







 本文介绍了一个使用Python实现的多线程爬虫项目,该爬虫能够抓取并解析指定网站上的笑话内容,将其存储为CSV文件。通过导入requests、threading、csv等模块,结合lxml库进行HTML解析,项目实现了高效的数据抓取和存储。
本文介绍了一个使用Python实现的多线程爬虫项目,该爬虫能够抓取并解析指定网站上的笑话内容,将其存储为CSV文件。通过导入requests、threading、csv等模块,结合lxml库进行HTML解析,项目实现了高效的数据抓取和存储。
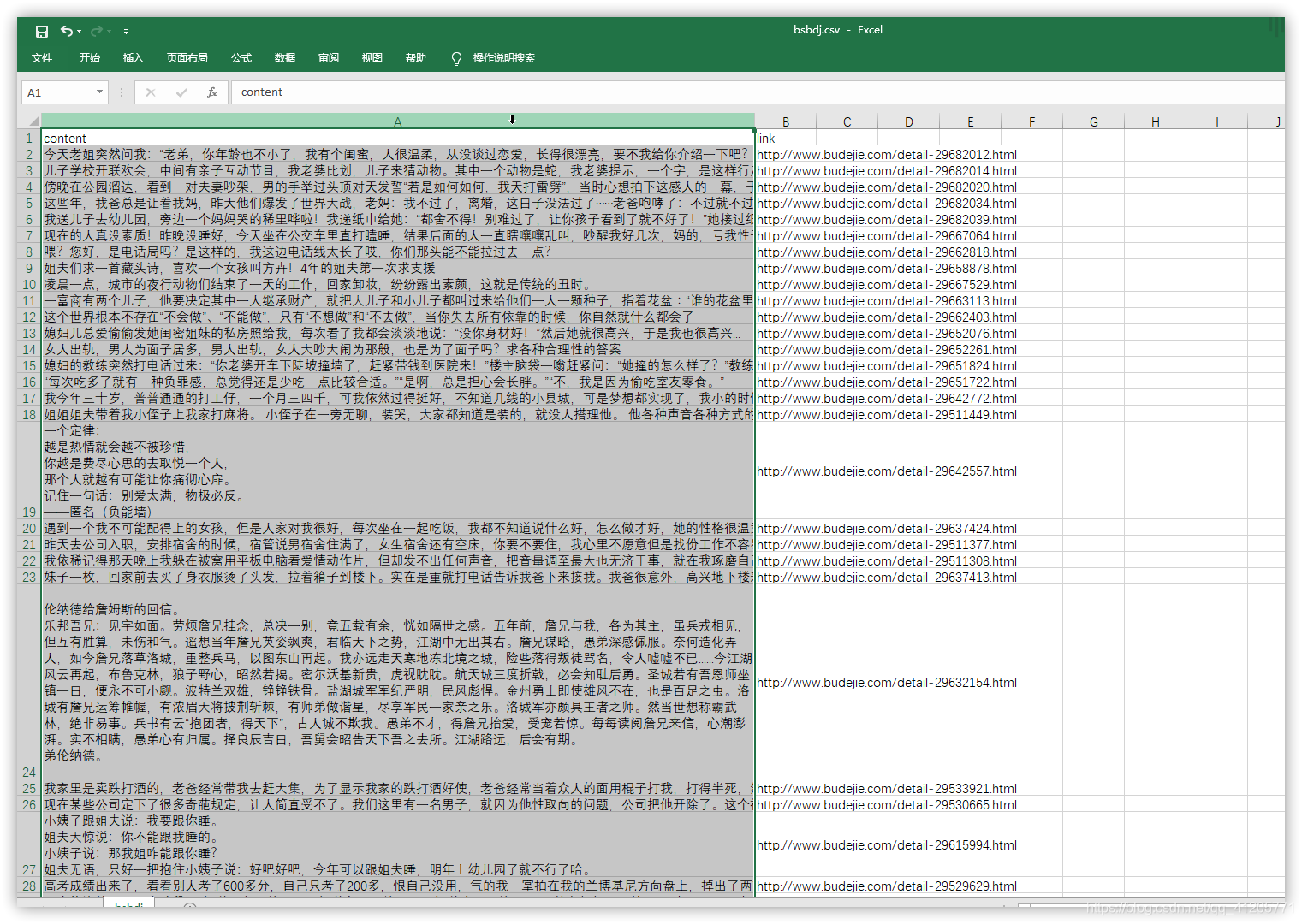
并且可以导出到csv文件查看。
复制粘贴运行即可。
2019年8月11日测试可用
import requests,threading,csv
from lxml import etree
from queue import Queue
class MYSpider(threading.Thread):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
def __init__(self,page_queue,joke_queue,*args,**kwargs):
super(MYSpider, self).__init__(*args, **kwargs)
self.joke_queue = joke_queue
self.page_queue = page_queue
self.base_domain = 'http://www.budejie.com'
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
response = requests.get(url,headers=self.headers)
html=etree.HTML(response.content.decode('utf-8'))
descs = html.xpath("//div[@class='j-r-list-c-desc']")
for desc in descs:
jokes = desc.xpath(".//text()")
joke = "\n".join(jokes).strip()
link = self.base_domain + desc.xpath(".//a/@href")[0]
self.joke_queue.put((joke, link))
