







 本文深入探讨了数据库索引中的密集索引与稀疏索引概念,详细解释了两者在MySQL的不同存储引擎(MyISAM与InnoDB)中的应用及区别。文章还介绍了聚簇与非聚簇索引的特性,以及InnoDB如何选择主键作为密集索引。通过实例说明了索引覆盖的概念,以及在查询优化中的作用。
本文深入探讨了数据库索引中的密集索引与稀疏索引概念,详细解释了两者在MySQL的不同存储引擎(MyISAM与InnoDB)中的应用及区别。文章还介绍了聚簇与非聚簇索引的特性,以及InnoDB如何选择主键作为密集索引。通过实例说明了索引覆盖的概念,以及在查询优化中的作用。
这篇文章加了很多我的理解哈,反正网上的千篇一律,一股脑的写上我感觉也没怎么自己思考,要是有大佬看到哪里有错多谢大佬指正!!!
写在前面我自己理解的点:
- 我的理解是:
密集索引和稀疏索引和下面写的聚簇索引和非聚簇索引一样,只是索引的一种具体存储方式(怎么说呢,就是理解为B+Tree怎么具体存储的吧这样子),他们都不是索引的类型. - 针对于mysql而言,密集索引/稀疏索引 == 聚簇索引/非聚簇索引
密集索引
定义:叶子节点保存的不只是键和值,还保存了位于同一行记录里的其他列的信息,由于密集索引决定了表的物理排列顺序,一个表只有一个物理排列顺序,所以一个表只能创建一个密集索引
稀疏索引
定义:叶子节点仅保存了键位信息以及该行数据的地址,有的稀疏索引只保存了键位信息及其主键
对于稀疏索引,定位到叶子节点之后,仍然需要通过地址或者主键信息进一步定位到数据
密集索引和稀疏索引的区别
- 密集索引文件中的每个搜索码值都对应一个索引值.
- 稀疏索引文件只为索引码的某些值建立索引项.
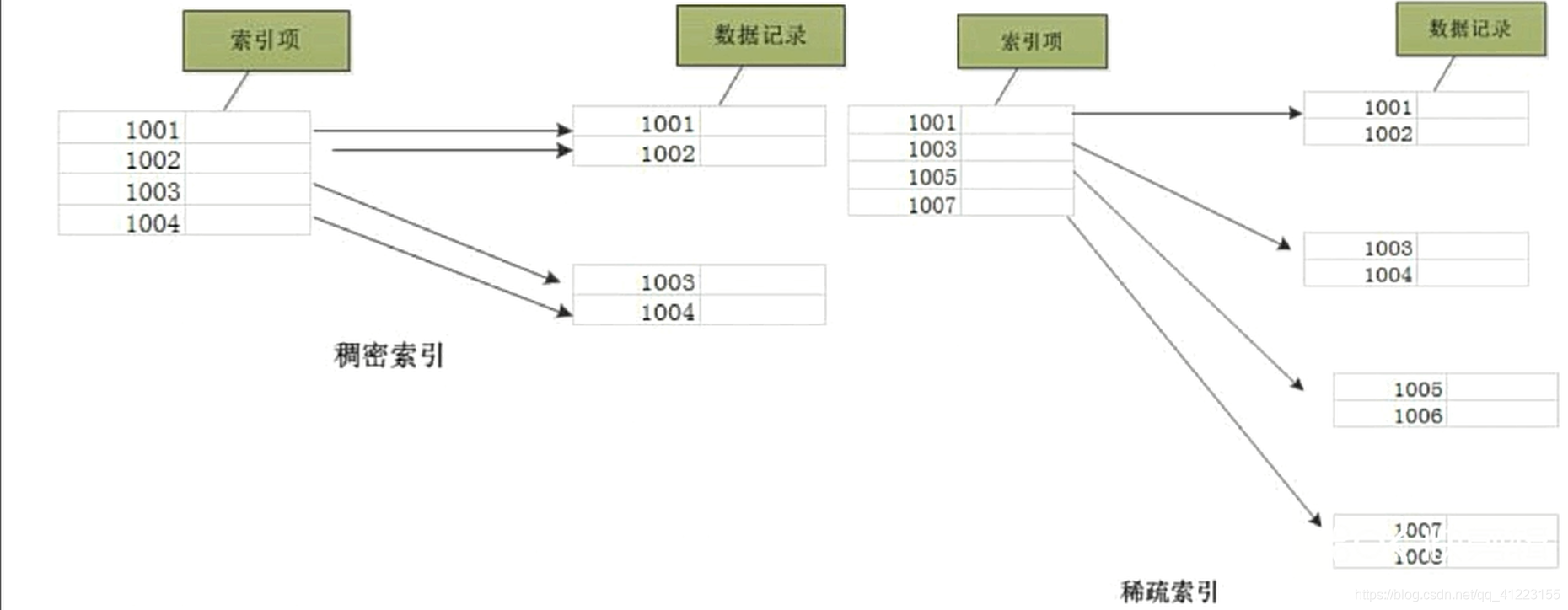
针对mysql的具体分析
mysql有两种主要的存储引擎:
- MyISAM: 它不管是主键索引,唯一索引还是普通索引或是全文索引,都是稀疏索引.
