







一、 实验目的
设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。
二、 实验内容
2.1 待分析的简单词法
(1)关键字:
begin if then while do end
所有关键字都是小写
(2) 运算符和界符
: = + - * / < <= <> > >= = ; ( ) #
(3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义:
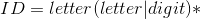
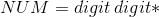
(4)空格有空白、制表符和换行符组成。空格一般用来分隔、运算符、界符和关键字,词法分析阶段通常被忽略。
三、运行结果:
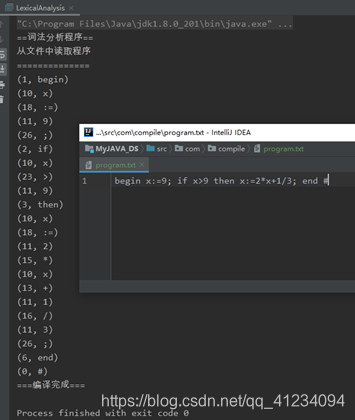
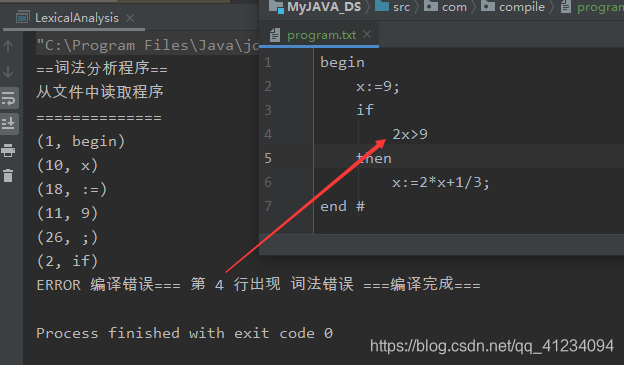
程序流程图
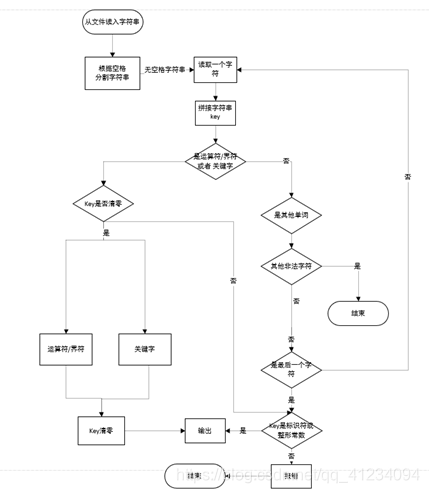
上面是自己画的流程图
下面是从网上copy 下来的转换图:(如果侵权了评论我 删除)
原文:https://wenku.baidu.com/view/aede6c4a0a1c59eef8c75fbfc77da26924c5964c.html
程序代码
注释还是比较多的尼,,但是bug 是一定有的,,,基本功能实现了
package com.compile;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
/**
* @author JimmyYang.MJ
* @Date: 2020/4/10 9:16
*/
public class LexicalAnalysis {
/**标识符 ID >> 正则表达式*/
final static String ID = "\\p{Alpha}(\\p{Alpha}|\\d)*";
/** 整形常数 NUM >> 正则表达式*/
final static String NUM = "\\d\\d*";
/** token 词法单元
* <词符号, 种别码> */
/** 关键字 token*/
static Map<String, Integer> TOKEN_KEYWORDS;
/** 运算符/界符 token */
static Map<String, Integer> TOKEN_OPERATOR_BOUNDARY;
/** 其他单词 token*/
static Map<String, Integer> TOKEN_ID_SUM;
/** 文件根目录*/
static final String ROOT_DIRECTORY = "D:/IDEA-workspace/MyJAVA_DS/src/com/compile/";
/**
* 初始化 token 单元
*/
private static void initToken(){
TOKEN_KEYWORDS = new HashMap<String, Integer>(){
{
put("begin", 1);
put("if", 2);
put("then", 3);
put("while", 4);
put("do", 5);
put("end", 6);
}
};
TOKEN_OPERATOR_BOUNDARY= new HashMap<String, Integer>(){
{
put("+", 13);
put("-", 14);
put("*", 15);
put("/", 16);
put(":", 17);
put(":=", 18);
put("<", 20);
put("<>", 21);
put("<=", 22);
put(">", 23);
put(">=", 24);
put("=", 25);
put(";", 26);
put("(", 27);
put(")", 28);
put("#", 0);
}
};
TOKEN_ID_SUM= new HashMap<String, Integer>(){
{
put(ID, 10);
put(NUM, 11);
}
};
}
/**
* 读 源程序 文件
*/
public static void ReadFile1() {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
try {
fis = new FileInputStream(ROOT_DIRECTORY + "program.txt");
isr = new InputStreamReader(fis, "UTF-8"); // 转化类
br = new BufferedReader(isr); // 装饰类
String line;
/** 记录 程序 行数 */
int countLine = 1;
while ((line = br.readLine()) != null) { // 每次读取一行
