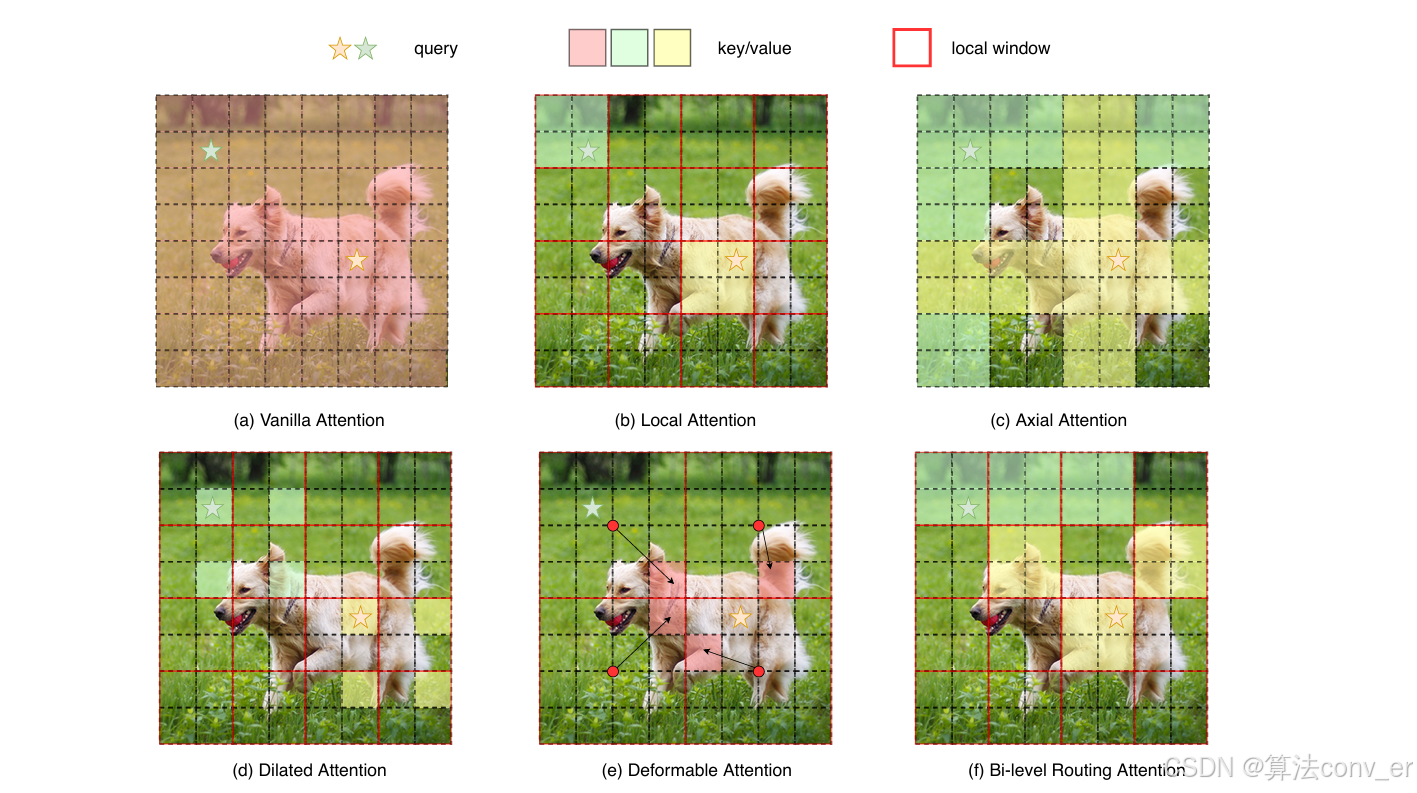
Biformer提出了一种通过双层路由的新型动态稀疏注意力,以实现具有内容感知的计算的更灵活的分配。具体来说,对于查询,首先在粗略的区域级别上删除不相关的键值对,然后在剩余候选区域(即路由区域)的联合中应用细粒度的令牌到令牌注意力。我们提供了一个简单而有效的双层路由注意力的实现,它利用稀疏性来节省计算和内存,同时只涉及对 GPU 友好的密集矩阵乘法。然后,利用所提出的双层路由注意力构建了一个新的通用视觉转换器。由于 BiFormer以查询自适应的方式处理相关标记的一小部分,而不会分散其他不相关标记的注意力,因此它具有良好的性能和高计算效率。
3. Biformer具有优势:
- 架构特点
- 双线性注意力机制(Bilinear Attention)
- 传统的 Transformer 自注意力机制计算复杂度较高,在处理高分辨率视觉图像时会面临巨大的计算量挑战。BiFormer 引入了双线性注意力机制,它通过一种更高效的方式来计算特征之间的相关性。
- 具体来说,双线性注意力将注意力计算分解为两个线性变换,这种分解方式可以有效降低计算复杂度。例如,在计算图像特征图中某个位置与其他位置的相关性时,通过双线性变换可以更快速地得到相似性权重,而不是像传统自注意力那样进行全维度的计算。
- 局部和全局感知融合
- BiFormer 能够有效地融合局部和全局信息。在视觉任务中,局部信息对于捕捉物体的细节特征很重要,比如物体的边缘、纹理等;全局信息则有助于理解物体在整个图像中的位置、类别等语义信息。
- 它通过一种分层的结构,在不同的层次上分别处理局部和全局特征,然后将它们融合在一起。比如在网络的较低层,更侧重于提取局部细节特征,而在较高层,会将局部特征与通过全局池化等方式得到的全局特征进行融合,从而使模型既能关注细节又能把握整体语义。
- 高效的特征提取模块
- 包含多个精心设计的特征提取层,这些层采用了高效的卷积和 Transformer 操作组合。例如,在一些层中,先使用卷积操作来快速提取局部特征,然后通过 Transformer 模块中的多头注意力机制来进一步处理这些特征,以获取特征之间的长距离依赖关系。
