






CUDA和OpenCL比较
-
翻译自https://www.sharcnet.ca/help/index.php/Porting_CUDA_to_OpenCL
-
如有错误请帮忙指正,谢谢
-
OpenCL中的数据并行编程模型与CUDA编程模型有一些共同点,使得从CUDA到OpenCL的程序转换相对简单。
硬件术语
-
硬件比较
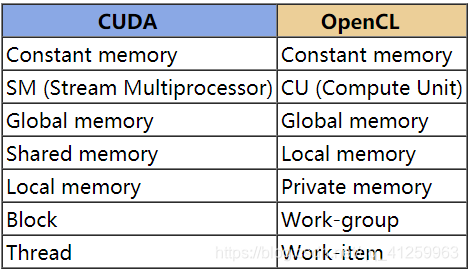
CUDA OpenCL SM (Stream Multiprocessor) CU (Compute Unit) Thread Work-item Block Work-group Global memory Global memory Constant memory Constant memory Shared memory Local memory Local memory Private memory -
Private memory (local memory in CUDA) used within a work item that is similar to registers in a GPU multiprocessor or CPU core. Variables inside a kernel function not declared with an address space qualifier, all variables inside non-kernel functions, and all function arguments are in the __private or private address space. Application performance can plummet when too much private memory is used on some devices – like GPUs because it is spilled to slower memory. Depending on the device, private memory can be spilled to cache memory. GPUs that do not have cache memory will spill to global memory causing significant performance drops.
-
私有内存(CUDA中的本地内存),用于与GPU多处理器或CPU内核中的寄存器类似的工作项中。内核函数中没有用地址空间限定符声明的变量、非内核函数中的所有变量以及所有函数参数都在私有或私有地址空间中。当在某些设备上使用过多的私有内存(如GPU)时,应用程序性能可能会下降,因为它会溢出到较慢的内存中。根据设备的不同,私有内存可能会溢出到缓存中。没有缓存内存的GPU将溢出到全局内存,导致性能显著下降。
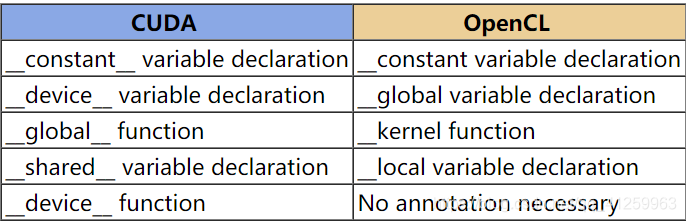
核函数的限定符
- 限定符比较
内核索引
-
索引比较
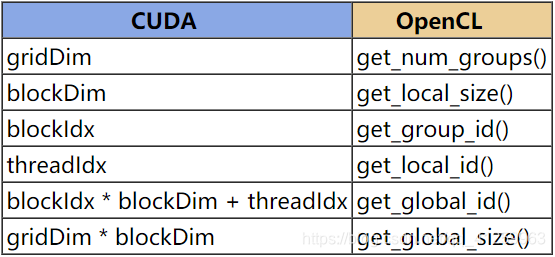
CUDA OpenCL gridDim get_num_groups() blockDim get_local_size() blockIdx get_group_id() threadIdx get_local_id() blockIdx * blockDim + threadIdx get_global_id() gridDim * blockDim get_global_size() -
CUDA is using threadIdx.x to get the id for the first dimension while OpenCL is using get_local_id(0).
