







 VGGnet是2014年由牛津大学和DeepMind开发的深度学习模型,它基于Alexnet并引入了多个小尺寸卷积层。文章详细介绍了VGGNet-16的网络结构,包括13个卷积层和3个全连接层,以及其在PyTorch中的实现,包括卷积、池化、ReLU激活和Dropout等操作。
VGGnet是2014年由牛津大学和DeepMind开发的深度学习模型,它基于Alexnet并引入了多个小尺寸卷积层。文章详细介绍了VGGNet-16的网络结构,包括13个卷积层和3个全连接层,以及其在PyTorch中的实现,包括卷积、池化、ReLU激活和Dropout等操作。
VGGnet论文地址[https://arxiv.org/pdf/1409.1556.pdf]。VGGnet是由牛津大学和DeepMind于2014年研发的深度学习网络。它是由Alexnet发展而来的,VGGNet-16的网络结构如图所示:
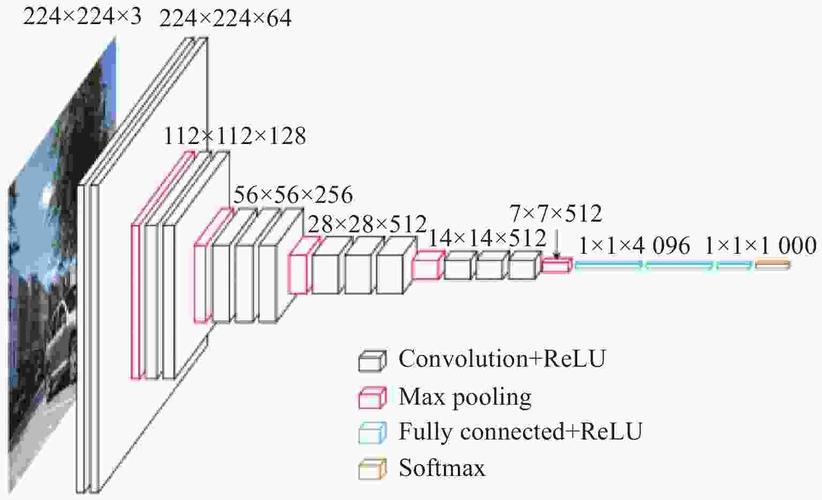
VGGNet-16有13个卷积层和3个全连接层。
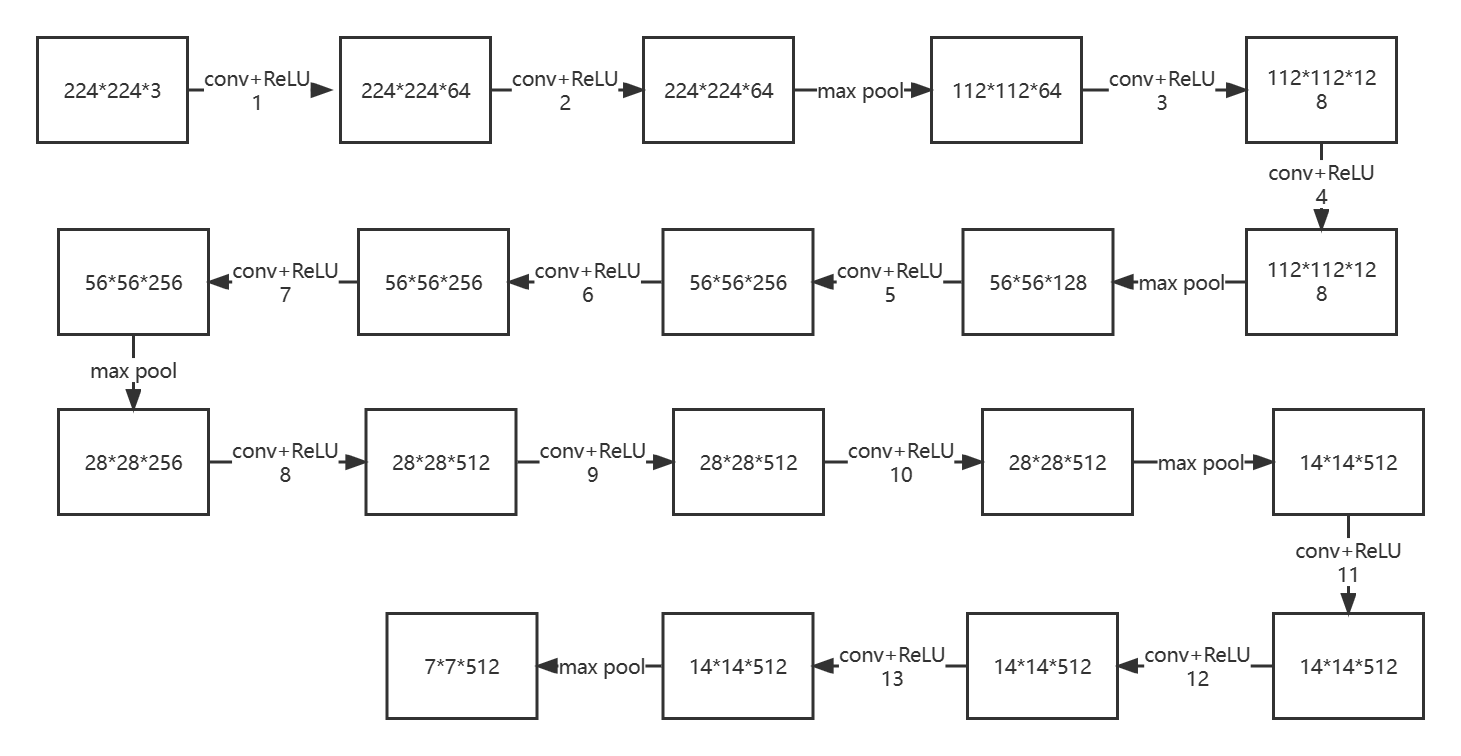
第一层卷积:输入图像的size是224*224*3,使用64个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是224*224*64。再使用ReLU激活函数。
第二层卷积+池化:输入图像的size是224*224*64,使用64个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是224*224*64。再使用ReLU激活函数。最后进行最大池化,使用size是2*2,stride步长为2,padding填充为0进行池化,输出是112*112*64。
第三层卷积:输入图像的size是112*112*64,使用128个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是112*112*128。再使用ReLU激活函数。
第四层卷积+池化:输入图像的size是112*112*128,使用128个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是112*112*128。再使用ReLU激活函数。最后进行最大池化,使用size是2*2,stride步长为2,padding填充为0进行池化,输出是56*56*128。
第五层卷积:输入图像的size是56*56*128,使用256个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是56*56*256。再使用ReLU激活函数。
第六层卷积:输入图像的size是56*56*256,使用256个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是56*56*256。再使用ReLU激活函数。
第七层卷积+池化:输入图像的size是56*56*256,使用256个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是56*56*256。再使用ReLU激活函数。最后进行最大池化,使用size是2*2,stride步长为2,padding填充为0进行池化,输出是28*28*256。
第八层卷积:输入图像的size是28*28*256,使用512个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是28*28*512。再使用ReLU激活函数。
第九层卷积:输入图像的size是28*28*512,使用512个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是28*28*512。再使用ReLU激活函数。
第十层卷积+池化:输入图像的size是28*28*512,使用512个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是28*28*512。再使用ReLU激活函数。最后进行最大池化,使用size是2*2,stride步长为2,padding填充为0进行池化,输出是14*14*512。
第十一层卷积:输入图像的size是14*14*512,使用512个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是14*14*512。再使用ReLU激活函数。
第十二层卷积:输入图像的size是14*14*512,使用512个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是14*14*512。再使用ReLU激活函数。
第十三层卷积+池化:输入图像的size是14*14*512,使用512个size是3*3,stride步长为1,padding填充为1的卷积核,卷积后的输出特征图size是14*14*512。再使用ReLU激活函数。最后进行最大池化,使用size是2*2,stride步长为2,padding填充为0进行池化,输出是7*7*512。
