







 文章介绍了如何利用PyTorch实现一个简单的线性模型,包括准备数据、定义模型、构造损失函数和优化器。通过`torch.nn.Linear`创建线性层,使用`MSELoss`作为损失函数,并应用SGD优化器进行权重更新。整个训练过程包括前馈、损失计算、反向传播和权重更新。最后,展示了如何获取模型参数并测试模型预测。
文章介绍了如何利用PyTorch实现一个简单的线性模型,包括准备数据、定义模型、构造损失函数和优化器。通过`torch.nn.Linear`创建线性层,使用`MSELoss`作为损失函数,并应用SGD优化器进行权重更新。整个训练过程包括前馈、损失计算、反向传播和权重更新。最后,展示了如何获取模型参数并测试模型预测。
感谢学习视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=5&vd_source=2314316d319741d0a2bc13b4ca76fae6
前面学到:
第一步: 确定我们的模型;
第二步:优化目标:定义损失函数(最终必须是一个标量值,这样才能去找怎样让它变得更小);
第三步:然后在 pytorch 进行优化时,需要用到前面学的SGD(随机梯度下降)【核心就是求出每一个权重损失关于权重的梯度】,然后用SGD对权重进行更新。
之前3节课实现了线性模型如何去训练、更新权重。本节主要内容是用 pytorch 提供的工具帮我们去实现一个简单的线性模型的过程。
介绍 module 【如何构造自己的神经网络】;
loss 【如何构造损失函数】;
以及如何构造随机梯度下降的优化器。
之前也用到了pytorch的一些功能: Tensor 、 forward : 前馈,计算这组样本带来的损失、backward:反馈,求出最终的梯度。更新权重、权重梯度清零。。。
用pytorch框架写的神经网络代码看起来复杂,但它有很强的弹性,可通过扩展构造出更复杂的神经网络。
线性回归是最简单的只有一个神经元的神经网络。
