







前言:不知不觉已经将近八个月没有更新我的博客了,现在已经大四了,寒假期间碰上武汉这个疫情,但是毕设的老师非常负责,在寒假也没有放松对我们的要求,于上周要求我阅读10篇关于神经网络的文献,提出改进方案,遂成此文。
目录
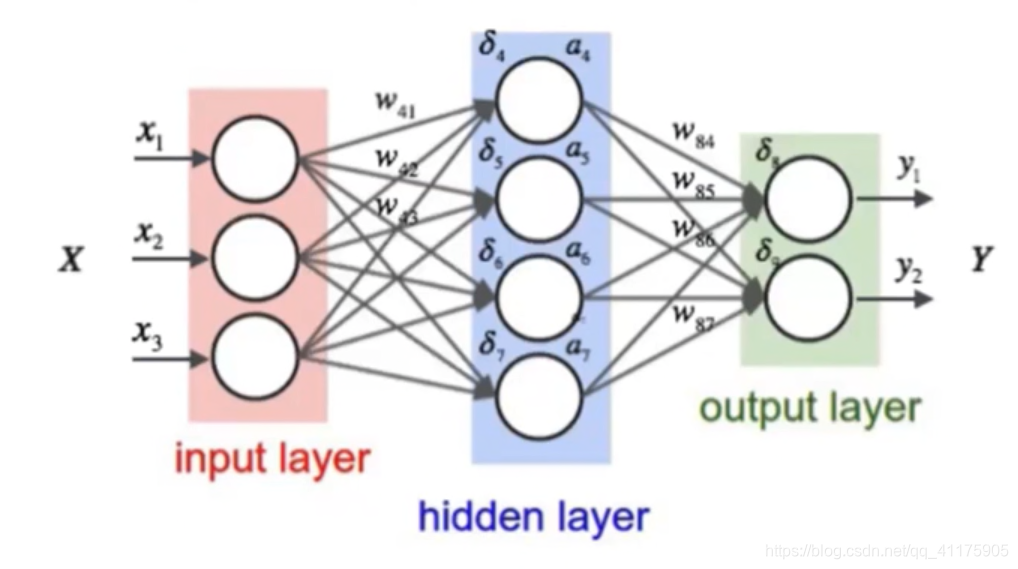
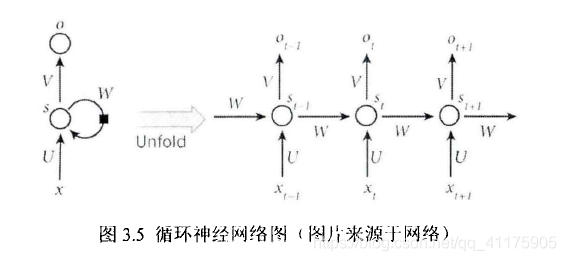
1、神经网络之间的区别
| 机器学习种类 | BP | RNN | LSTM | GRU |
| 原理图 |
|
|
|
|
| 公式 | NULL |
|
|
|
| 联系 | 具有非线性、自主学习能力、联想记忆能力、自适应性 | |||
| 区别 | 有3层,结构简单,无法处理时序数据 网络参数少,收敛速度慢,需要迭代的次数多,算法的准确度和预测精度相对较低,并且鲁棒性差。 | 在BP的基础上加了一个循环层,有一定的记忆性,但是记忆时间较短,训练难度较大;容易出现梯度爆炸和梯度消失的现象 | 在RNN的基础上隐藏层增加了三个门控以及一个细胞状态,使得信息有选择性的传递,优点:可以有效解决长期依赖的问题,也可以缓解梯度爆炸和梯度消失 缺点:但网络结构复杂,网络参数较多,复杂度增加 | (1)GRU算法是LSTM的变体,隐藏层在RNN基础上增加了更新们和重置门两个门控,也可以理解成将LSTM中的输入门和遗忘门合成了一个更新门 (2)更新门有助于捕捉中长期关系依赖关系,重置门有助于捕捉短期依赖关系。(3)更新门用于控制前一时刻的状态信息保留到当前状态中的程度,更新门值越大表示前一刻的状态信息保留越多;重置门用于确定是否要结合当前状态与先前的信息,重置门值越小说明忽略的信息越多 优点:需要迭代更新的参数也减少了,优化了网络结构,且计算效果与LSTM一样的好
|
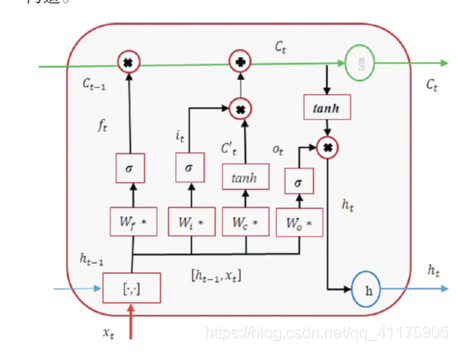
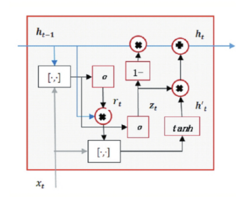
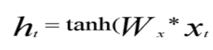
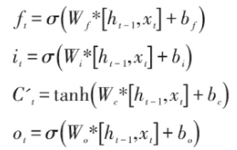
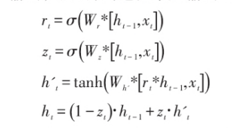
2、LSTM和GRU的详细区别
(1)LSTM的三个门控和细胞状态
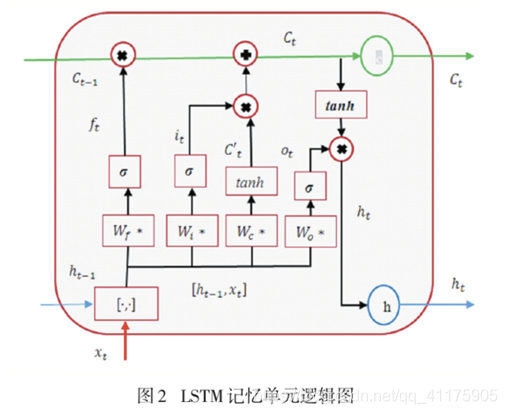
(a)遗忘门:将上一层的输出和本层的输入联合起来乘以权重,然后经过一个sigmoid函数,sigmoid为0表示忘记
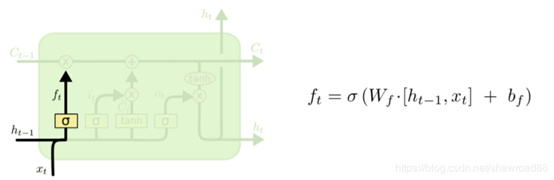
(b)输入门、细胞状态: C_{t-1}就是来自上一层记忆,我们现在要计算本层传给下一层的记忆 C_t
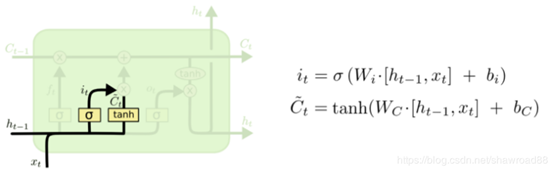
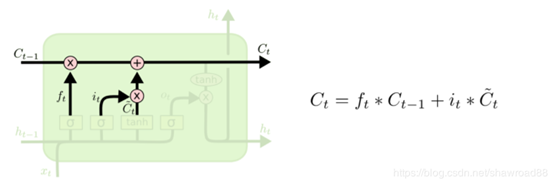
当其输出趋于0时,过去的信息就被遗忘,当其输出趋于1时,过去的信息得以保留
(c)输出门
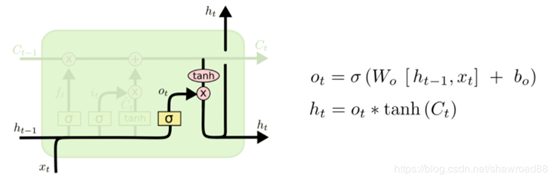
(2)GRU的两个门控
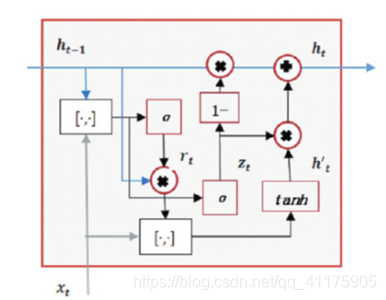
(a)更新门:是用来控制前一个时刻的信息被带入到当前时刻状态的程度。 更新门的值越大说明前一时刻的状态信息带入越多
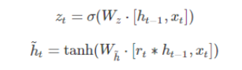
(b)重置门:用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
![]()
