







爬取喜马拉雅音乐
工具:python3,pycharm,火狐浏览器
模块:requests,time,json
网址:https://www.ximalaya.com/yinyue/3595841/
首先进入网址,我们能看到所有的音乐列表。打开开发者工具F12,点击网络,刷新网页,我们能看到几条数据。
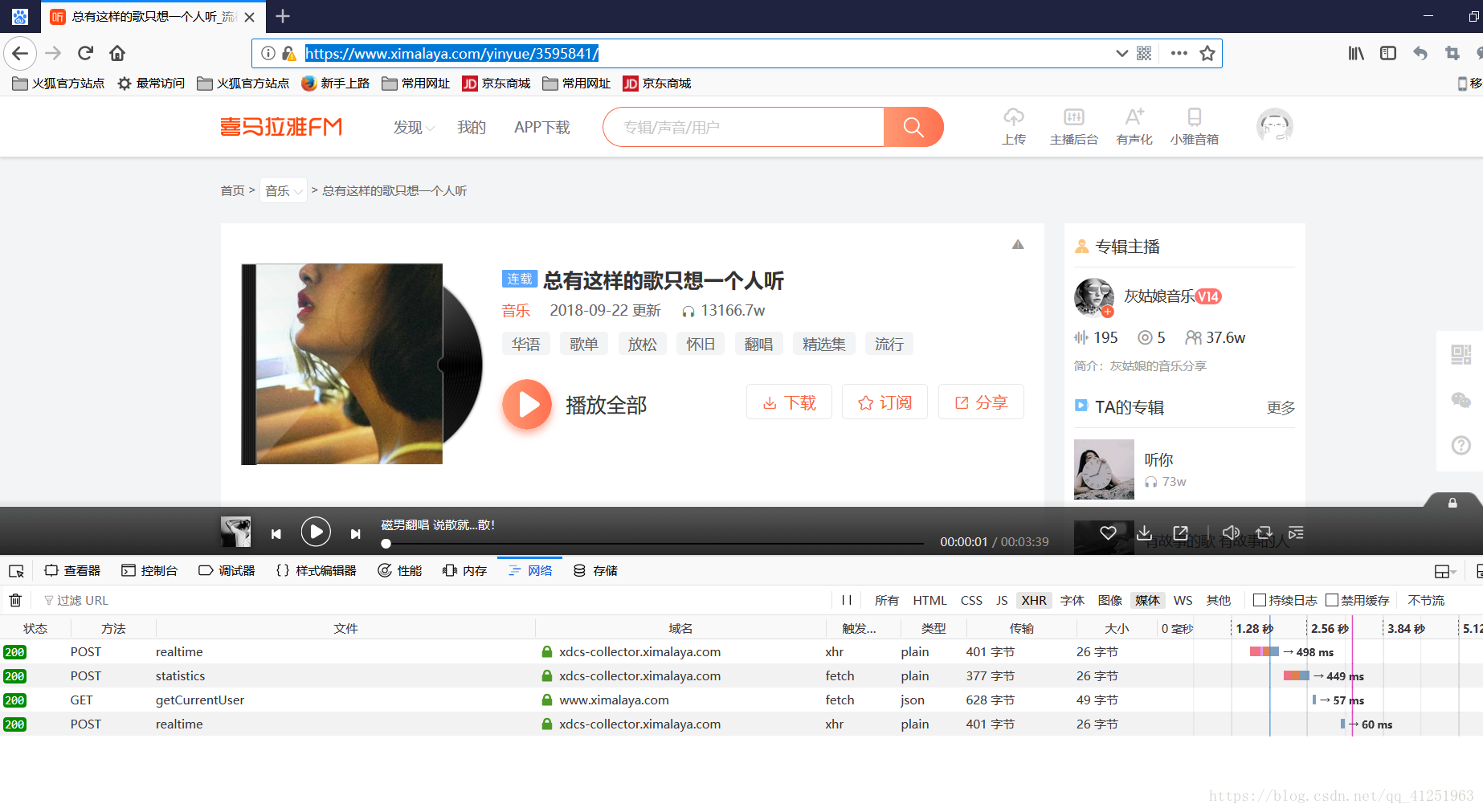
我们点击播放一首音乐,观察下面的数据变化情况。发现红色部分标记的内容,点击一下。
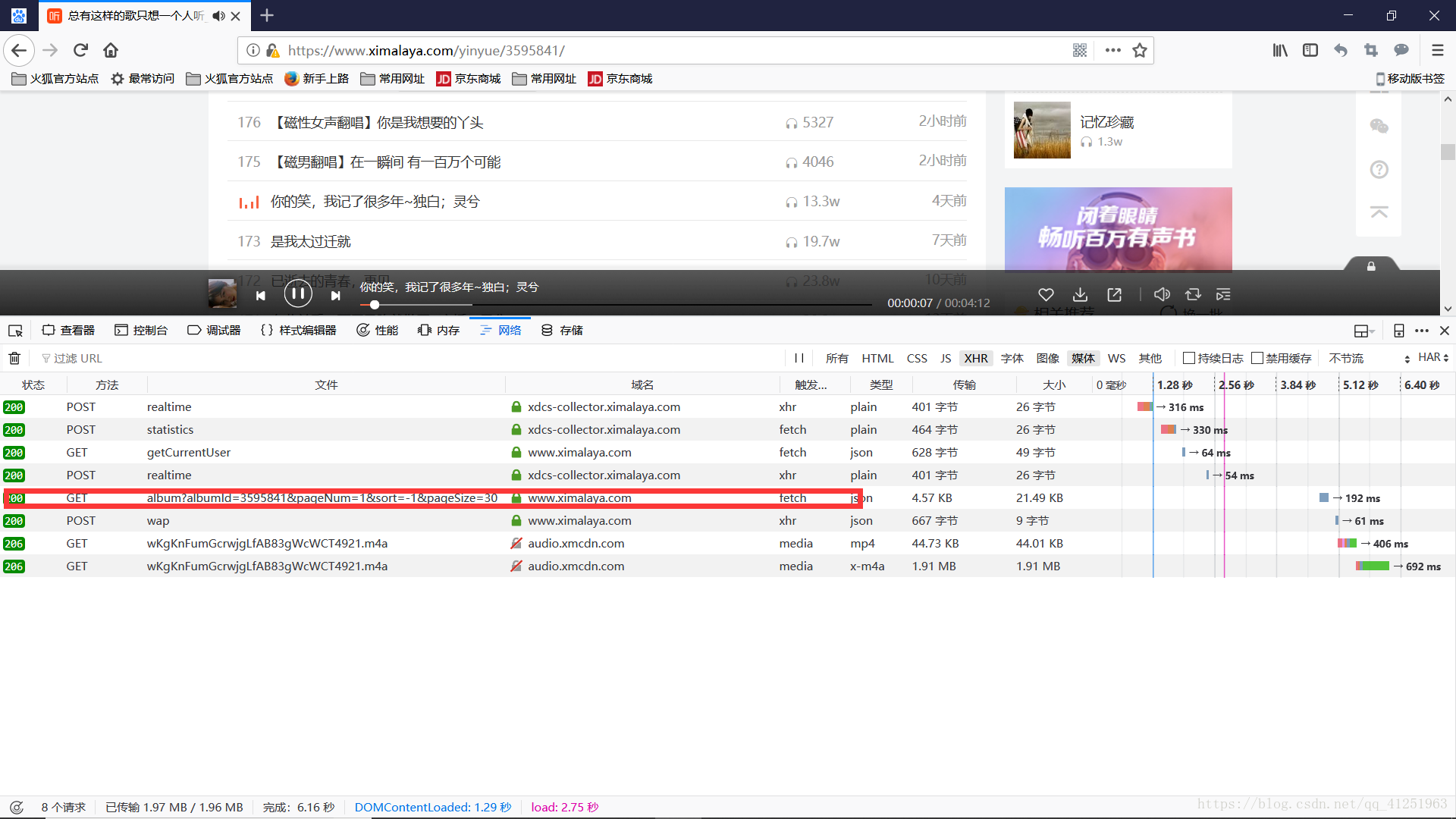
注意请求头部分的网址,并观察网址结构。点击响应按钮,查看一下内容。
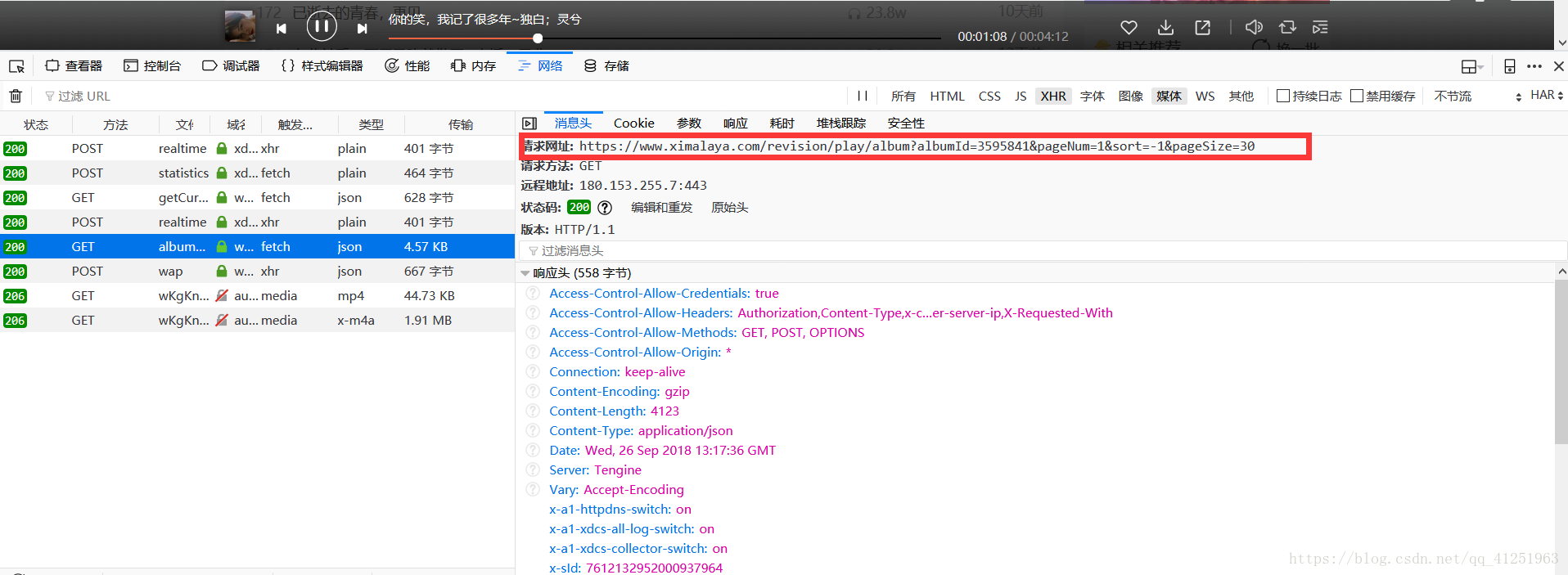