print('=' * 30 + "第%s页下载完成!" % url.split('/')[-1] + "=" * 30)
class MYWriter(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
def __init__(self,joke_queue,writer,gLock,*args,**kwargs):
super(MYWriter, self).__init__(*args, **kwargs)
self.joke_queue = joke_queue
self.writer = writer
self.lock = gLock
def run(self):
while True:
try:
joke, link = self.joke_queue.get(timeout=6)
self.lock.acquire()
self.writer.writerow((joke,link))
self.lock.release()
print("保存一条")
except:
print("终止")
break
def main():
page_queue = Queue(10)
joke_queue = Queue(500)
gLock = threading.Lock()
fp=open('bsbdj.csv','a',newline='',encoding='utf-8-sig')
writer = csv.writer(fp)
writer.writerow(('content','link'))
for x in range (1,11):
url = 'http://www.budejie.com/text/%d'%x
page_queue.put(url)
for x in range(5):
t = MYSpider(page_queue, joke_queue)
t.start()
for x in range(5):
t = MYWriter(joke_queue, writer, gLock)
t.start(name="写进程%d"%x)
if __name__== '__main__':
main()
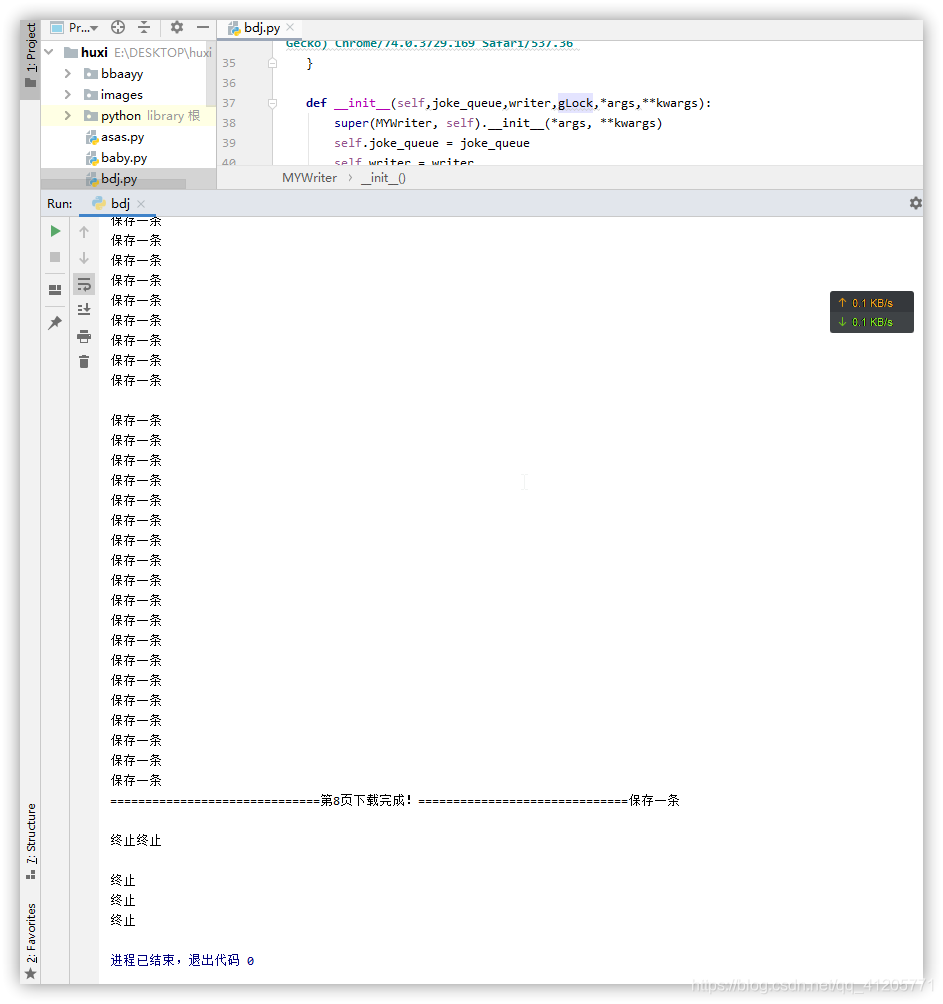
运行截图:

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