(c)输出
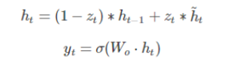
(3)LSTM和GRU的区别
(a)GRU比LSTM的参数少,所以容易收敛,但是数据集较大的时候,LSTM的表达性能比GRU好
(b)一般数据集上,二者性能相当
(c)GRU直接将hidden state传给下一个单元,而LSTM则用memory cell把hidden state包装起来
3、改进方案
(1)训练过程的优化
用于神经网络的训练算法,用于更新网络参数,使损失函数近似最小,输出逼近最优值。
优化重点:使用何种迭代方法进行迭代,依次来优化学习速率,让网络用最快的训练次数达到最优,并防止过拟合。
(a) 梯度下降(GD):批量梯度下降法、随机梯度下降法、小批量梯度下降法
原理:对损失函数求导,以修正参数,沿着梯度下降的方向,寻找最优解。
| 梯度方法 | BGD | SGD | MBGD |
| 特点 | 每一次迭代都计算所有样本的损失总和,再求偏导,更新参数。 优点:得到全局最优解,且迭代次数少 缺点:如果样本数目很多时,训练速度会减慢 | 每次迭代随机选取其中的一个样本进行训练,以达到最优值 优点:计算量较小,训练速度快 缺点:准确率低,不一定是全局最优解,且迭代次数较多 | 左边两种方法的折中,在每一次更新迭代时随机选取一部分样本计算损失,进行求导 优点:速度快,又可以保持准确率 |
(b)Adagrad、RMSProp、Adam可以实现动态调整学习率
| 优化器 | GD | Adagrad | RMSProp | Adam |
| 公式 |
|
|
|
|
| 特点 | 学习速率提前设定且不可更改,有三种梯度消失可选 | 需要手动设置全局学习率,动态调整学习率,但随着更新总距离的增多,学习速率会逐渐减慢,后期会非常小,调节效果非常弱 | 动态调整学习速率,学习速率后期不至于下降的太快,可以解决Adagrad中学习速率后期下降到极小值的问题。 此方法在RNN中表现很好,适合处理非平稳目标。 缺点:依旧需要设置全局初始学习速率,且多了一个参数 | 在RMSProp算法中加入了人动量项,增加了参数,也是动态调整学习速率 |
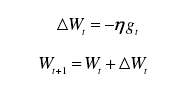
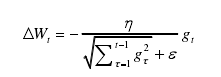
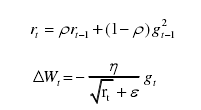
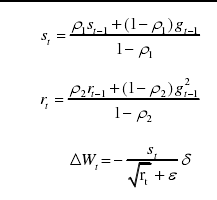
(2)过拟合问题的解决
过拟合出现的原因:随着层数以及各层神经元个数的增加,模型的参数个数也会极快的增加,参数过多导致过拟合
过拟合定义:训练数据拟合效果好,但在验证集上很差,即模型的泛化能力差。
解决办法:Dropout、L2正则化
(a)Dropout:通过按照一定概率丢弃隐层神经元
(b)L2正则化:通过增加额外的项到代价函数上,依次防止过拟合,提高模型的泛化能力
(3)数据输入方面的优化
(a)主成分分析:(可以设置对照组,测不同属性组和对准确率的一致性,从而达到辅助降维的目的)
使用主成分的原因:过多的输入会影响LSTM深度神经网络收敛速度和预测精度,采用主成分分析法对指标进行降维
主成分分析可以实现对复杂的数据集利用主成分分析法对数据进行降维,改变训练样本数量、改变时间序列的长度
(b)数据维度适当降低可以提高模型精度同时还能加快模型收敛速度;
(c)合理的序列长度也会提高模型精度,序列长度过长模型精度不能提高,容易出现梯度爆炸现象,序列长度过小,无法完全学习时间序列中隐藏的规律
(d)合理的样本数量能提高模型精度 ,样本数量过少时收敛速度较慢,且模型精度低
(e)归一化同一量纲,加快模型收敛速度

