






 本文介绍了一种将网络抓取的Headers快速转换为Python字典的方法,方便爬虫开发过程中模拟请求头。通过简单的代码实现,可以有效提高爬虫开发效率。
本文介绍了一种将网络抓取的Headers快速转换为Python字典的方法,方便爬虫开发过程中模拟请求头。通过简单的代码实现,可以有效提高爬虫开发效率。
爬虫就是模拟客服端发送请求,Headers是模拟发送请求的重要参数之一。浏览器抓包,和fiddle抓包是我们常用的几种方式之一。不过我们用工具抓到的Headers不是字典,如下图。
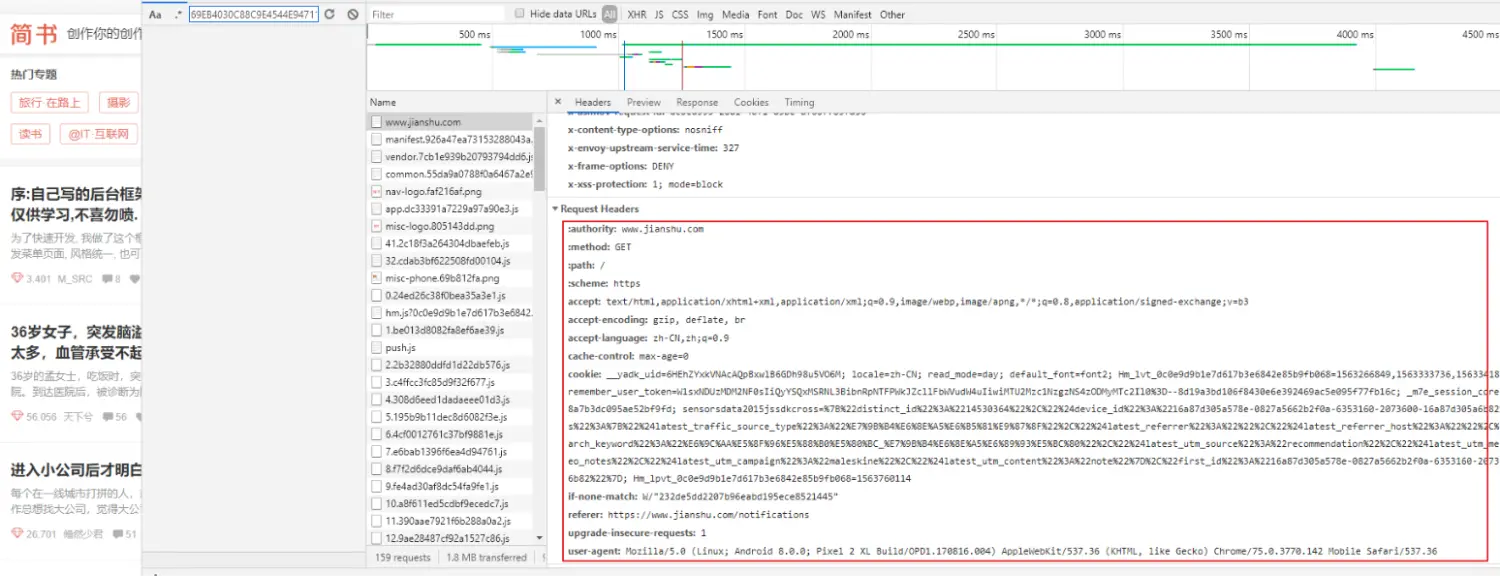
浏览器查看headers

fiddle查看headers
平常都需要手动一条一条的添加到我们的代码中,接下来介绍一种方法能将网络抓取到的Headers一键转换成字典形式的Headers
Headers_str = '''shopId: 0
orderPlatform:
mtWmPoiId: 973451228604358
source: shoplist
address:
cityId:
channel: 6
gpsLng: 120.096157
gpsLat: 30.306544
uuid: 69EB4030C88C9E4544E94711CD53F6F128516E412FCCA96BDCD9D3B6470A477A
platform: 3
partner: 4
originUrl: https://h5.waimai.meituan.com/waimai/mindex/menu?dpShopId=&mtShopId=973451228604358&utm_source=&source=shoplist&initialLat=30.307573&initialLng=120.097436&actualLat=30.306544&actualLng=120.096157
riskLevel: 71
optimusCode: 10
wm_latitude: 31238195
wm_longitude: 121502262
wm_actual_latitude: 30337453
wm_actual_longitude: 120120594
openh5_uuid: 69EB4030C88C9E4544E94711CD53F6F128516E412FCCA96BDCD9D3B6470A477A
_token: '''
{i.split(':')[0].strip(): i.split(':')[1].strip() if i.split(':')[1] else '' for i in a.split('\n') if i}
Out[8]:
{'shopId': '0',
'orderPlatform': '',
'mtWmPoiId': '973451228604358',
'source': 'shoplist',
'address': '',
'cityId': '',
'channel': '6',
'gpsLng': '120.096157',
'gpsLat': '30.306544',
'uuid': '69EB4030C88C9E4544E94711CD53F6F128516E412FCCA96BDCD9D3B6470A477A',
'platform': '3',
'partner': '4',
'originUrl': 'https',
'riskLevel': '71',
'optimusCode': '10',
'wm_latitude': '31238195',
'wm_longitude': '121502262',
'wm_actual_latitude': '30337453',
'wm_actual_longitude': '120120594',
'openh5_uuid': '69EB4030C88C9E4544E94711CD53F6F128516E412FCCA96BDCD9D3B6470A477A',
'_token': ''}
代码
{i.split(':')[0].strip(): i.split(':')[1].strip() if i.split(':')[1] else '' for i in a.split('\n') if i}
注意
'''后面不需要手动换行,否则第一个键值对为空。
python爬虫必备工具箱 url解析url提取参数
Scrapy-Redis手动添加去重请求(指纹)
Python 2019练习题,笔试题合集(持续更新)

















 3337
3337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