我们发现里面是一个json串,里面有音乐的一些信息,我们想要下载音乐,因此只需要音乐 名,及音乐地址。红色标记部分src为音乐地址。
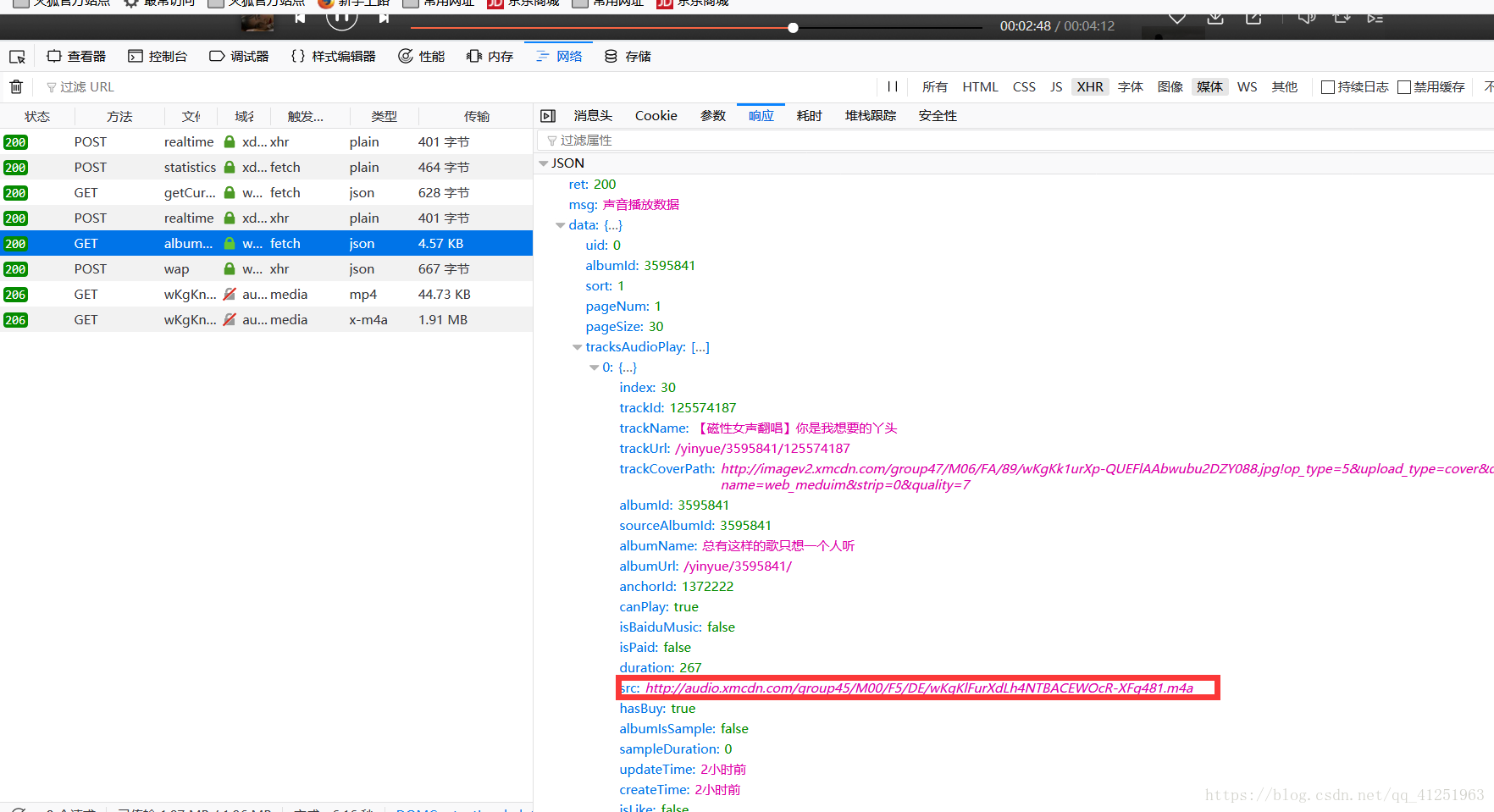
我们访问一下这个音乐地址,看看内容:恰好是音乐,说明我们寻找的数据正确
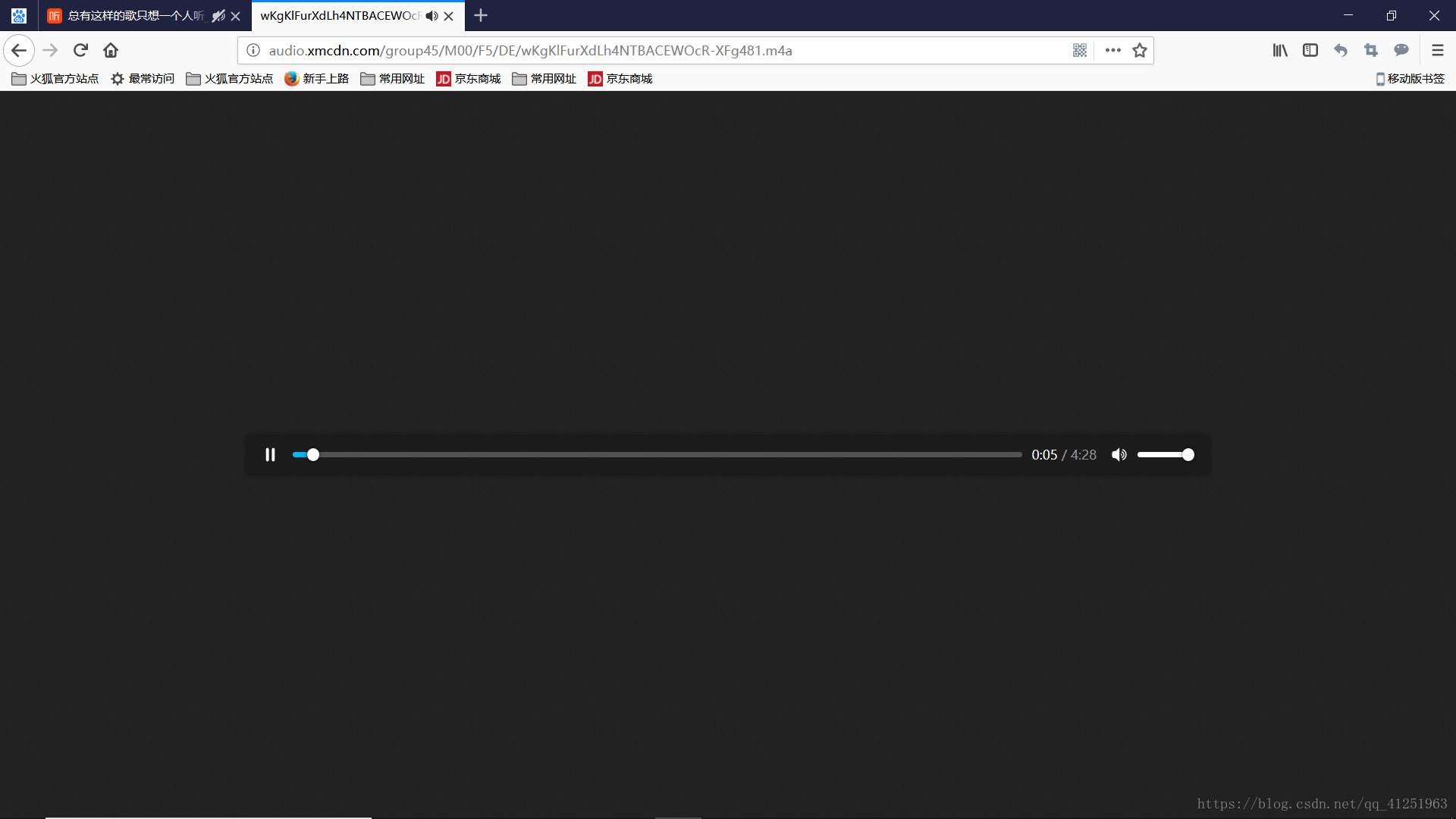
这样下载这首音乐就非常简单了,请求网址https://www.ximalaya.com/revision/play/album?albumId=3595841&pageNum=1&sort=-1&pageSize=30并获取json串中的音乐地址src,直接写入数据到本地。