-
CUDA使用threadIdx.x获取第一个维度的id,而OpenCL使用get_local_id(0)。
内核同步
- 比较
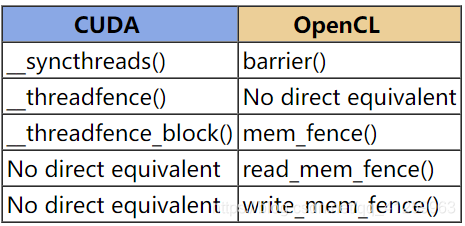
CUDA OpenCL __syncthreads() barrier() __threadfence() No direct equivalent __threadfence_block() mem_fence() No direct equivalent read_mem_fence() No direct equivalent write_mem_fence()
API调用
-
比较
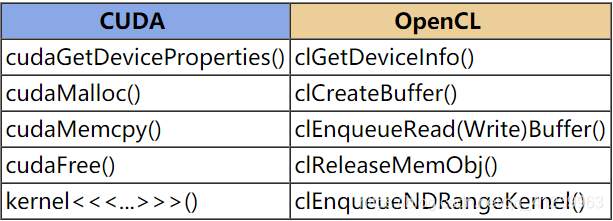
CUDA OpenCL cudaGetDeviceProperties() clGetDeviceInfo() cudaMalloc() clCreateBuffer() cudaMemcpy() clEnqueueRead(Write)Buffer() cudaFree() clReleaseMemObj() kernel<<<…>>>() clEnqueueNDRangeKernel()
案例代码
-
本文将给出一个简单的矢量加法代码,介绍OpenCL程序的基本工作流程。一个简单的OpenCL程序包含一个源文件main.c和一个内核文件kernel.cl
-
main.c
#include <stdio.h> #include <stdlib.h> #ifdef __APPLE__ // Mac OSX 有一个不同的头文件名 #include <OpenCL/opencl.h> #else #include <CL/cl.h> #endif #define MEM_SIZE (128) // 假设有一个128个元素的矢量 #define MAX_SOURCE_SIZE (0x100000) int main() { //In general Intel CPU and NV/AMD's GPU are in different platforms //But in Mac OSX, all the OpenCL devices are in the platform "Apple" // 一般Intel CPU 和 NV/AMD's GPU是在不同的平台 // 但是在Mac OSX,所有的OpenCL设备都在同一个同台“Apple” cl_platform_id platform_id = NULL; cl_device_id device_id = NULL; cl_context context = NULL; cl_command_queue command_queue = NULL; // "stream" in CUDA cl_mem memobj = NULL; // device memory,设备存储器 cl_program program = NULL; // cl_program是一个从源或者二进制文件创建的可执行程序 cl_kernel kernel = NULL; // kernel函数 cl_unit ret_num_devices; cl_unit ret_num_platforms; cl_int ret; // accepts return values for APIs,接收API的返回值 float men[MEM_SIZE]; // alloc memory on host(CPU) ram,在主机存储器上分配内存 // OpenCL source can be placed in the source code as text strings or read from another file. // OpenCL源可以作为字符串放置在源码中,或者从另一个文件中读取 FILE *fp; const char fileName[] = "./kernel.cl"; size_t source_size; char *source_str; cl_int i; // read the kernel file into ram,读取kernel(内核)文件到RAM中 fp = fopen(fileName, "r"); if(!fp) { fprintf(stderr, "Failed to load kernel.\n"); exit(1); } source_str = (char *)malloc(MAX_SOURCE_SIZE); source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp); fclose(fp); // 初始化数组 for(i = 0; i < MEM_SIZE; i++) { mem[i] = i; } // 获取设备信息,为什么获取两次 ? ret = clGetPlatformIDs(1, &platform_id, &ret_num_platforms); ret = clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_DEFAULT, 1, &device_id, &ret_num_devices); // create context on the specified device,在指定设备上创建上下文 context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret); // create the command_queue (stream),创建指令队列 command_queue = clCreateCommandQueue(context, device_id, 0, &ret); // alloc mem on the device with the read/write flag // 在设备上分配内存,指定读写方式 memobj = clCreateBuffer(context, CL_MEM_READ_WRITE, MEM_SIZE * sizeof(float), NULL, &ret); // copy the memory from host to device, CL_TRUE means blocking write/read // 将内存从主机复制到设备,CL_TRUE表示阻止写入/读取 ret = clEnqueueWriteBuffer(command_queue, memobj, CL_TRUE, 0, MEM_SIZE * sizeof(float), mem, 0, NULL, NULL); // 为上下文创建程序对象,将文本字符串指定的源代码加载到程序对象中 program = clCreateProgramWithSource(context, 1, (const char **)&source_str, (const size_t *)&source_size, &ret); // build (compiles and links) a program executable from the program source or binary // 从程序源或二进制文件生成(编译和链接)可执行程序 ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL); // 创建具有指定名称的内核对象 kernel = clCreateKernel(program, "vecAdd", &ret); //set the argument value for a specific argument of a kernel ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&memobj); //define the global size and local size (grid size and block size in CUDA) // 定义全局的大小和局部的大小(CUDA中的网格大小和块大小) size_t global_work_size[3] = {MEM_SIZE, 0, 0}; size_t local_work_size[3] = {MEM_SIZE, 0. 