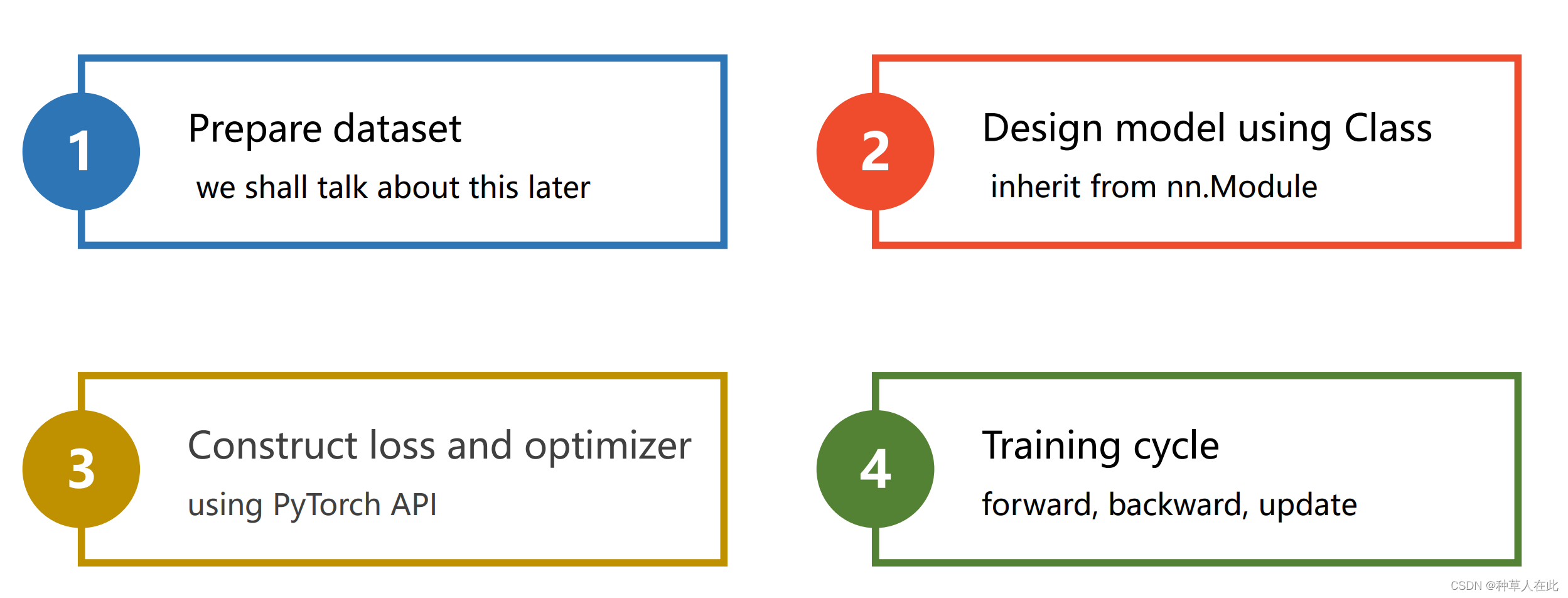
pytorch写神经网络:
第一步:准备/构造数据集;
第二步:设计模型用来计算 y hat(y_pred);
第三步:构造损失函数和优化器(loss、optimizer),使用pytorch的API【封装功能】构造用来计算损失的对象、用来优化的对象;
第四步:训练的周期。
准备数据

模型是 y_hat = w * x + b
import torch
# 之前用两个列表保存数据
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
# 现在用 torch的 Tensor,用mini-batch的风格
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
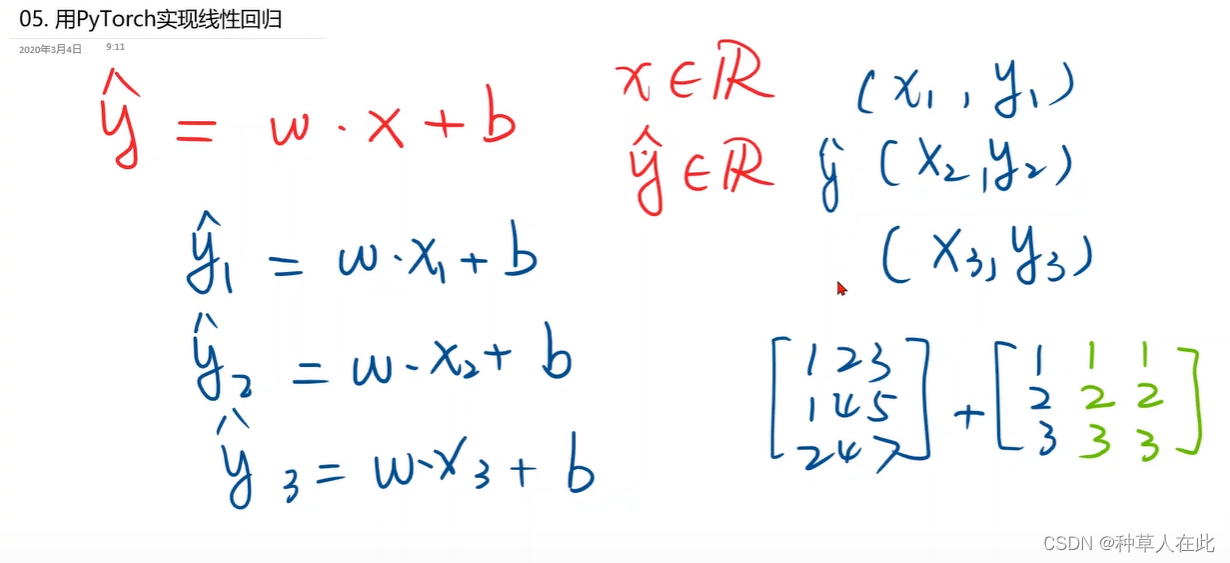
mini-batch 就是一次性把三个样本结果都求出来。
