






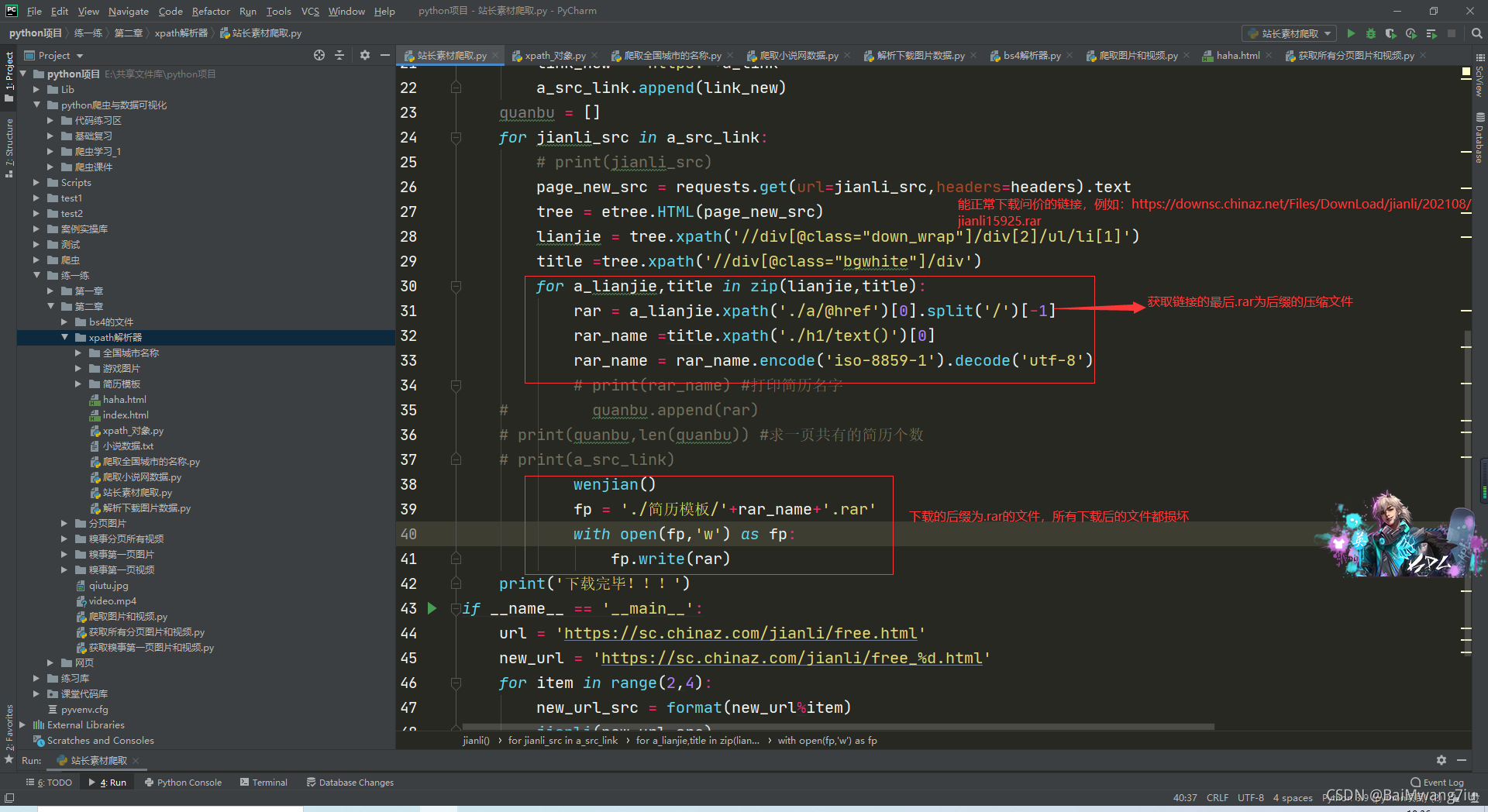
红色标注的地方是问题的描述。是从文件链接里下载后缀为(.rar)的压缩文件,我是从链接里取最后的(.rar)字符集,然后写到保存的文件夹里,下载完了以后所有文件都是损坏的。
import requests from lxml import etree import os.path def wenjian(): if not os.path.exists('./简历模板'): os.mkdir('./简历模板') def jianli(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36' } page_text = requests.get(url=url,headers=headers).text tree = etree.HTML(page_text) a_src_link = [] jianli_src = tree.xpath('//div[@id="main"]/div/div') # print(jianli_src) for a in jianli_src: a_link = a.xpath('./a/@href')[0] link_new = 'https:'+a_link a_src_link.append(link_new) quanbu = [] for jianli_src in a_src_link: # print(jianli_src) page_new_src = requests.get(url=jianli_src,headers=headers).text tree = etree.HTML(page_new_src) lianjie = tree.xpath('//div[@class="down_wrap"]/div[2]/ul/li[1]') title =tree.xpath('//div[@class="bgwhite"]/div') for a_lianjie,title in zip(lianjie,title): rar = a_lianjie.xpath('./a/@href')[0].split('/')[-1] rar_name =title.xpath('./h1/text()')[0] rar_name = rar_name.encode('iso-8859-1').decode('utf-8') # print(rar_name) #打印简历名字 # quanbu.append(rar) # print(quanbu,len(quanbu)) #求一页共有的简历个数 # print(a_src_link) wenjian() fp = './简历模板/'+rar_name+'.rar' with open(fp,'w') as fp: fp.write(rar) print('下载完毕!!!') if __name__ == '__main__': url = 'https://sc.chinaz.com/jianli/free.html' new_url = 'https://sc.chinaz.com/jianli/free_%d.html' for item in range(2,4): new_url_src = format(new_url%item) jianli(new_url_src)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











