







 本文详细介绍了Spark的三种部署方式:单机模式、Spark-Mesos和Spark-YARN,并重点讲解了如何在Hadoop集群上搭建Spark 1.3.3完全分布式环境。包括安装前的软件需求、环境变量配置、关键配置文件修改及集群启动过程。
本文详细介绍了Spark的三种部署方式:单机模式、Spark-Mesos和Spark-YARN,并重点讲解了如何在Hadoop集群上搭建Spark 1.3.3完全分布式环境。包括安装前的软件需求、环境变量配置、关键配置文件修改及集群启动过程。
总目录:https://blog.youkuaiyun.com/qq_41106844/article/details/105553392
Hadoop - 子目录:https://blog.youkuaiyun.com/qq_41106844/article/details/105553369
Spark的部署方式
单机Spark
一般用于测试。
Spark-Mesos
与Spark有血缘关系,性能匹配最好。
Spark-Yarn
基于Hadoop集群,这种实用性最广。
安装Spark
安装前准备:jdk8,hadoop2.7集群,scala2.10以上的软件包,spark2.X软件包。
本次安装基于1.3.3完全分布式搭建。
虽然spark是scala语言编写的,但是因为scala和java的混编特性,只要有java环境就可以安装spark了。
scala软件包解压和spark解压路径一致即可。
首先解压spark软件包:

解压
配置环境变量:
/etc/profile

环境变量
修改配置文件:
之后来到spark目录中的conf目录,这个目录里面放的就是spark所有的配置项。
这个目录中的文件都是以template结尾的模板文件,将slaves和spark-env.sh拷贝出来。
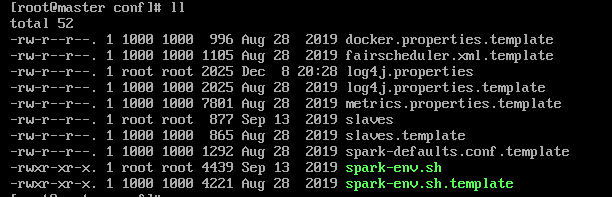
配置项
然后在slaves中添加所有节点。
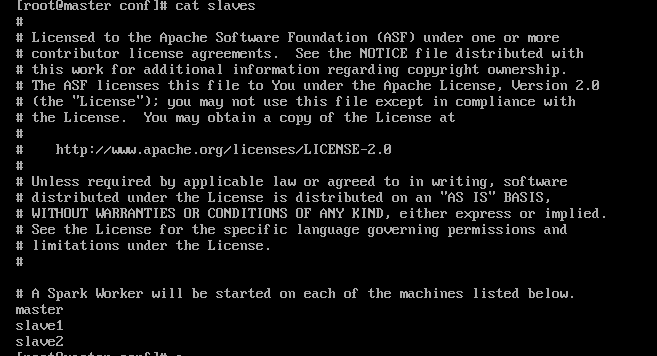
slaves
然后配置我们的spark-env.sh:
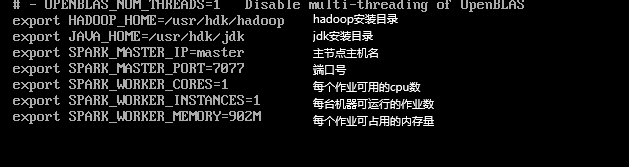
配置
同时修改一下启动关闭项的名称,防止和hadoop的冲突。
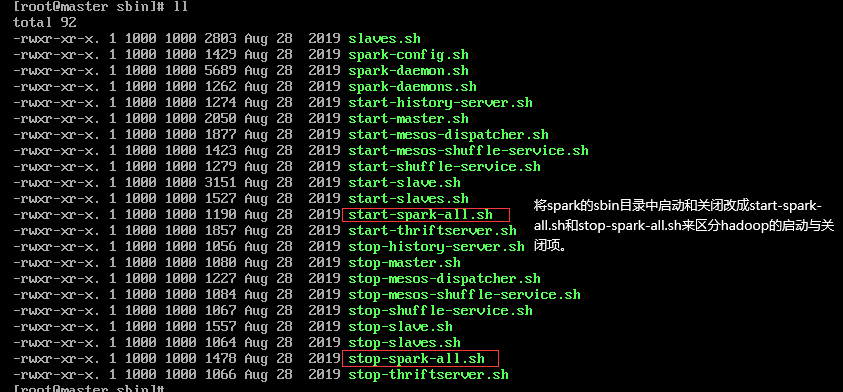
修改启动项
传输到其他节点:

传输到slave1
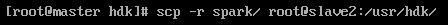
传输到slave2
启动集群:

启动hadoop
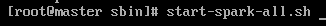
启动spark
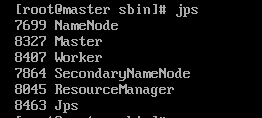
主节点jps
master是spark主节点标识,worker是任务容器。
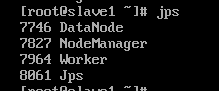
从节点jps
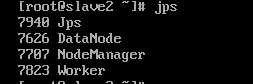
从节点jps



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











