







 本文介绍了一种使用MapReduce实现倒排索引的方法,详细解析了如何通过Mapper读取文件并插入地址,利用Combiner进行初步处理,以及Reducer完成最终的数据整合。文章深入探讨了Mapper端的五个关键阶段,包括Combiner的作用和实现,以及Mapper、Combiner和Reducer的具体代码示例。
本文介绍了一种使用MapReduce实现倒排索引的方法,详细解析了如何通过Mapper读取文件并插入地址,利用Combiner进行初步处理,以及Reducer完成最终的数据整合。文章深入探讨了Mapper端的五个关键阶段,包括Combiner的作用和实现,以及Mapper、Combiner和Reducer的具体代码示例。
输入文件
| serch1.txt | serch2.txt | serch3.txt |
|---|---|---|
| MapReduce is simple | MapReduce is powerful is siimple | Hello MapReduce bye MapReduce |
输出文件
Hello serch3.txt:1
MapReduce serch3.txt:2 serch1.txt:1 serch2.txt:1
bye serch3.txt:1
is serch1.txt:1 serch2.txt:2
powerful serch2.txt:1
simple serch2.txt:1 serch1.txt:1
| Hello | MapReduce | bye | is | powerful | simpe |
|---|---|---|---|---|---|
| serch3.txt:1 | serch3.txt:2 serch1.txt:1 serch2.txt:1 | serch3.txt:1 | serch1.txt:1 serch2.txt:2 | serch2.txt:1 | serch2.txt:1 serch1.txt:1 |
从表中我们可以清楚的看出,每个单词在各个文件出现的频数,这就是倒排索引。
根据属性的值来查找记录及其位置。
设计思路
1:输入文件中并没有地址的输入,那么我们需要在mapper端读取数据的时候,插入其地址。按“ ”空格分割字符串,mapper的输出 <key,value>=<值 地址,1>或者<值 地址,(1,1)>
2:利用mapper和reducer之间一个极其重要的组件combiner进行首次的处理,并且分离key中的值与地址,此时的输出结果<key,value>=<值 ,地址 1>或者<值,地址 2>
注意:此组件是属于mapper端阶段的。
3:reducer开始进行最后的处理。
mapper端的五大阶段:
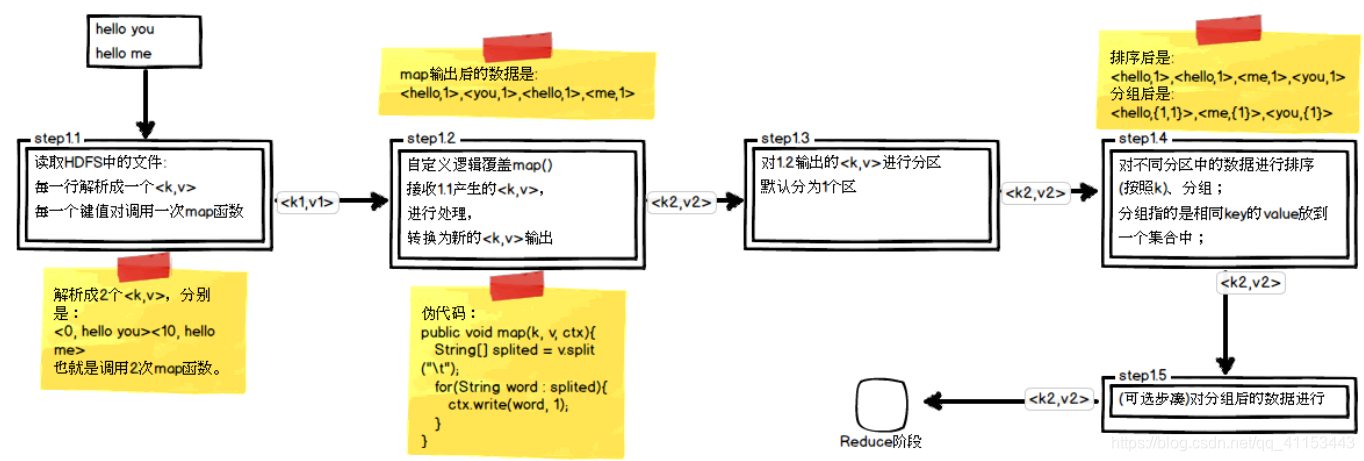
其中step1.5便是combiner,即为思路中的第二步。
代码
mapper:package LastSearch;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class LastSearchMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String words[] = line.split(" ");
InputSplit input = context.getInputSplit();
String pathname = ((FileSplit)input).getPath().getName();//得到此时数据的地址
for(String word:words)
{
String word1 = word+" "+pathname;
context.write(new Text(word1), new Text("1"));
}
}
}combiner:
package LastSearch;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class LastSearchComb extends
Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text arg0, Iterable<Text> arg1,Context arg2)
throws IOException, InterruptedException {
int sum = 0;
for(Text arg:arg1)
{
String word = arg.toString();
int wordINT = Integer.parseInt(word);
sum = wordINT+sum;
}
String line = arg0.toString();
String word[] = line.split(" ");
arg2.write(new Text(word[0]), new Text(word[1]+":"+sum));
}
}
reducer:
package LastSearch;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class LastSearchReducer extends
Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text arg0, Iterable<Text> arg1,Context arg2) throws IOException,
InterruptedException {
String newword = new String();
for(Text word:arg1)
{
String wordString = word.toString();
newword = newword+wordString+" ";
}
arg2.write(arg0, new Text(newword));
}
}main:
package LastSearch;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LastSearchMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LastSearchMain.class);
job.setMapperClass(LastSearchMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setCombinerClass(LastSearchComb.class);
job.setReducerClass(LastSearchReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean x = job.waitForCompletion(true);
System.out.println(x);
}
}

















 8723
8723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