numpy有一个广播机制【就是一个矩阵+一个列向量,本身两者是无法相加的,但广播机制会自动将1;2;3 扩充成与另一个矩阵相同的大小,这样就可以完成运算】
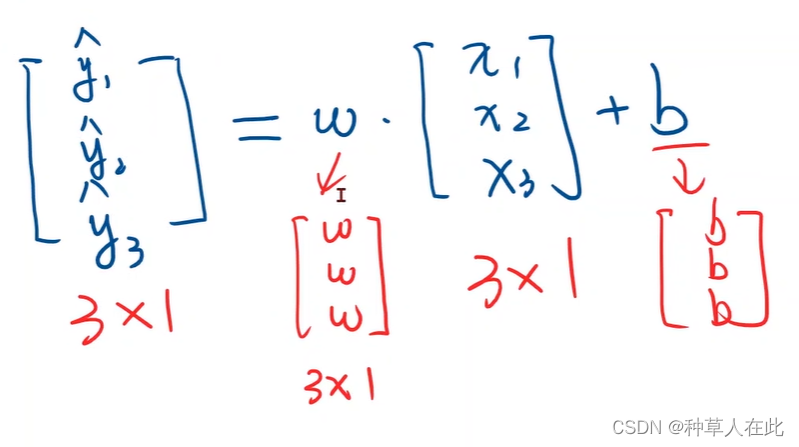
w和b自动广播成可运算的矩阵大小。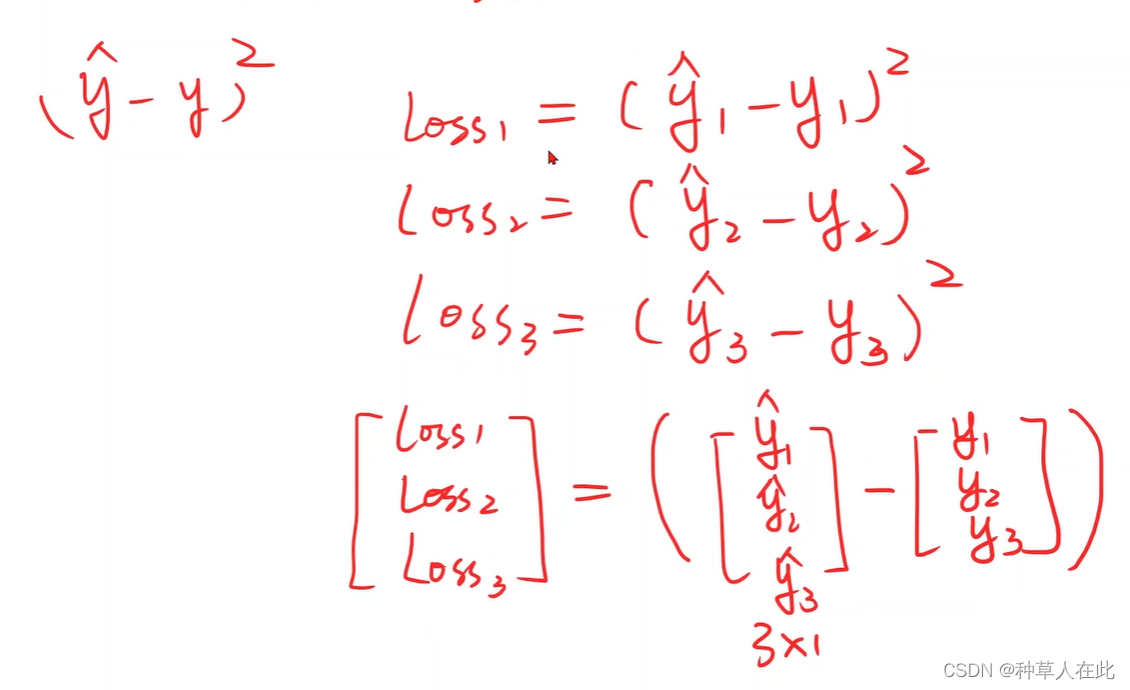
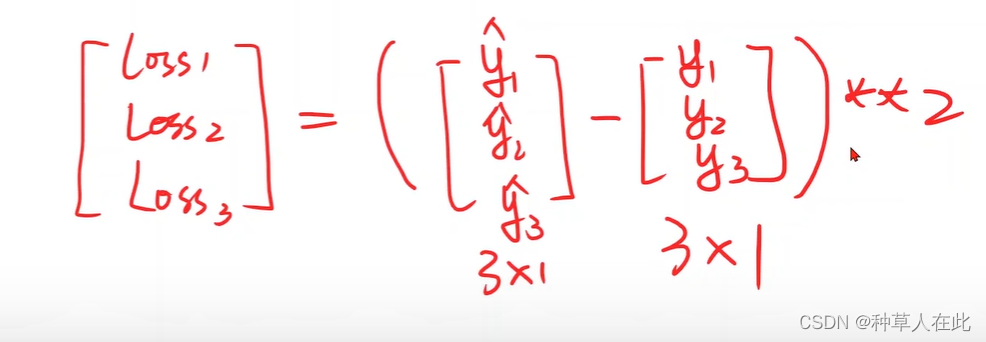
第二步定义模型
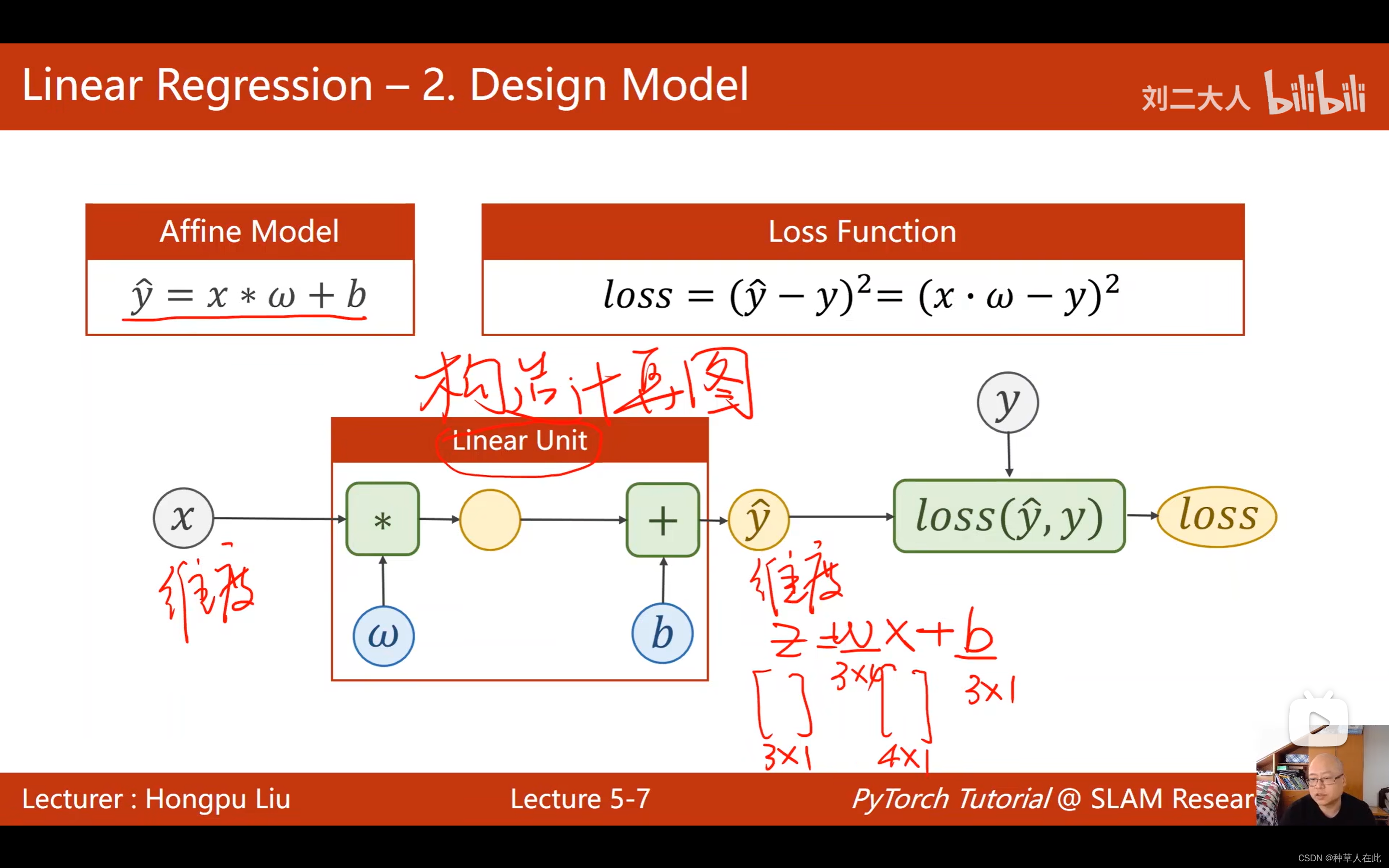
彷射模型实际上就是pytorch中的线性单元,一个线性单元就是w*x+b,需要确定权重形状【维度】是什么?偏置形状是什么?想知道w的大小,就要先知道x和y_hat的维度,然后将y_hat扔到loss函数中计算,最后得到loss。
换句
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









