




 本文针对一个拥有五百万条记录且未进行分区的数据库表,介绍了一种通过优化索引和调整查询条件来提高SQL查询效率的方法。文章首先展示了如何查看表的所有索引,接着通过分析SQL执行计划来优化查询。
本文针对一个拥有五百万条记录且未进行分区的数据库表,介绍了一种通过优化索引和调整查询条件来提高SQL查询效率的方法。文章首先展示了如何查看表的所有索引,接着通过分析SQL执行计划来优化查询。
背景: 项目有个表 数据 目前大概就 五百多万。但是还是在不停的新增,没有分区,没有分库分表
解决方案: 同事们,马不停蹄的加索引 ,出现如下
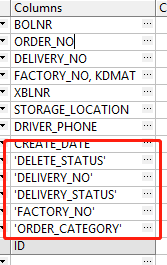
我同事问我,怎么有个条件加了索引,永远不走索引呢, 被我一眼识破,如上图,这可是 生产环境哦。 各位老哥们还是要细心点啊。。。
干货:
查询慢, 先不要慌
先看看 当前表的 索引有哪些
-- 查询表所有的索引
select t.*, i.index_type
from user_ind_columns t, user_indexes i
where t.index_name = i.index_name
and t.table_name = i.table_name
and t.table_name = '表名'
然后可以使用客户端 ,比如plsql ,打开执行计划
执行结果就可以看到如下

分析sql,适当的增加或者过滤筛选条件。达到最终目的。


















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











