









前序
我们上节课用新的方法展现了数据流分析的方法。
那么对于我们的迭代算法,是否可以利用这种类似图分析的手段进行解答?
所以我们可以把不动点的方法关联到算法上,这样我们就可以用不动点定理去解决迭代的问题。
迭代算法-不动点定理
回忆一下全格上的不动点

这个f: L->L我们可以作为迭代中的F

只要我们证明F是单调的就可以将两部分联系在一起。
单调性证明
转换函数:
易得,因为Gen/Kill函数就是单调的,在之前的算法中如果00000某个字符变为1就不会变回0,所以这个过程一定是单调的。
join/meet函数:
以join为例子,

需要证明在满足偏序关系的两个元素对另外一个元素join之后还是满足偏序关系

根据定义,y和y ⊔ z是满足偏序关系的,而根据偏序的传递性,x和y ⊔ z是满足偏序关系的,同时y ⊔ z也是z的上界,对x和z来说,他们的最小上界x ⊔ z一定和y ⊔ z满足偏序关系,最小上界⊑上界,x ⊔ z ⊑ y ⊔ z
回到问题:
- 一定能达到不动点
- 一定是最大或者最小不动点
- (复杂度问题,下面解决)
何时达到不动点
格的高度h是从top到bottom的最长路径长度
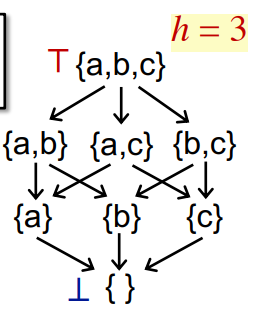
问题3被转化为最大迭代次数i会达到多少
