









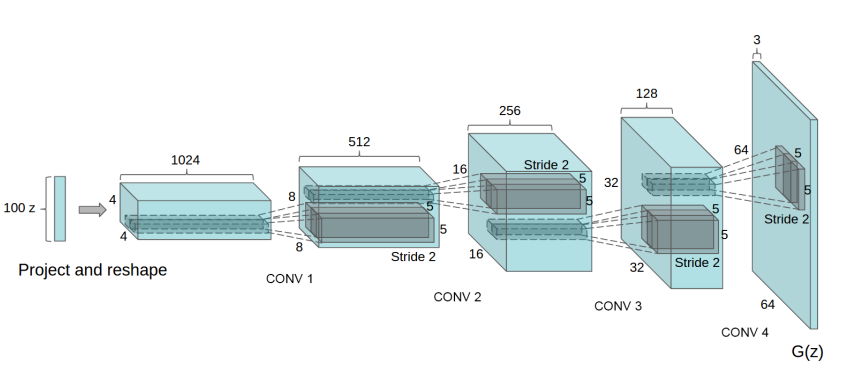
先看一下DCGAN的G模型:
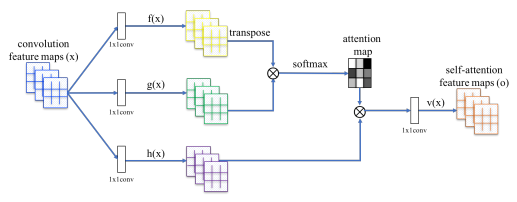
再看一下Self Attention的网络结构:
话不多说,上代码:
G、D的model文件如下:
import torch
import torch.nn as nn
from torch.nn import Parameter
def l2normalize(v, eps=1e-12):
return v / (v.norm() + eps)
# 谱范数归一化
class SpectralNorm(nn.Module):
def __init__(self, module, name='weight', power_iterations=1):
super(SpectralNorm, self).__init__()
self.module = module
self.name = name
self.power_iterations = power_iterations
if not self._made_params():
self._make_params()
def _update_u_v(self):
u = getattr(self.module, self.name + "_u")
v = getattr(self.module, self.name + "_v")
w = getattr(self.module, self.name + "_bar")
height = w.data.shape[0]
for _ in range(self.power_iterations):
v.data = l2normalize(torch.mv(torch.t(w.view(height,-1).data), u.data))
u.data = l2normalize(torch.mv(w.view(height,-1).data, v.data))
# sigma = torch.dot(u.data, torch.mv(w.view(height,-1).data, v.data))
sigma = u.dot(w.view(height, -1).mv(v))
setattr(self.module, self.name, w / sigma.expand_as(w))
def _made_params(self):
try:
u = getattr(self.module, self.name + "_u")
v = getattr(self.module, self.name + "_v")
w = getattr(self.module, self.name + "_bar")
return True
except AttributeError:
return False
def _make_params(self):
w = getattr(self.module, self.name)
height = w.data.shape[0]
width = w.view(height, -1).data.shape[1]
u = Parameter(w.data.new(height).normal_(0, 1), requires_grad=False)
v = Parameter(w.data.new(width).normal_(0, 1), requires_grad=False)
u.data = l2normalize(u.data)
v.data = l2normalize(v.data)
w_bar = Parameter(w.data)
del self.module._parameters[self.name]
self.module.register_parameter(self.name + "_u", u)
self.module.register_parameter(self.name + "_v", v)
self.module.register_parameter(self.name + "_bar", w_bar)
def forward(self, *args):
self._update_u_v()
return self.module.forward(*args)
# 注意力层
class Self_Attn(nn.Module):
def __init__(self, channels: int):
super().__init__()
self.channels = channels
# 构造模块: 查询、键、值
# self.theta = nn.utils.spectral_norm(nn.Conv2d(channels, channels // 8, kernel_size=1, padding=0, bias=False))
# self.phi = nn.utils.spectral_norm(nn.Conv2d(channels, channels // 8, kernel_size=1, padding=0, bias=False))
# self.g = nn.utils.spectral_norm(nn.Conv2d(channels, channels // 2, kernel_size=1, padding=0, bias=False))
# self.o = nn.utils.spectral_norm(nn.Conv2d(channels // 2, channels, kernel_size=1, padding=0, bias=False))
self.theta = SpectralNorm(nn.Conv2d(channels, channels // 8, kernel_size=1, padding=0, bias=False))
self.phi = SpectralNorm(nn.Conv2d(channels, channels // 8, kernel_size=1, padding=0, bias=False))
self.g = SpectralNorm(nn.Conv2d(channels, channels // 2, kernel_size=1, padding=0, bias=False))
self.o = SpectralNorm(nn.Conv2d(channels // 2, channels, kernel_size=1, padding=0, bias=False))
self.gamma = nn.Parameter(torch.tensor(0.), requires_grad=True)
def forward(self, x):
spatial_size = x.shape[2] * x.shape[3]
# apply convolutions to get query (theta), key (phi), and value (g) transforms
theta = self.theta(x)# x经过1*1的卷积层得到查询特征向量f(x):B * N * C
phi = F.max_pool2d(self.phi(x), kernel_size=2)# x经过1*1的卷积层得到键特征向量g(x):B * C * N, 最大池化
g = F.max_pool2d(self.g(x), kernel_size=2)# x经过1*1的卷积层得到值特征向量h(x):B * C * N, 最大池化