这是获取一首音乐的方法,获取整个界面的音乐只需遍历json串中的src数据。
html=requests.get(url,headers=headers)
ret=html.content.decode()#返回字符串类型数据
#print(ret)
result = json.loads(ret)
#print(result['data']['tracksAudioPlay'][0]['src'])
for i in result['data']['tracksAudioPlay']:
#print(i['src'])
src=i['src']
name=i['trackName']
#print(name)
#保存数据
with open("./{}.mp3".format(name),'ab')as f:
music=requests.get(src,headers=headers)
f.write(music.content)
想要把六个页面的所有音乐都爬取下来,就要观察一下其他页面的网址。采用上述同样的抓取方法。这是第二页的
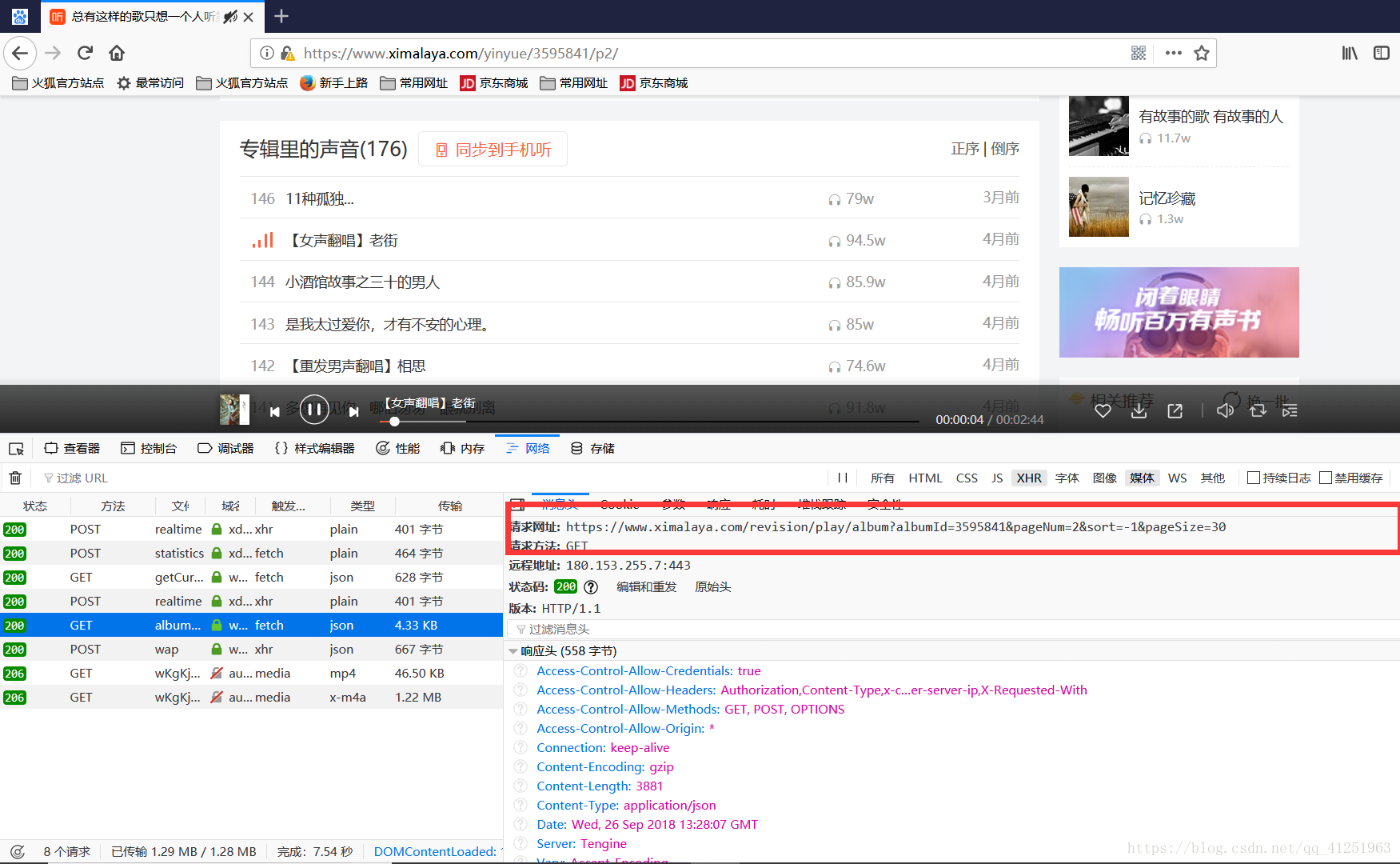
第三页的:
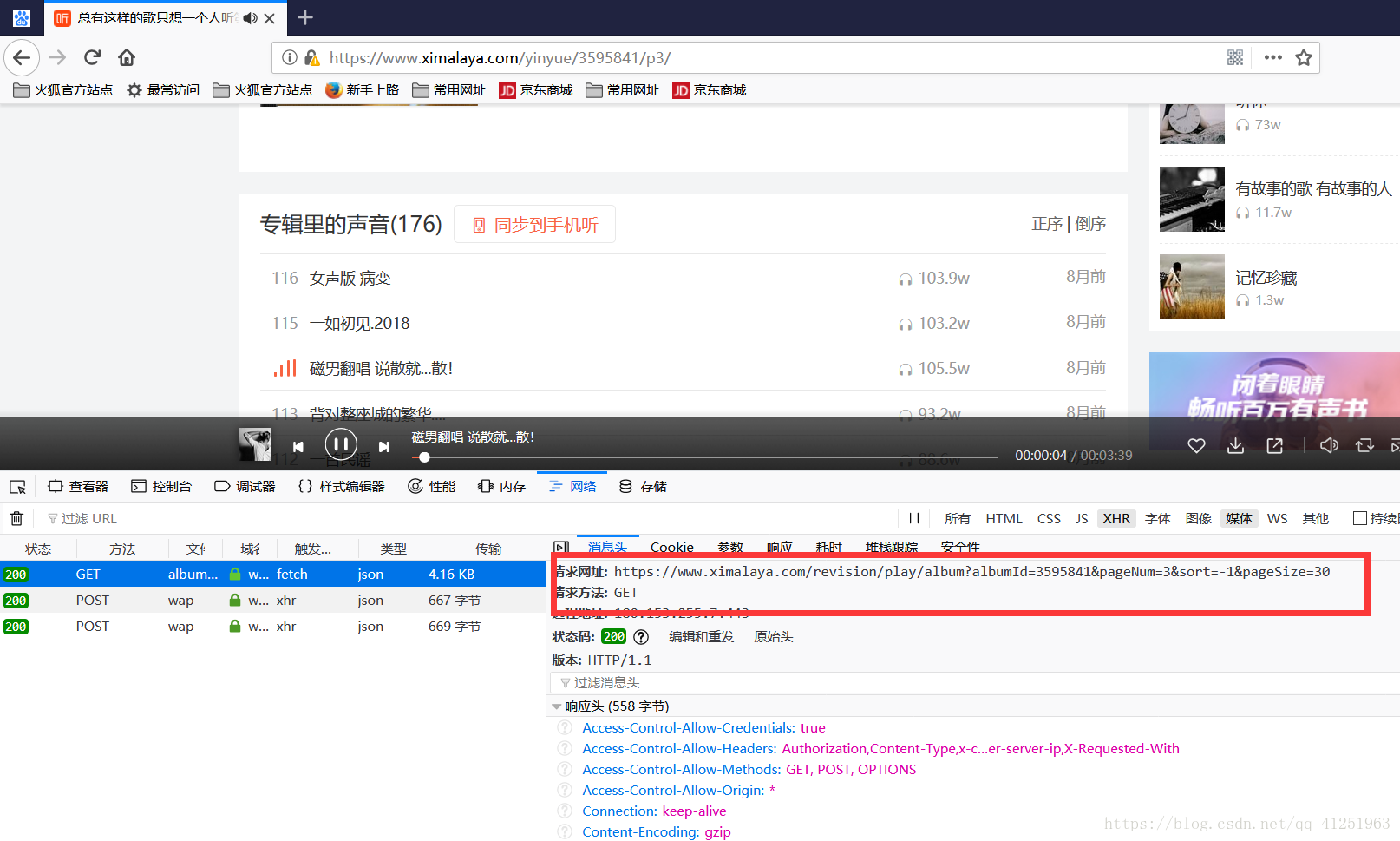
这样就发现了规律,因此可以写一个通用表达式,https://www.ximalaya.com/revision/play/album?albumId=3595841&pageNum="+(str)(a)+"&sort=-1&pageSize=30其中a是传入的参数,也就是第几页。
这样我们就完成了对我们需求的分析。
所有代码:
#爬取喜马拉雅音乐排行榜中所有的音乐
import requests
import json,time
#https://www.ximalaya.com/revision/play/album?albumId=3595841&pageNum=3&sort=-1&pageSize=30
def xima(a):
url = "https://www.ximalaya.com/revision/play/album?albumId=3595841&pageNum="+(str)(a)+"&sort=-1&pageSize=30"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:62.0) Gecko/20100101 Firefox/62.0',
}
html=requests.get(url,headers=headers)
ret=html.content.decode()#返回字符串类型数据
#print(ret)
result = json.loads(ret)
#print(result['data']['tracksAudioPlay'][0]['src'])
for i in result['data']['tracksAudioPlay']:
#print(i['src'])
src=i['src']
name=i['trackName']
#print(name)
#保存数据
with open("./{}.mp3".format(name),'ab')as f:
music=requests.get(src,headers=headers)
f.write(music.content)
if __name__ == '__main__':
for i in range(1,7):
xima(i)
time.sleep(5)
去掉所有注释,代码非常简单。只是简单的json数据获取,文件写入,time.sleep()控制速度。


















 7019
7019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