- InnoDB:它有且仅有一个密集索引.
InnoDB的索引选取规则
- 如果定义了一个主键,那么该主键则作为密集索引而存在.
- 如果没有定义主键,那么该表的第一个唯一非空索引则作为密集索引.
- 若不满足以上条件,InnoDB
内部会生成一个隐藏主键(该主键会被作为密集索引,这个主键是一个6个字节的列,该列的值会随着数据的插入而自增). - 也就是说,InnoDB必须有一个主键,而且该主键作为密集索引存在.
聚簇索引和非聚簇索引
如图所示(注意聚簇索引和非聚簇索引只是索引存储的两种方式,不是索引的类型哈):
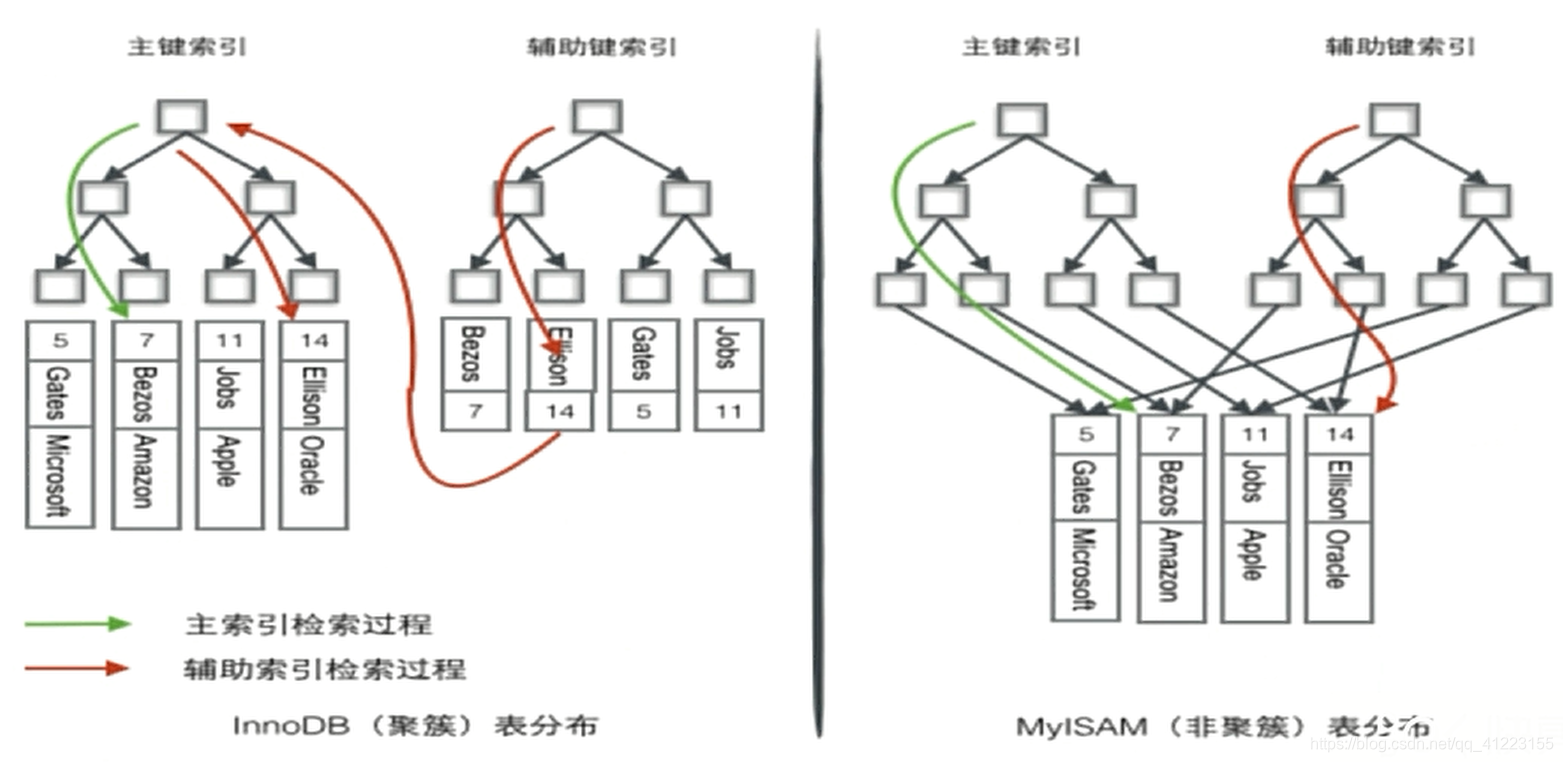
聚簇索引:可以理解为通过拼音的首字母查字典,a开头的汉字一定在f开头的汉字的后面,也就是说,首字母和汉字所在的位置是一一对应的,首字母在前的,汉字也在前这样子理解,对比上面的密集索引,是不是也是决定了表的物理排列顺序,所以只有一个聚簇索引表
聚簇索引的特点: 当你查数据的时候,如果需要通过一个辅助索引+主键索引,它查找辅助索引时,会在辅助索引的叶子节点找到主键的id,然后在主键索引树上通过主键id去找到数据. 这样的好处就是节省空间,只加载一次,而且只加载部分内容,这个我也没大懂,反正省空间记着就成吧.
非聚簇索引:可以理解为通过偏旁部首查字典,到时候的汉字不一定谁在前谁在后勒,比如广字头和单人旁的汉字,在字典里谁在前这个还真不好说.
非聚簇索引的特点: 不论你是通过主键索引还是通过辅助索引,都可以直接查找到数据,但是这样就很占用空间,因为它的数据和索引不是放在一起的,每次找一个数据,都要加载所有的数据.
InnoDB使用的是密集索引(聚簇索引),将主键组织到一棵B+Tree中,而行数据就存储在叶子节点上,因为InnoDB的主键索引和对应的数据是保存在同一个文件上的,所以检索的时候在加载叶子节点的主键进内存的同时,也加载了对应的数据,即若使用 select * from user where id = 14这样的条件查询主键,则按照B+Tree的检索算法就可以直接查找到对应的叶子节点并获取对应的行数据.