# reshape spatial size for self-attention
theta = theta.view(-1, self.channels // 8, spatial_size)
phi = phi.view(-1, self.channels // 8, spatial_size // 4)
g = g.view(-1, self.channels // 2, spatial_size // 4)
# softmax( f(x)的转置矩阵 * g(x) ) == attention map
beta = F.softmax(torch.bmm(theta.transpose(1, 2), phi), dim=-1)
# 经过1*1的卷积层conv (值特征向量h(x) * attention map的转置矩阵) = self attention map
o = self.o(torch.bmm(g, beta.transpose(1, 2)).view(-1, self.channels // 2, x.shape[2], x.shape[3]))
# apply gain and residual
return self.gamma * o + x
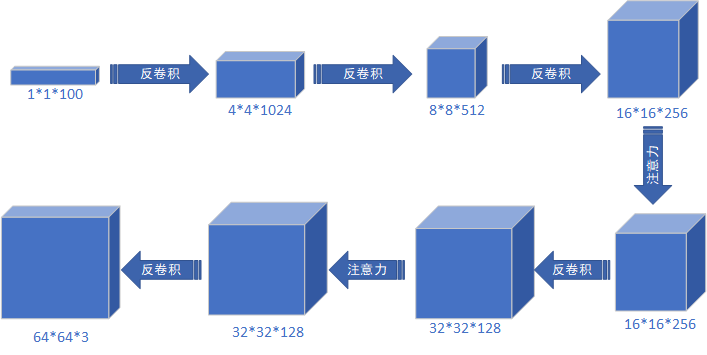
# DCGAN的生成器
class Generator(nn.Module):
def __init__(self, nz=100, ngf=128, nc=3):
super(Generator, self).__init__()
self.main = nn.Sequential(
# 输入torch.Size([64, 100, 1, 1]) --> torch.Size([64, 1024, 4, 4])
# 输入信号的通道数nz=100; 卷积产生的通道数ngf*8=128*8; 卷积核大小4*4; 卷积步长1; 输入的每条边补充0的层数0;是否添加偏置flase
SpectralNorm(nn.ConvTranspose2d(in_channels=nz, out_channels=ngf * 8, kernel_size=4, stride=1, padding=0, bias=False)),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# torch.Size([64, 1024, 4, 4]) --> torch.Size([64, 512, 8, 8])
SpectralNorm(nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False)),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# torch.Size([64, 512, 8, 8]) --> torch.Size([64, 256, 16, 16])
SpectralNorm(nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False)),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
Self_Attn(ngf*2),
# torch.Size([64, 256, 16, 16]) --> torch.Size([64, 128, 32, 32])
SpectralNorm(nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False)),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
Self_Attn(ngf),
# torch.Size([64, 128, 32, 32]) --> torch.Size([64, 3, 64, 64])
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
)
def forward(self, input):
return self.main(input)# torch.Size([64, 100, 1, 1]) return torch.Size([64, 3, 64, 64])
# 模型权重应当从均值为0,标准差为0.02的正态分布中随机初始化。
def initialize_weights(self, w_mean=0., w_std=0.02, b_mean=1, b_std=0.02):
for m in self.modules():
classname = m.__class__.__name__
if classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, b_mean, b_std)
nn.init.constant_(m.bias.data, 0)
# DCGAN的判别器
class Discriminator(nn.Module):
def __init__(self, nc=3, ndf=128):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# input is (nc) x 64 x 64
SpectralNorm(nn.Conv2d(nc, ndf, 4, 2, 1, bias=False)),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
SpectralNorm(nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False)),
#nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
SpectralNorm(nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False)),
#nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
Self_Attn(ndf * 4),
# state size. (ndf*4) x 8 x 8
SpectralNorm(nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False)),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
Self_Attn(ndf * 8),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
# 模型权重应当从均值为0,标准差为0.02的正态分布中随机初始化。
def initialize_weights(self, w_mean=0., w_std=0.02, b_mean=1, b_std=0.02):
for m in self.modules():
classname = m.__class__.__name__
if classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, b_mean, b_std)