(4)模型结构
通过增加、减少隐藏层神经元数量;增加、减少隐藏层数目,

(5)合理的激活函数
可以缓解梯度消失,加快收敛速度
4、预测结果的评价指标


5、创新点
(1)针对梯度消失算法时,数据量多大时适合选择BGD,数据量多大时选择SGD,以MBGD作为对照组
(2)对于神经网络结构选取时,关于隐藏层的层数和神经元个数的选取,可以对不同数据量的数据集采用不同的隐藏层结构进行对比实验,以求找到设计神经结构的参考标准。
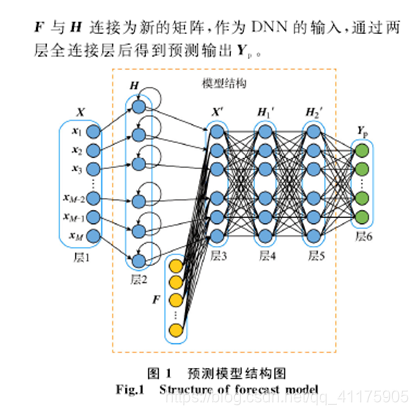
(3)GRU_NN模型:
提出背景:在实际应用中,数据中不仅包含具有时序性的历史数据,还包含其他如天气等非时序因素,仅使用GRU模型不能很好的学习数据中的隐藏规律


6、参考文献
[1] 基于LSTM深度神经网络的股市时间序列预测精度的影响因素研究_毛景慧
[2] 基于循环神经网络的熔盐炉温度预测_许路平
[3] 基于长短期记忆神经网络的收益率预测研究_付泉
[4] 基于GRU递归神经网络的城市道路超车预测_王浩
[5] LSTM的单变量短期家庭电力需求预测_王旭东
[6] 基于GRU神经网络的欧元兑美元汇率预测研究_李佳
[7] 基于GRU_NN模型的短期负荷预测方法_王增平
[8] 基于两种LSTM结构的文本情感分析_张玉环
[9] 基于GRU_RNN模型的城市主干道交通时间预测_张铭坤
[10] 基于Adam优化GRU神经网络的SCADA系统入侵检测方法_陈土生

















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









