









pandas数据处理
1、删除重复元素
合并只处理列不处理行
重复元素只检测行,不检测列
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每一个元素对应一行,如果该行不是第一次出现,则元素为True

df
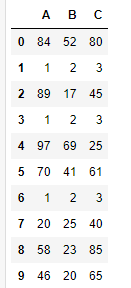
duplicated()函数的参数:
subset=None, keep=‘first’
subset 指定列标签列表,列表内的标签是用于检测重复数据的字段
keep有两个参数一个是first 另一个是last
first 除第一个找到相同元素并显示为True
last除第最后一个找到相同元素并显示为True
作用:找相同元素
df.duplicated(keep='first')

可以使用drop_duplicates()函数删除重复的行
drop_duplicates()函数参数:
subset=None, keep=‘first’, inplace=False
subset:指定列去重

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