我们假设一次迭代中,只有一个node变化,只移动一步
最坏情况下i=h*k
第三个问题的答案就是这个
may和must分析,格视角
两者都是从不安全的移动到安全的一点。
must analysis是用的语句优化为例,从不安全的“所有语句都可以优化”到最安全但没有用的“没有语句可以被优化”,在中间取到最大不动点,最接近truth
may analysis是用的可达性分析为例,从不安全的“没有变量可以reach”到最安全但没有用的“所有变量都有可能reach”,在中间取到最小不动点,最接近truth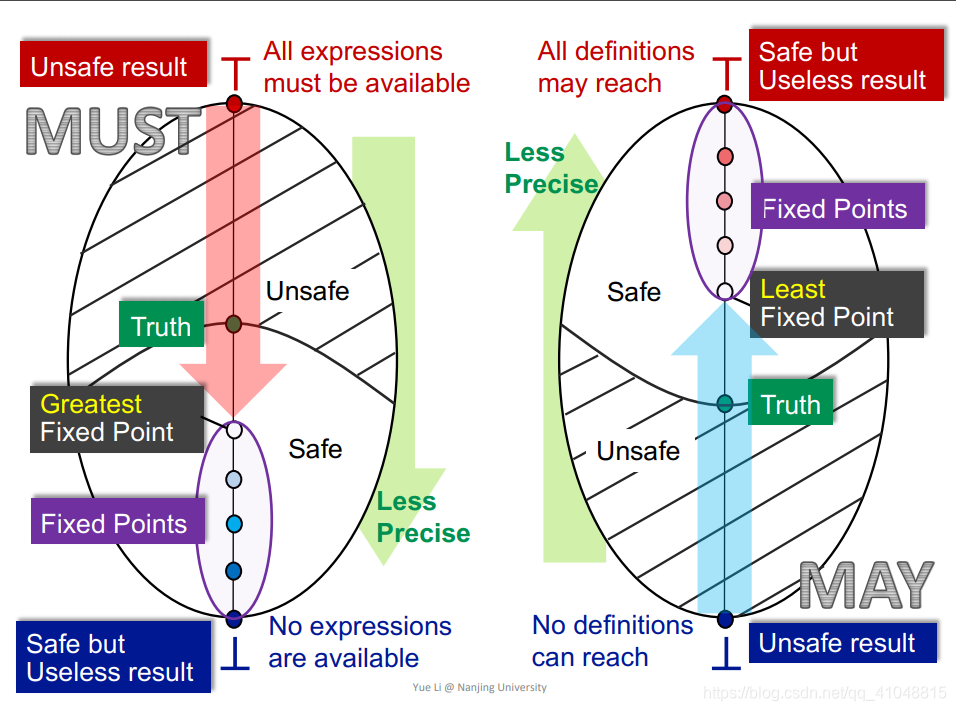
product lattice被表示成了椭圆区域是为什么?还需要回定义看看。
解决的精度有多高?
Meet-Over-All-Paths Solution(MOP)
相比迭代算法,MOP需要找出所有的路径,然后通过转换函数进行计算,然后进行上下界求算。
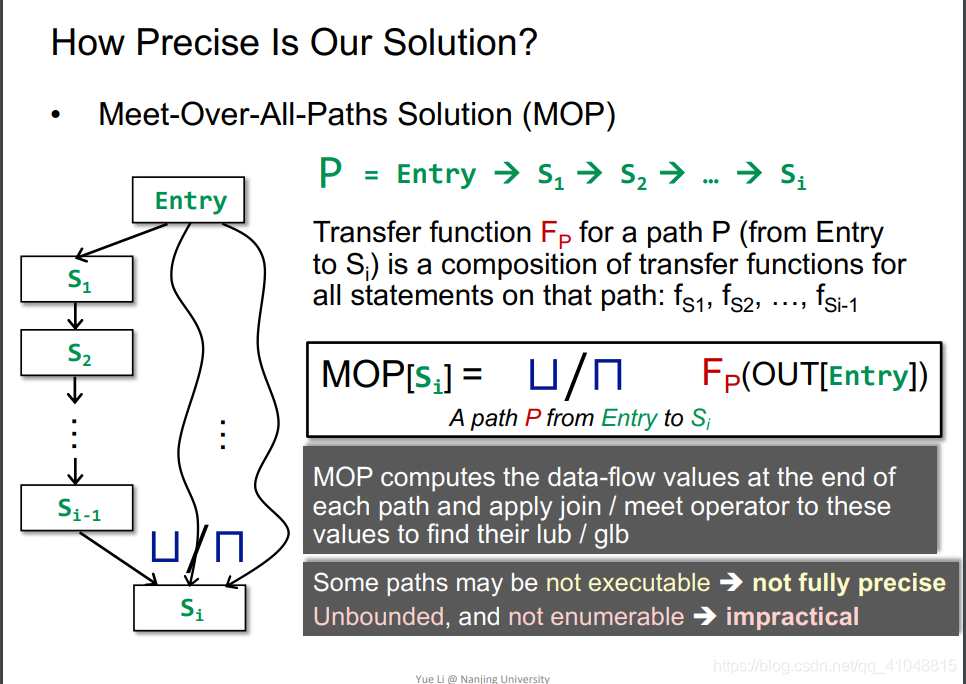
问题:
一些路径不可执行,不够精准
没有边界,不可枚举,使得不够可行
迭代和MOP对比
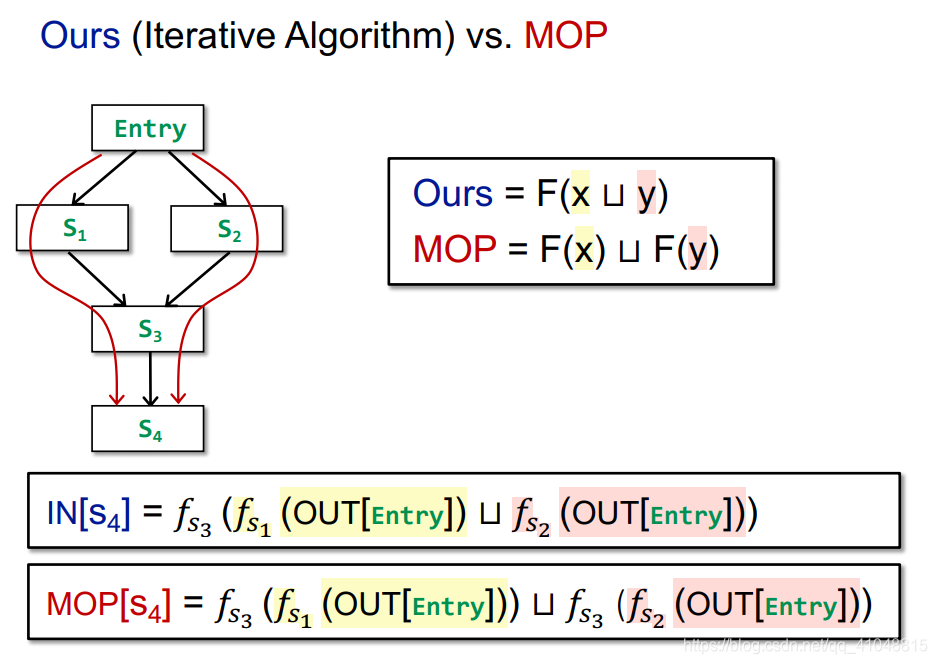
迭代是在每个地方都做join,MOP是在最后做join
他们两个有什么关系?