nn.init.constant_(m.bias.data, 0)train文件如下(先准备好数据集:裁减好的CelebA数据集):
import os
import torch.nn as nn
import torch.optim as optim
import torch.utils.data
import imageio
from torch.nn import Parameter
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
from CelebADataset import CelebADataset
from SAGAN_DCGAN_models import Discriminator, Generator
import argparse
device = torch.device("cuda" if torch.cuda.is_available() else "cpu",0)
def set_seed(seed):
torch.manual_seed(seed) # cpu 为CPU设置种子用于生成随机数,以使得结果是确定的
torch.cuda.manual_seed(seed) # gpu 为当前GPU设置随机种子
torch.backends.cudnn.deterministic = True # cudnn
np.random.seed(seed) # numpy
np.random.seed(seed) # random and transforms
# confg
parser = argparse.ArgumentParser()
parser.add_argument('--ngpu', type=int, default=1, help='Number of GPUs available. Use 0 for CPU mode.')
parser.add_argument('--data_dir', type=str, default='./Datasets/CelebA/img_celeba/img_celeba', help='the path of celebA')
parser.add_argument('--out_dir', type=str, default='SAGAN_DCGAN_output', help='整个训练过程中的输出:模型、图片')
parser.add_argument('--checkpoint_interval', type=int, default=10, help='采样间隔')
parser.add_argument('--image_size', type=int, default=64, help='图片大小')
parser.add_argument('--nc', type=int, default=3, help='channels')
parser.add_argument('--nz', type=int, default=100, help='变量的维度')
parser.add_argument('--ngf', type=int, default=128, help='G的特征数')
parser.add_argument('--ndf', type=int, default=128, help='D的特征数')
parser.add_argument('--num_epochs', type=int, default=100, help='训练批次')
parser.add_argument('--real_idx', type=int, default=0.9, help='正样本的标签')
parser.add_argument('--fake_idx', type=int, default=0.1, help='负样本的标签')
parser.add_argument('--lr', type=float, default=0.0002, help='学习率')
parser.add_argument('--batch_size', type=int, default=128, help='')
parser.add_argument('--beta1', type=float, default=0.5, help='优化器的参数')
opt = parser.parse_args()
# 加载数据集
d_transforms = transforms.Compose([transforms.Resize(opt.image_size),
transforms.CenterCrop(opt.image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # -1 ,1
])
train_set = CelebADataset(data_dir=opt.data_dir, transforms=d_transforms)
train_loader = DataLoader(train_set, batch_size=opt.batch_size, num_workers=2, shuffle=True)
# 实例化生成器并放入GPU中
net_g = Generator(nz=opt.nz, ngf=opt.ngf, nc=opt.nc)
net_d = Discriminator(nc=opt.nc, ndf=opt.ndf)
net_g.initialize_weights()#初始化权重
net_d.initialize_weights()#初始化权重
net_g.to(device)
net_d.to(device)
# 设置损失函数
criterion = nn.BCELoss()
# 设置优化器
optimizerD = optim.Adam(net_d.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
optimizerG = optim.Adam(net_g.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
# 设置动态学习率 每循环step_size8次更新一次lr=lr*gamma
lr_scheduler_d = torch.optim.lr_scheduler.StepLR(optimizerD, step_size=8, gamma=0.1)
lr_scheduler_g = torch.optim.lr_scheduler.StepLR(optimizerG, step_size=8, gamma=0.1)
def train():
img_list = []
G_losses = []
D_losses = []
iters = 0
#best_G_loss = 100
for epoch in range(opt.num_epochs):
for i, data in enumerate(train_loader):
############################
# 训练更新D
###########################
net_d.zero_grad() # 每个参数的梯度值设为0,即上一次的梯度记录被清空
# 创建训练数据集
real_img = data.to(device)# data:torch.Size([64, 3, 64, 64])
b_size = real_img.size(0) # 64
