







 本文介绍了使用KNN算法进行机器学习的实践,以鸢尾花数据集为例,详细阐述了算法设计、源代码实现以及测试用例的设计。通过计算鸢尾花花瓣长度和宽度,运用KNN算法预测新花的品种,成功预测的概率较高。总结中提到,KNN算法简单易懂,但对数据分布和样本量有一定要求,同时分享了在Python编程过程中遇到的挑战和未来优化的方向。
本文介绍了使用KNN算法进行机器学习的实践,以鸢尾花数据集为例,详细阐述了算法设计、源代码实现以及测试用例的设计。通过计算鸢尾花花瓣长度和宽度,运用KNN算法预测新花的品种,成功预测的概率较高。总结中提到,KNN算法简单易懂,但对数据分布和样本量有一定要求,同时分享了在Python编程过程中遇到的挑战和未来优化的方向。
一. 作业题目
收集一些鸢尾花的数据,包括花瓣的长度和宽度(单位cm)。这些花被鉴定为属于setosa,versicolor,virgincia三个品种之一。构造一个机器模型,使用knn算法,从这些已知品种的鸢尾花数据中进行学习,预测新鸢尾花的品种,并计算出成功预测的概率。
二. 算法设计
KNN介绍:K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。KNN是通过测量不同特征值之间的距离进行分类。
思路:如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
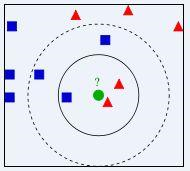
图一是KNN最常见的图,比较容易理解。要确定绿点属于哪个颜色(红色或者蓝色),要做的就是选出距离目标点距离最近的k个点,看这k个点的大多数颜色是什么颜色。当k取3的时候,我们可以看出距离最近的三个,分别是红色、红色、蓝色,因此得到目标点为红色。
设计:
- 导入pandas模块,读取存放了大量鸢尾花数据的csv文件,读取到的将是一个矩阵
- 将数据划分为训练集和测试集。利用随机数选出15个测试集,剩下的作为是数据集
- 使用KNN算法:
(1) 计算测试数据与训练数据各个点的距离,一般使用到欧几里得公式
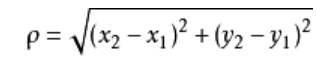
而当点有多个维度时,距离为:
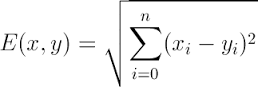
(2) 将距离按从小到大排序
(3) 选取距离最小的K个点;
(4) 确定前K个点所在类别的出现频率;
(5) 返回前K个点中出现频率最高的类别作为测试数据的预测分类
4.将真实值与预测结果做对比,得出成功预测的概率
三. 源代码
import numpy as np
import pandas as pd
import operator
#得到鸢尾花的数据
def getData():
#读取自定义的文件,从中获得鸢尾花数据
f = open('iris.csv')
iris=pd.read_csv(f)
return 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









