






 本文详细介绍了BatchNormalization和LayerNormalization在处理特征图层时的计算区域和步骤,并对比了两者的优缺点。BatchNormalization在每个通道进行归一化,适合CNN,但对小批量数据和RNN不理想;LayerNormalization则在一个样本的全层进行计算,适用于RNN,但不适用于CNN。两种方法在神经网络中各有适用场景。
本文详细介绍了BatchNormalization和LayerNormalization在处理特征图层时的计算区域和步骤,并对比了两者的优缺点。BatchNormalization在每个通道进行归一化,适合CNN,但对小批量数据和RNN不理想;LayerNormalization则在一个样本的全层进行计算,适用于RNN,但不适用于CNN。两种方法在神经网络中各有适用场景。
BatchNormalization LayerNormalization
BatchNormalization
特征图层的处理区域
在 [Batch, Channel, Height, Width] 的特征图层中,Batch Normalization 顾名思义,就是在Batch中进行 Normalization 计算,其实就是在每个通道进行一次计算,即计算范围是 [Batch, 1, Height, Width],计算次数是 Channel。
计算步骤
- 在 [Batch, 1, Height, Width] 内计算均值
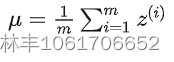
假定有输入 Z(i),上面公式就是计算均值,不多解释。 - 在 [Batch, 1, Height, Width] 内计算方差
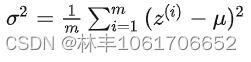
获取均值后,计算方差,就是上面的公式。 - 在每个 Channel 分别进行归一化
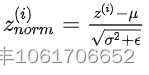
进行归一化,将原来的数据分布转换成正态分布(均值为0,方差为1),下面的e的作用是为了防止方差为0时的报错,可取一个很小的数,如1e-6。 - 缩放平移
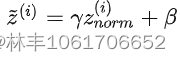
这是有两个需要训练的参数,缩放比例γ和偏置β,他们的作用是为了防止数据分布线性化。
缘由:
比如,当激活函数是 sigmoid 函数时,若数据分布总是均值为0,方差为1,那么 sigmoid 激活后的值只能在0.5周围的一个很小的区间,然而这个区间是接近线性的。而我们使用函数通常是为了得到一个更大方差的值,使得输出更有区分度,所以我们需要输入的方差更大一些,才能更多地利用到函数的非线性区域。所以我们使用 缩放比例γ 和 偏置β 来调整。
LayerNormalization
特征图层的处理区域
在 [Batch, Channel, Height, Width] 的特征图层中,Layer Normalization 顾名思义就是在一个Layer中进行计算,可以理解是一个样本中进行Normalization,即计算范围是 [1, Channel, Height, Width],计算次数是 Batch。
计算过程
与Batch Normalization的过程一样,只不过是在每个 [1, Channel, Height, Width] 进行 Batch 次计算。
两者区别
BN的优点:1.可以解决“Internal Covariate Shift”2.解决梯度消失的问题(针对sigmoid),加快收敛速度。
BN的缺点:1.batch size小的时候估算的统计值是不合理的 2.不适用于RNN,因为RNN的输入是动态,长度不一致,导致计算的估值不合理。比如针对三个文本,前两个文本有3个单词组成,最后一个文本有5个单词组成,这时针对4~5这两个单词(特征),只能以最后一个文本作为样本来计算统计量。
LN的优点:1.不依赖于batch size。2.适用于RNN;
LN的缺点:1.不适用于CNN。2.针对具有多个连续特征的数据,进行特征之间的缩放,可能会导致量纲差异消失。
个人学习用,侵删,欢迎讨论,如有不对的地方,请各位大佬改正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