- 双线性注意力机制(Bilinear Attention)
- 性能优势
- 在目标检测任务中的表现
- 在目标检测任务中,BiFormer 主干网络能够准确地定位目标物体的位置并且对物体的类别进行精准分类。与一些传统的基于卷积神经网络(CNN)的主干网络相比,它在处理复杂场景下的小目标检测和遮挡目标检测等问题上表现出更好的性能。
- 这是因为其双线性注意力机制可以更好地捕捉目标与背景之间的关系,以及目标内部不同部分之间的关联,从而提高检测的准确性。
- 在图像分类任务中的优势
- 对于图像分类任务,BiFormer 能够提取更具代表性的图像特征。它可以从图像中挖掘出不同层次的语义信息,从低级的纹理特征到高级的类别语义特征。
- 这种多层次的特征提取能力使得它在面对不同类型的图像数据集时,能够更好地适应数据的多样性,从而获得较高的分类准确率。
- 在目标检测任务中的表现
- 应用场景
- 智能安防
- 在智能安防监控系统中,BiFormer 主干网络可以用于对监控视频中的目标进行实时检测和分类。例如,在机场、银行等场所,能够快速准确地识别出可疑人员、行李等目标,提高安防效率。
- 自动驾驶
- 在自动驾驶领域,它可以用于对道路场景中的车辆、行人、交通标志等目标进行检测和识别。帮助车辆更好地理解周围环境,为自动驾驶决策提供更准确的信息。
- 智能安防
4. Biformer网络结构图
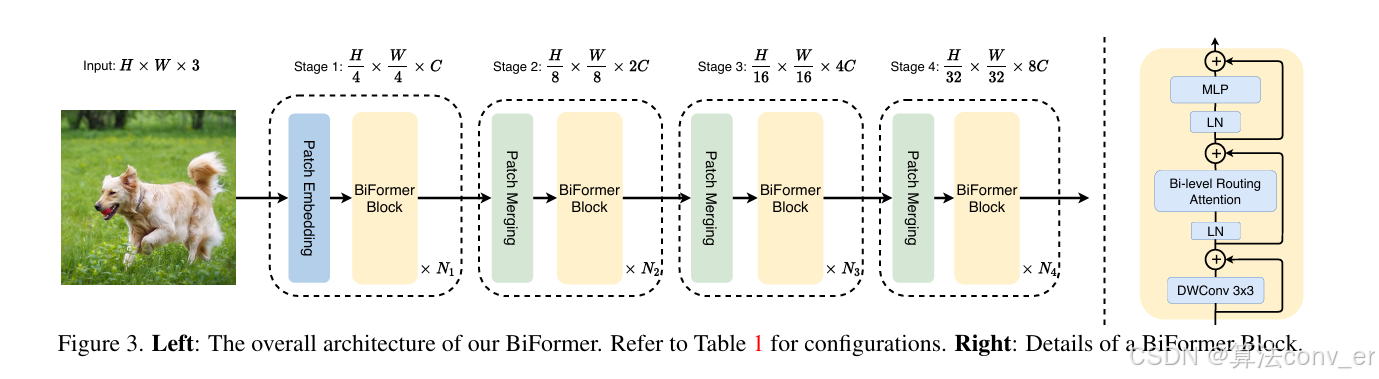
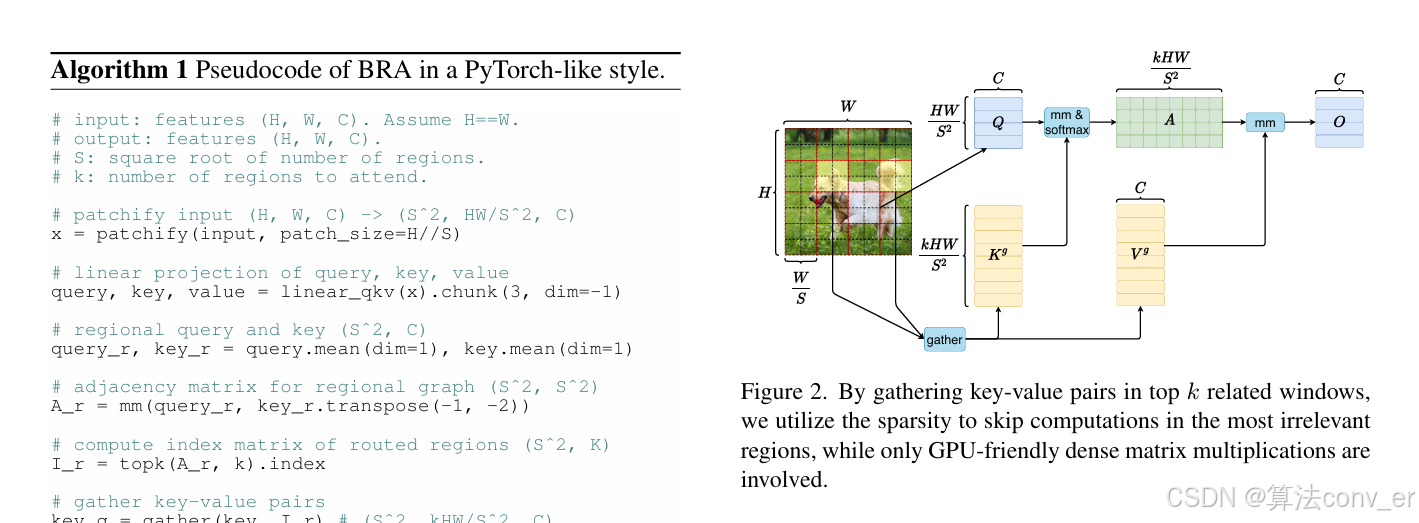
5. yolov8-C2FBiformer yaml文件
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_Biformer, [128, 8]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_Biformer, [256, 4]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_Biformer, [512, 2]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
6.BIformer代码实现
from collections import OrderedDict
from functools import partial
from typing import Optional, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
from einops.layers.torch import Rearrange
from timm.models import register_model
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.vision_transformer import _cfg
from typing import Tuple
from torch import Tensor
import numpy as np
class DWConv(nn.Module):
def __init__(self, dim):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1)
return x
class KVGather(nn.Module):
def __init__(self, mul_weight='none'):
super().__init__()
assert mul_weight in ['none', 'soft', 'hard']
self.mul_weight = mul_weight
def forward(self, r_idx:Tensor, r_weight:Tensor, kv:Tensor):
"""
r_idx: (n, p^2, topk) tensor
r_weight: (n, p^2, topk) tensor
kv: ( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4706
4706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









