







搜索引擎技术solr
Solr的简介
- Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
- Solr是Apache软件基金会下的子项目之一。
工作原理
-
为什么用solr,首先它会用它的方法帮我们的文章建立索引,索引就代表着快的意思,其次,它会把我们的文章进行分割成很多部分,也就是分词,它会建立这几部分和文章的对应关系,只有我们搜索的时候输入的是其中一部分,马上就能找到这部分对应的文章,想表达的意思就是还是快,所以用它。
-
solr是基于Lucence开发的企业级搜索引擎技术,而lucence的原理是倒排索引。那么什么是倒排索引呢?接下来我们就介绍一下lucence倒排索引原理。
-
假设有两篇文章1和2:
文章1的内容为:老超在卡子门工作,我也是。
文章2的内容为:小超在鼓楼工作。
由于lucence是基于关键词索引查询的,那我们首先要取得这两篇文章的关键词。如果我们把文章看成一个字符串,我们需要取得字符串中的所有单词,即分词。分词时,忽略”在“、”的“之类的没有意义的介词,以及标点符号可以过滤。 -
我们使用Ik Analyzer实现中文分词,分词之后结果为:
文章1:

文章2:

接下来,有了关键词后,我们就可以建立倒排索引了。上面的对应关系是:“文章号”对“文章中所有关键词”。倒排索引把这个关系倒过来,变成: “关键词”对“拥有该关键词的所有文章号”。
文章1、文章2经过倒排后变成:

通常仅知道关键词在哪些文章中出现还不够,我们还需要知道关键词在文章中出现次数和出现的位置,通常有两种位置:
a.字符位置,即记录该词是文章中第几个字符(优点是关键词亮显时定位快);
b.关键词位置,即记录该词是文章中第几个关键词(优点是节约索引空间、词组(phase)查询快),lucene中记录的就是这种位置。
加上出现频率和出现位置信息后,我们的索引结构变为:

Docker安装Solr
- 搜索Solr镜像
docker search solr

- 拉取Solr镜像
docker pull solr - 创建一个solr容器
docker run -d --name mysolr -p 8983:8983 solr
-d:后台运行
–name:别名
-p:指定宿主机和容器的端口要映射
设置防火墙 vim /usr/lib/firewalld/services/ssh.xml
重启防火墙: systemctl restart firewalld
浏览器访问:http://服务器IP:8983 - 配置solr的solrcore
docker exec -it mysolr bin/solr create_core -c mycollection
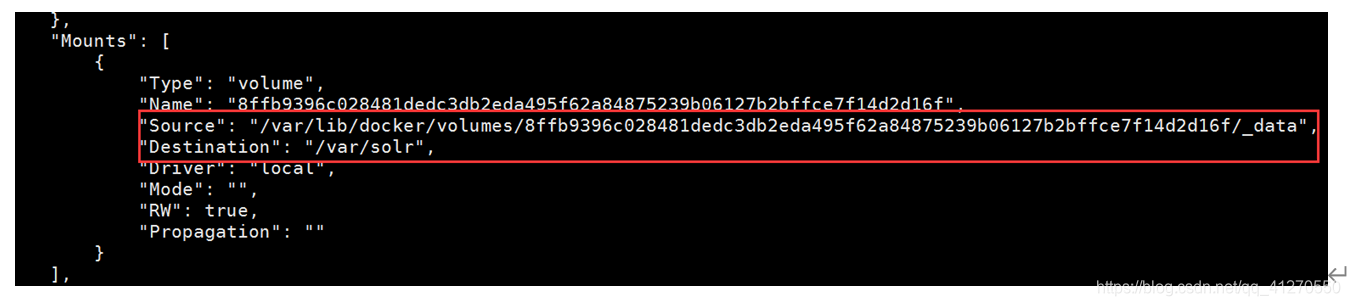
命令说明:给mysolr发送一个指令,执行当前路径下的bin/solr命令,创建一个mycollection的solrcore - 查看solr数据卷在宿主机中对应的位置
docker inspect mysolr
- 配置中文分词器
- 进入到容器中 docker exec -it mysolr /bin/bash
- solr自带的中文分词器路径: /opt/solr/contrib/analysis-extras/lucene-libs/
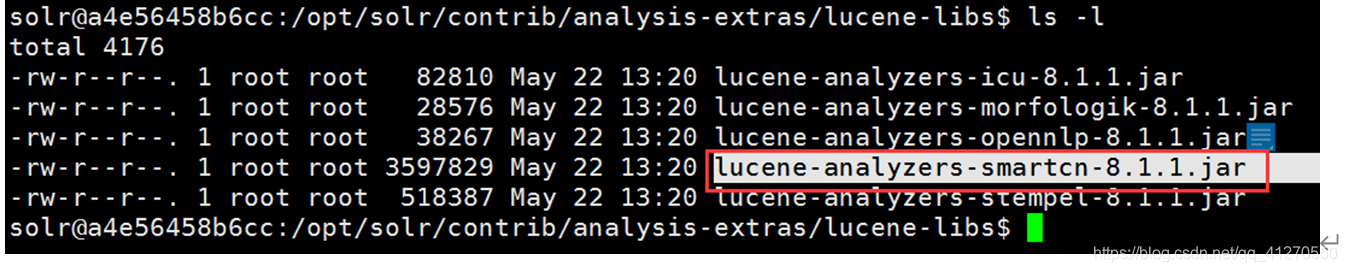
lucene-analyzers-smartcn-8.1.1.jar
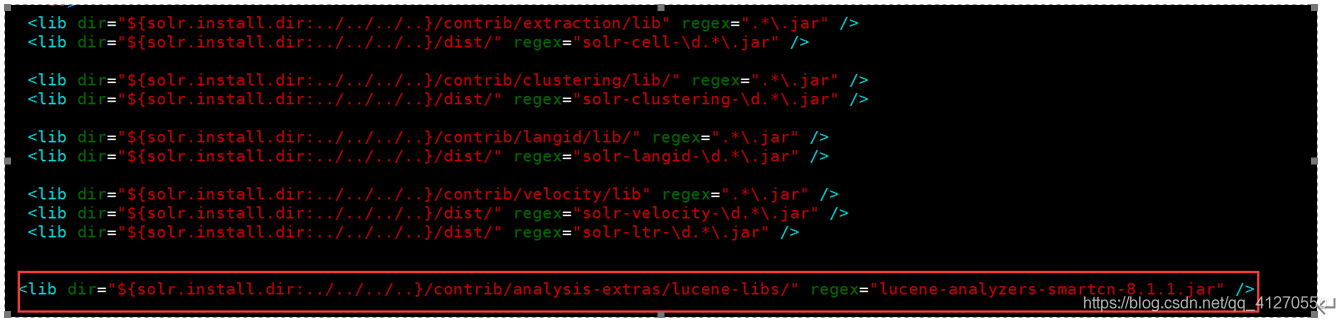
3. 在宿主机映射的路径(Mounts中的路径)中配置分词器:;
/var/lib/docker/volumes/8ffb9396c028481dedc3db2eda495f62a84875239b06127b2bffce7f14d2d16f/_data/data/mycollection/conf
4. vim solrconfig.xml
5. vim managed-schema
<fieldType name="mytext_id" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
Mytext_id是分词器的名称。
org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory:是刚才配置的中文分词器
query:是查询的时候也要分词
重启solr容器 docker restart mysolr,
- 配置solr字段域
vim managed-schema:
<!-- 创建自定义的字段 -->
<field name="gname" type="mytext_id" indexed="true" stored="true"/>
<field name="ginfo" type="mytext_id" indexed="true" stored="true"/>
<field name="gimage" type="string" indexed="false" stored="true"/>
<field name="gprice" type="pfloat" indexed="false" stored="true"/>
<field name="gsave" type="pint" indexed="false" stored="true"/>
name:索引库中的字段名称
Indexed:当前字段是否添加到是索引,添加到索引才能进行搜索。
Stored:是否储存到索引库
name:储存到索引库的字段名称
Type:使用哪个分词器进行分词。
重启solr容器 docker restart mysolr,
注意:这里启动mysolr必须要开启防火墙,否则启动失败
SpringBoot整合Solr
- 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
<version>2.1.7.RELEASE</version>
</dependency>
- 配置application.properties
dubbo.application.name=search_server
dubbo.registry.address=zookeeper://192.168.189.137:2181
dubbo.protocol.port=-1
dubbo.registry.register=true
spring.data.solr.host=http://192.168.189.137:8983/solr/mycollection
- 索引库CRUD
@Autowired
private SolrClient solrClient;
@Test
public void add() throws IOException, SolrServerException {
SolrInputDocument document = new SolrInputDocument();
document.addField("gname","华为荣耀20");
document.addField("ginfo","4800万超广角AI四摄 3200W美颜自拍 麒麟Kirin980全网通版8GB+128GB 幻夜黑 移动联通电信4G全面屏");
document.setField("gimage","a1.png");
document.setField("gprice",1399.00 );
document.setField("gsave",100);
document.setField("id",1);
solrClient.add(document); // 如果id存在就更新
solrClient.commit();
}
@Test
public void delete() throws IOException, SolrServerException {