若使用**稀疏索引(非聚簇索引)**进行条件筛选,则需要进行两个步骤(例如 where name = Ellison):
- 在稀疏索引的
辅助键索引B+Tree中检索name为指定值的主键,比如检索上图中的Ellison,然后它就可以得到主键信息,获取到主键信息只有,就要开始第二步. - 根据主键信息
id=14去主键索引B+Tree树中,按照B+Tree的检索算法去查找对应的叶子节点然后获取其对应的行数据.
MyISAM采用的都是稀疏索引,而且两棵B+Tree没有什么不同,节点的结构完全一致,只是存储的内容不一样而已.主键索引B+Tree存储的主键,而辅助键索引B+Tree存储的时辅助键,两棵树是互相独立的,并且表数据(由B+Tree的叶子节点中的地址指向)存储在其他地方,即索引和数据是分开存储的
索引的分类(这个我发现各有各的说法,我就综合了一下)
- 单列索引:一个索引只包含一列,但是可以有多个单列索引
- 唯一索引:列值唯一,可以为空
- 主键索引: 列值唯一,且不能为空
- 普通索引:只是为了加速,没有唯一和是否为空限制
- 联合索引(也叫组合索引):一个索引包含两列及以上.
- 全文索引:对文本的内容进行分词,进行搜索,搜索引擎用的就是这个.
索引覆盖和覆盖索引’’
索引覆盖和覆盖索引是同一个东西
通俗的说就是需要的数据通过索引就能找到,不需要从磁盘中去拿
就比如说我将id设置为主键索引,name为辅助索引,我要拿name=f的name和id的值的时候,可以直接通过索引name拿到,因为直接存在了B+Tree里,就很快嘛.

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









