






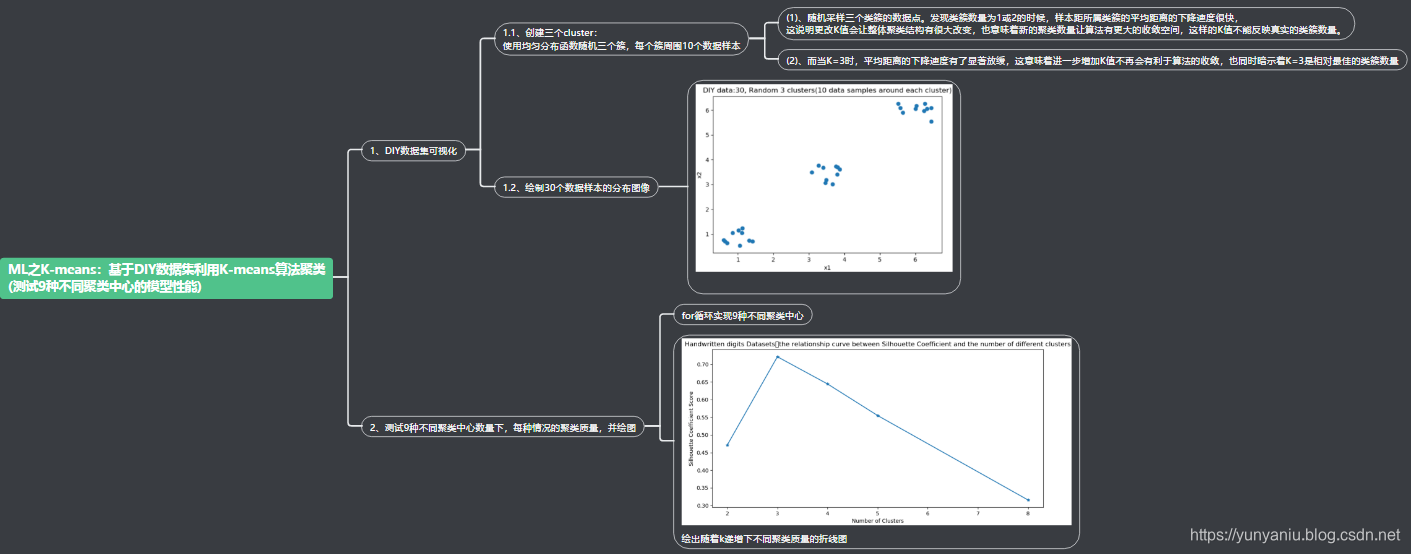
 本文通过创建DIY数据集,使用K-means算法进行聚类分析,测试了9种不同聚类中心数量下的模型性能,展示了如何选择最优的K值。
本文通过创建DIY数据集,使用K-means算法进行聚类分析,测试了9种不同聚类中心数量下的模型性能,展示了如何选择最优的K值。
ML之K-means:基于DIY数据集利用K-means算法聚类(测试9种不同聚类中心的模型性能)
目录
输出结果
设计思路
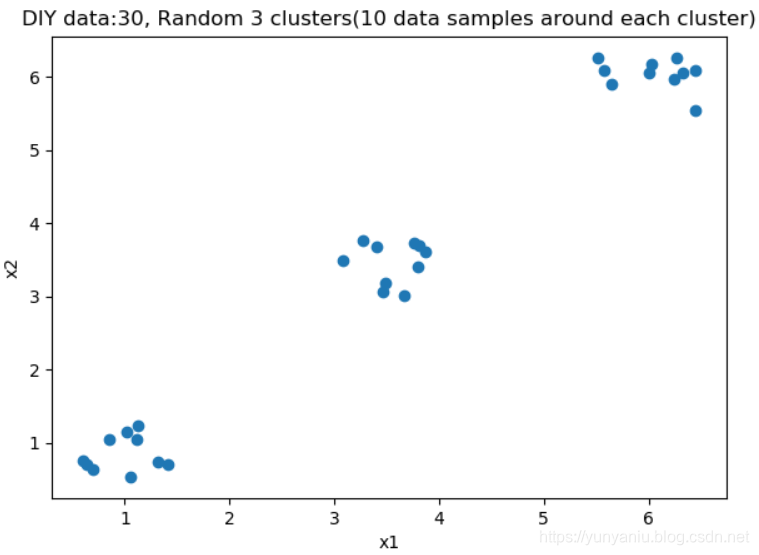
- 1、使用均匀分布函数随机三个簇,每个簇周围10个数据样本。
- 2、绘制30个数据样本的分布图像。
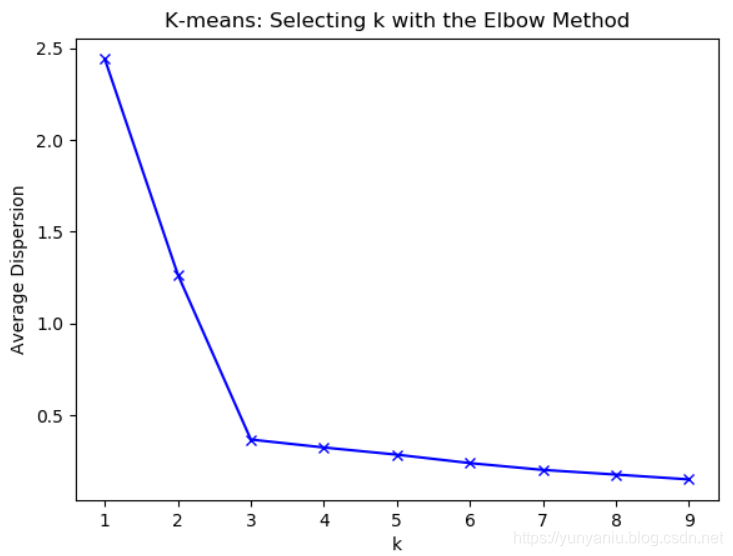
- 3、测试9种不同聚类中心数量下,每种情况的聚类质量,并作图。
实现代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
#1、使用均匀分布函数随机三个簇,每个簇周围10个数据样本。
cluster1 = np.random.uniform(0.5, 1.5, (2, 10))
cluster2 = np.random.uniform(5.5, 6.5, (2, 10))
cluster3 = np.random.uniform(3.0, 4.0, (2, 10))
#2、绘制30个数据样本的分布图像。
X = np.hstack((cluster1, cluster2, cluster3)).T
plt.scatter(X[:,0], X[:, 1])
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('DIY data:30, Random 3 clusters(10 data samples around each cluster)')
plt.show()
#3、测试9种不同聚类中心数量下,每种情况的聚类质量,并作图。
K = range(1, 10)
meandistortions = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
meandistortions.append(sum(np.min(cdist(X, kmeans.cluster_centers_, 'euclidean'), axis=1))/X.shape[0])
plt.plot(K, meandistortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Average Dispersion')
plt.title('K-means: Selecting k with the Elbow Method')
plt.show()



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