0}; //Enqueue a command to execute a kernel on a device ("1" indicates 1-dim work) // 将在设备上执行内核的命令进行排队(“1”表示1维工作) ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL, global_work_size, local_work_size, 0, NULL, NULL); // copy memory from device to host // 将内存从设备复制到主机 ret = clEnqueueReadBuffer(command_queue, memobj, CL_TRUE, 0, MEM_SIZE * sizeof(float), mem, 0, NULL, NULL); // 打印输入结果 for(i = 0; i < MEM_SIZE; i++) { printf("mem[%d] : %.2f\n", i, mem[i]); } // clFlush only guarantees that all queued commands to command_queue get issued to the appropriate device // There is no guarantee that they will be complete after clFlush returns // clFlush只保证向适当的设备发出命令队列的所有排队命令 // 无法保证在clFlush返回后它们将完成 ret = clFlush(command_queue); // clFinish blocks until all previously queued OpenCL commands in command_queue are issued to the associated device and have completed. // clFinish阻塞,直到命令队列中所有先前排队的OpenCL命令被发送到相关设备并完成。 ret = clFinish(command_queue); ret = clReleaseKernel(kernel); ret = clReleaseProgram(program); ret = clReleaseMemObject(memobj); // 释放设备上的内存 ret = clReleaseCommandQueue(command_queue); ret = clReleaseContext(context); free(source_str); // 释放主机上的内存 return 0; } -
kernel.cl
__kernel void vecAdd(__global float* a) { int gid = get_global_id(0); // in CUDA = blockIdx.x * blockDim.x + threadIdx.x a[gid] += a[gid]; }
浮点数的原子运算
-
CUDA has atomicAdd() for floating numbers, but OpenCL doesn’t have it. The only atomic function that can work on floating number is atomic_cmpxchg(). According to Atomic operations and floating point numbers in OpenCL, you can serialize the memory access like it is done in the next code:
-
CUDA有atomicAdd() 用于浮点数,但OpenCL没有。唯一可以处理浮点数的原子函数是atomic_cmpxchg()。根据OpenCL中的原子操作和浮点数,可以序列化内存访问,就像在下一段代码中那样:
float sum=0; void atomic_add_global(volatile global float *source, const float operand) { union { unsigned int intVal; float floatVal; } newVal; union { unsigned int intVal; float floatVal; } prevVal; do { prevVal.floatVal = *source; newVal.floatVal = prevVal.floatVal + operand; } while (atomic_cmpxchg((volatile global unsigned int *)source, prevVal.intVal, newVal.intVal) != prevVal.intVal); } -
First function works on global memory the second one work on the local memory.
-
第一个函数用于全局内存,第二个函数用于本地内存。
float sum=0; void atomic_add_local(volatile local float *source, const float operand) { union { unsigned int intVal; float floatVal; } newVal; union { unsigned int intVal; float floatVal; } prevVal; do { prevVal.floatVal = *source; newVal.floatVal = prevVal.floatVal + operand; } while (atomic_cmpxchg((volatile local unsigned int *)source, prevVal.intVal, newVal.intVal) != prevVal.intVal); } -
A faster approch is based on the discuss in CUDA developer forums [1]
-
更快的方法是基于CUDA开发者论坛的讨论
inline void atomicAdd_f(__global float* address, float value) { float old = value; while ((old = atomic_xchg(address, atomic_xchg(address, 0.0f)+old))!=0.0f); }

















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