十三次卷积的卷积核都是一样的:size=3;stride=1;padding=1。
五次最大池化的核都是一样的:size=2,;stride=2;padding=0。
第一层全连接+ReLU+Dropout,有4096个结点;第二层全连接+ReLU+Dropout,有4096个结点;第三层圈里那句,有1000个结点。最后是输出层,输出网络识别结果。
下列是VGGNet的PyTorch实现:
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
#
#num_classes=1000需要分类的类别个数
#初始化函数__init__传进来features,也就是我们刚刚通过make_features(cfg: list)函数生成的提取特征网络结构
#init_weights=False是否对网络进行权重初始化
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
#生成分类网络结构
self.classifier = nn.Sequential(
#输入节点个数,是展平处理之后所得到的1维向量的元素个数512*7*7
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:#是否要对网络进行参数的初始化
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
# 图像经过提取特征网络结构之后,得到一个7*7*512的特征矩阵,如果...
# 要和全连接层进行全连接,要进行一个展平处理。展平之后,才能和全连接层进行全连接
x = torch.flatten(x, start_dim=1)#展平,从第一个维度展平
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():#遍历网络中的每一层
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)#初始化权重
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
#参数是配置变量,是list类型,传入对应配置的列表就可以了
#make_features(cfg: list)这个函数用来生成提取网络结构
def make_features(cfg: list):
layers = []#定义一个空列表,用来存放所创建的每一层结构
in_channels = 3#输入的图片是RGB彩色图片
for v in cfg:#通过一个for循环来遍历配置列表,能得到一个由卷积操作和池化操作组成的一个列表
if v == "M":#如果当前的配置元素是一个M字符,说明该层是最大池化层
# 创建一个最大池化下采样层,在VGG中,所有的最大池化下采样层的核大小都是2,stride都是2
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:#否则是卷积层
#in_channels表示输入的特征矩阵的深度,v是输出的特征矩阵的深度,也就是卷积核的个数
#在VGG中,所有的卷积层padding为1,stride为1
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)#创建一个卷积层
# 将卷积层和ReLU拼接好后,放到layers层中
layers += [conv2d, nn.ReLU(True)]
in_channels = v
#将列表通过非关键字参数的形式,传入进去。layers前面的*表示我们是通过非关键字参数传入进去的
return nn.Sequential(*layers)
#定义cfgs一个字典文件,每一个key代表一个模型的配置文件,比如vgg11代表A配置,也就是11层的一个网络
#数字比如64代表卷基层的卷积核的个数,'M'代表池化层的结构
#有了这个配置,如何生成提取特征网络结构呢?定义了一个函数make_features(cfg: list)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
#实例化给定的配置模型
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
#实例化VGG网络
#**kwargs表示可变长度的字典变量,是在调用VGG函数时传入的一个字典变量
#这个字典变量包含了分类的个数,以及是否初始化权重的布尔变量
model = VGG(make_features(cfg), **kwargs)
return model
#在nn.Sequential(*layers)设置一个断点,可以实例化一个类来看一下
#vgg_model=vgg(model_name='vgg13')

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