real_label = torch.full((b_size,), opt.real_idx, device=device) #torch.Size([64])
# 随机噪音,用生成器生成图像
noise = torch.randn(b_size, opt.nz, 1, 1, device=device)# torch.Size([64, 100, 1, 1])
fake_img = net_g(noise)# torch.Size([64, 3, 64, 64])
fake_label = torch.full((b_size,), opt.fake_idx, device=device)# torch.Size([64])
# 用真实的数据训练D
out_d_real = net_d(real_img)# torch.Size([64, 1, 1, 1])
loss_d_real = criterion(out_d_real.view(-1), real_label)
#torch.nn.ReLU()(1.0 - d_out_real).mean()
# 用生成的数据训练D
out_d_fake = net_d(fake_img.detach())# torch.Size([64, 1, 1, 1])
loss_d_fake = criterion(out_d_fake.view(-1), fake_label)
# 反向传播计算其对应的梯度
# loss_d_real.backward()
# loss_d_fake.backward()
loss_d = loss_d_real + loss_d_fake
loss_d.backward()
# 执行一次优化步骤,通过梯度下降法来更新参数的值
optimizerD.step()
# 记录概率
d_x = out_d_real.mean().item() # D(x) 判别器对真实数据的判断概率
d_g_z1 = out_d_fake.mean().item() # D(G(z1)) 判别器对生成数据的判断概率
############################
# 训练更新G
###########################
net_g.zero_grad() # 每个参数的梯度值设为0,即上一次的梯度记录被清空
label_for_train_g = real_label # 真实数据的标签 torch.Size([64])
out_d_fake_2 = net_d(fake_img) # 对生成图像的判别概率 torch.Size([64, 1, 1, 1])
loss_g = criterion(out_d_fake_2.view(-1), label_for_train_g)# 用真实数据的的标签和判别器对生成数据的判断概率计算G的损失值
loss_g.backward()# 反向传播计算其对应的梯度
optimizerG.step() # 执行一次优化步骤,通过梯度下降法来更新参数的值
# 记录概率
d_g_z2 = out_d_fake_2.mean().item() # D(G(z2)) 对生成图像的判别概率
# 输出训练数据
if i % 100 == 0:
#if i == len(train_loader)-1 :
print('[{}/{}][{}/{}] Loss_D:{} Loss_G:{} D(x):{} D(G(z)):{}'.format(
epoch, opt.num_epochs, i, len(train_loader),loss_d.item(),loss_g.item(),d_x, d_g_z1/d_g_z2))
# 损失留给以后的绘图
G_losses.append(loss_g.item())
D_losses.append(loss_d.item())
lr_scheduler_d.step()# 更新学习率
lr_scheduler_g.step()
# 通过在fixed_noise上保存g的输出来检查生成器是如何工作的
with torch.no_grad():
fixed_noise = torch.randn(64, opt.nz, 1, 1, device=device)# opt.nz:变量维度100
fake = net_g(fixed_noise).detach().cpu()
img_grid = vutils.make_grid(fake, padding=2, normalize=True).numpy()
img_grid = np.transpose(img_grid, (1, 2, 0))
plt.imshow(img_grid)
plt.title("Epoch:{}".format(epoch))
plt.savefig(os.path.join(opt.out_dir, "{}_epoch.png".format(epoch)))
# 保存模型
if (epoch+1) % opt.checkpoint_interval == 0:
#if loss_g.item() < best_G_loss:
best_G_loss = loss_g.item()
checkpoint = {"best_g_model_state_dict": net_g.state_dict(),
"best_d_model_state_dict": net_d.state_dict(),
"epoch": epoch}
path_checkpoint = os.path.join(opt.out_dir, "G_D.pkl")
torch.save(checkpoint, path_checkpoint)
# 绘制损失值曲线图并保存
plt.figure(figsize=(10, 5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label="G")
plt.plot(D_losses, label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.savefig(os.path.join(opt.out_dir, "loss.png"))
# save gif
imgs_epoch = [int(name.split("_")[0]) for name in list(filter(lambda x: x.endswith("epoch.png"), os.listdir(opt.out_dir)))]
imgs_epoch = sorted(imgs_epoch)
imgs = list()
for i in range(len(imgs_epoch)):
img_name = os.path.join(opt.out_dir, "{}_epoch.png".format(imgs_epoch[i]))
imgs.append(imageio.imread(img_name))
imageio.mimsave(os.path.join(opt.out_dir, "generation_animation.gif"), imgs, fps=2)
print("done")
if __name__ == '__main__':
set_seed(1) # 设置随机种子
train()运行结果待续:


















 2073
2073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