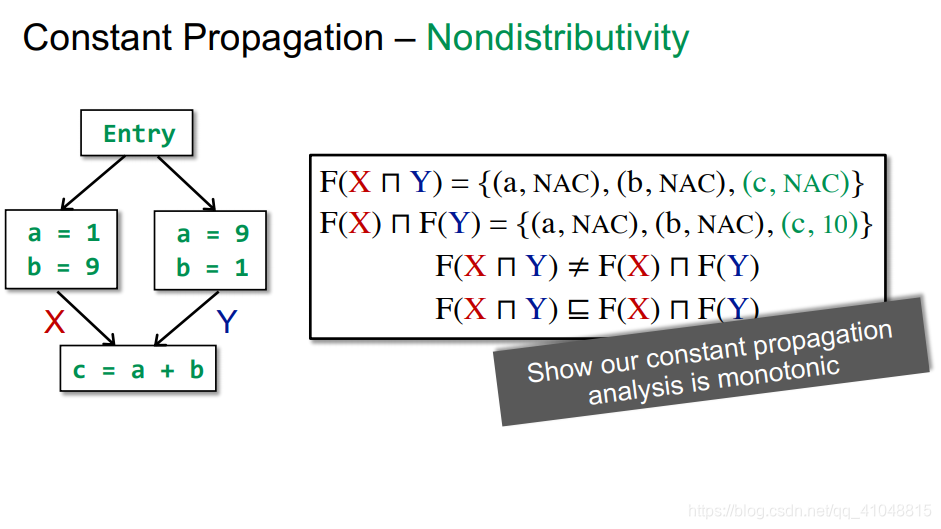
我们用证明计算一下,迭代相比MOP精准度更低
如果F具有可分配性,分配律,两者精准度就是一样的
在之前的所有分析,位分析,Gen/Kill问题都是distributive的
那么有没有不是distributive的呢?
常量传播
在程序点P假设存在一个变量x,判断x是否保证在p点指向一个常量值。
这个算法是一个正向的数据流,那么他的格和转换函数是怎么样的呢?
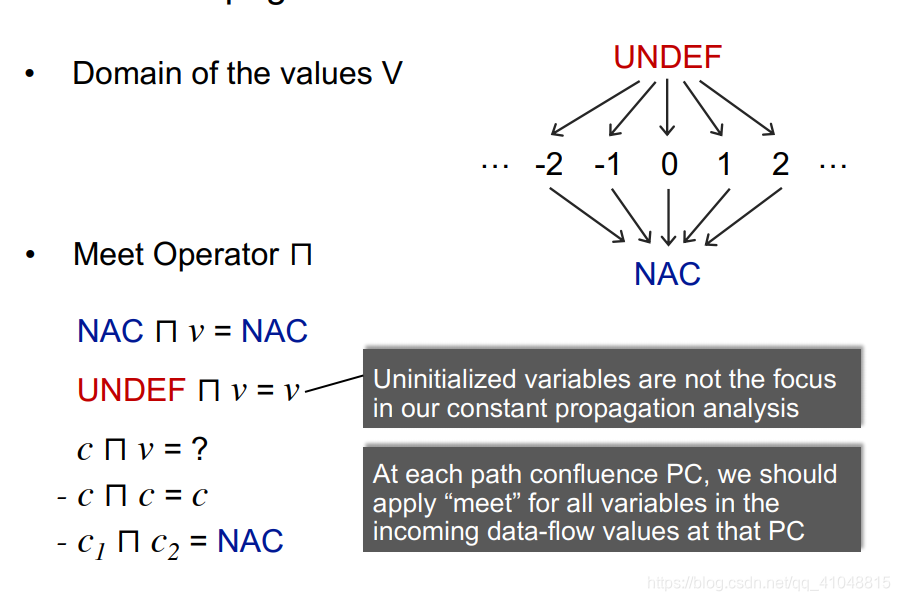

等试验出来一起研究重写一下,格这块还是没弄明白,没有抽象,停留在具体的简单格上。
Worklist算法
一个迭代算法的优化

只遍历计算变化的BB,OUT不变化的不遍历,因为IN不变OUT就不会变
需要掌握的
理解迭代算法的算法视角
格和完全格的定义
理解不动点定理
如何总结格中的may和must分析
MOOP和迭代生成的结果的关系
常量传播分析
worklist算法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









