






了解Hadoop中常见概念。
学会Hadoop单机模式的安装及设置。
本教程使用hadoop3.2.1,对于其他版本配置方式可能不同
官方手册:http://hadoop.apache.org/docs/current/
前提条件:已经安装好linux虚拟机,以ubuntu为例。
1.下载JDK解压并配置环境变量:
JDK下载地址https://www.oracle.com/java/technologies/javase-jdk13-downloads.html
解压和环境配置详见ubuntu下载JDK并配置java环境变量
2.安装SSH和rsync工具。
直接输命令即可
sudo apt-get install ssh
sudo apt-get install rsync
3.下载hadoop
这里以hadoop-3.2.1为例。
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
下载后将压缩包移动到/opt目录下。
也可以在/opt目录下通过命令行下载:
sudo wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz

同样将安装包解压到/opt目录下方便管理。
4.解压
sudo tar -zxvf hadoop-3.2.1.tar.gz -C /opt
解压后:

5.配置hadoop的环境变量。
sudo vim /etc/profile
末尾添加:
#HADOOP_HOME
export HADOOP_HOME=/opt/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
java和hadoop环境变量添加后:

刷新配置文件使其立刻生效:
source /etc/profile
测试一下hadoop
hadoop version
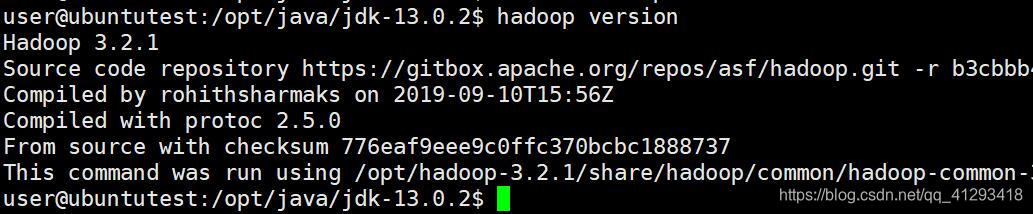
成功。
6.配置hadoop
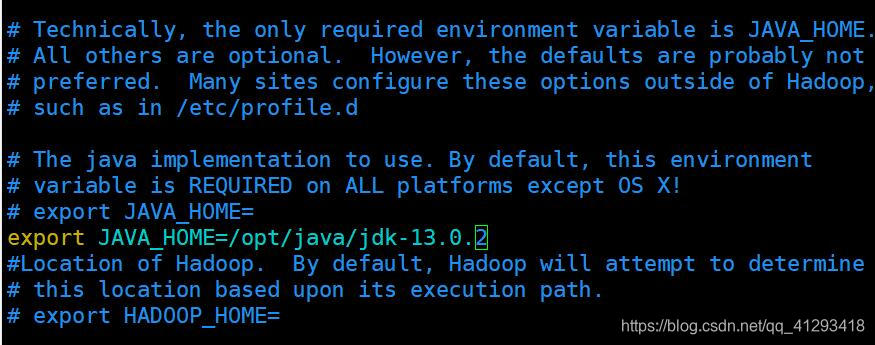
编辑 etc/hadoop/hadoop-env.sh文件,将JAVA_HOME设置为Java安装根路径。
sudo vim /opt/hadoop-3.2.1/etc/hadoop/hadoop-env.sh
添加:
export JAVA_HOME=/opt/java/jdk-13.0.2
7.测试bin/hadoop
8.单机模式运行测试
这是一个简单的官网示例。
回到hadoop根目录。

创建一个input文件夹
sudo mkdir input
创建后

将etc/hadoop下的xml文件拷贝到input文件夹
sudo cp etc/hadoop/*.xml input
拷贝成功后

通过正则匹配,将匹配项写入output文件夹。
sudo bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
如果你安装的是其他版本的hadoop,根据实际情况来确定examples的jar包名字。
查看output中的输出结果
cat output/*

ok了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