solrClient.deleteById("a7b2ef4b-2b25-4eb5-b8dd-b6a255d8ca22");
solrClient.commit();
}
@Test
public void getById() throws IOException, SolrServerException {
SolrDocument solrDocument = solrClient.getById("9b518e0b-e45e-4f24-a943-bc5b11d2aebf");
// 1.属性的键值对
Map<String, Object> fieldValueMap = solrDocument.getFieldValueMap();
// 2.所有的属性名称
Set<String> fieldNames = (Set<String>)solrDocument.getFieldNames();
// 3.根据属性名称获取属性值
Object gname = solrDocument.getFieldValue("gname");
// 4.根据属性名称获取属性值,是个数组
Collection<Object> values = solrDocument.getFieldValues("gname");
// 5.根据属性名称获取属性值
Object ginfo = solrDocument.get("ginfo");
}
@Test
public void query() throws IOException, SolrServerException {
SolrQuery solrQuery = new SolrQuery();
// solrQuery.setQuery("*:*");
// solrQuery.setQuery("gname:华为");
solrQuery.setQuery("gname:华为 || ginfo:手机");
QueryResponse queryResponse = solrClient.query(solrQuery);
SolrDocumentList results = queryResponse.getResults();
for(SolrDocument sd:results){
System.out.println(sd.get("gname"));
System.out.println(sd.get("ginfo"));
}
}
- 关键字高亮
public List<Goods> selectByKey(String keyword) {
SolrQuery solrQuery = null;
List<Goods> goodsList = new ArrayList<Goods>();
if(!StringUtils.isEmpty(keyword)){
String queryStr ="gname:%s || ginfo:%s";
solrQuery = new SolrQuery(String.format(queryStr,keyword,keyword));
}else{
solrQuery = new SolrQuery("*:*");
}
// 处理高亮
solrQuery.setHighlight(true); // 开启高亮
solrQuery.setHighlightSimplePre("<font color ='red'>"); // 前缀
solrQuery.setHighlightSimplePost("</font>"); // 后缀
solrQuery.addHighlightField("ginfo"); // 设置高亮字段,可以设置多个
// solrQuery.setStart(1); // 起始行
// solrQuery.setRows(10); // 偏移量
// solrQuery.setSort("id", SolrQuery.ORDER.asc); // 排序
try {
QueryResponse queryResponse = solrClient.query(solrQuery);
SolrDocumentList results = queryResponse.getResults(); // 获取没有高亮的结果
// 获取有高亮的结果<有高亮结果的ID,<高亮字段,高亮内容>>
Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();
for(SolrDocument sd:results){
Goods goods = new Goods();
String id = sd.getFieldValue("id").toString();
String gname = sd.getFieldValue("gname").toString();
String ginfo = sd.getFieldValue("ginfo").toString();
goods.setGname(gname);
goods.setGinfo(ginfo);
if(highlighting.containsKey(id)){
// 条件成立说明这条记录有高亮内容
Map<String, List<String>> listMap = highlighting.get(id);
if(listMap.containsKey("ginfo")){ // 判断这条记录中gname是否有高亮
String hightLiGinfo = listMap.get("ginfo").get(0); // 获取高亮内容
goods.setGinfo(hightLiGinfo);
}
}
goodsList.add(goods);
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return goodsList;
}
- 页面显示高亮
<p class="miaoshu" th:utext="${goods.ginfo}"></p>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