boolean answer = lexicalAnalysis(line);
if(answer == false){
System.out.printf("ERROR 编译错误=== 第 %d 行出现 词法错误 ", countLine);
break;
}
countLine++;
}
System.out.printf("===编译完成===");
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
br.close(); // 关闭最后一个类,会将所有的底层流都关闭
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
/** 判断key是否是其他单词*/
private static boolean isIDOrSUM(String key){
if (key.matches(ID) ) {
System.out.printf("(%d, %s)\n", TOKEN_ID_SUM.get(ID), key);
}else if (key.matches(NUM)) {
System.out.printf("(%d, %s)\n", TOKEN_ID_SUM.get(NUM), key);
}else {
return false;
}
return true;
}
/**
* 进行 词法分析
* @param word 要分析的字符串
* @return 结果
*/
public static boolean lexicalAnalysis(String word){
word = word.trim(); // 去 首尾 空格
String[] strings = word.split("\\p{Space}+"); // 保证处理的字符串没有空格
for (String string : strings) {
/** 3种情况:
* 1. 关键字 == end (关键字的后面一定是空格 )
* 2. 运算符/ 分界符 == continue
* 3. 其他单词 == continue
*/
String key = "";
for (int i = 0; i < string.length(); i++){
String indexChar = String.valueOf(string.charAt(i)) ;
/** 是 运算符 或者 关键字*/
if (TOKEN_OPERATOR_BOUNDARY.containsKey(indexChar) ||
TOKEN_KEYWORDS.containsKey(string.substring(i, string.length()))){
if (key.length() > 0) {
if (isIDOrSUM(key) == false) {
/** 词法错误 */
return false;
}
key = "";
}
if(TOKEN_OPERATOR_BOUNDARY.containsKey(indexChar)) {
/** 1. 是 运算符/分界符 */
key += indexChar;
if(i + 1 < string.length() && TOKEN_OPERATOR_BOUNDARY.containsKey(indexChar + string.charAt(i+1))){ // 运算分界符
key += string.charAt(++i);
}
System.out.printf("(%d, %s)\n",TOKEN_OPERATOR_BOUNDARY.get(key),key);
key = "";
}else if(TOKEN_KEYWORDS.containsKey(key = string.substring(i, string.length()))) {
/** 2. 是关键字*/
System.out.printf("(%d, %s)\n",TOKEN_KEYWORDS.get(key),key);
key = "";
break;
}
}else {
/** 是其他单词*/
key += indexChar;
/** 其他单词后面是 1. 换行,2. 运算符/界符 3. 其他单词
*/
if(i+1 >= string.length()){
if (isIDOrSUM(key) == false) {
/** 词法错误 */
return false;
}
}
}
}
}
return true;
}
public static void main(String[] args) {
initToken();
System.out.println("==词法分析程序==");
System.out.println("从文件中读取程序");
System.out.println("==============");
ReadFile1();
System.out.println();
}
}

















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









