






 本文详述如何在Linux环境下使用Java编写MapReduce程序,以WordCount为例,涵盖从导入Hadoop库、编写Java代码、导出JAR文件到Linux上执行Hadoop命令的过程,并解决执行过程中遇到的问题。
本文详述如何在Linux环境下使用Java编写MapReduce程序,以WordCount为例,涵盖从导入Hadoop库、编写Java代码、导出JAR文件到Linux上执行Hadoop命令的过程,并解决执行过程中遇到的问题。
一:导入Hadoop的jar包
右击包名——>Bulid Path——>Add external Archives
hadoop-2.6.5\share\hadoop\common 所有jar,
hadoop-2.6.5\share\hadoop\common\lib 所有jar,
hadoop-2.6.5\share\hadoop\hdfs 所有jar
hadoop-2.6.5\share\hadoop\mapreduce 所有jar
hadoop-2.6.5\share\hadoop\yarn 所有jar
二:java 的mapreduce文件
获取代码:https://pan.baidu.com/s/1k9X_pG25yLrnxNlORrVvNQ
提取码:rvjh
public class WordCount {
/**
* 两个抽象类:wordCountMap wordCountReduce
*
*
* Object:输入数据的具体内容 Text:每行的文本数据 Text:每个单词分解后统计结果 IntWritable;输出计算的map结果
*
* @author Administrator
*
*/
//第一个静态类 wordcountMap,该类继承Hadoop jar包的Mapper
private static class wordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
@Override
protected void map(
Object key,
Text value,
Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO 添加map处理逻辑代码
/**
* <I,1> <like,1>...
* 1、将每行数据转化为string
* 2、对每行数据按照空格拆分成string
* 3、生成<K,V>对,其中V固定值为1
*/
//1、获取每一行数据
String lineContent=value.toString();
//2、根据空格split拆分
String [] contentSplit=lineContent.split(" ");
for (int i=0;i<contentSplit.length;i++){
//3、写成<K,v>数据形式
context.write(new Text(contentSplit[i]), new IntWritable(1));
}
}
};
//第二个静态类 wordcountReducer,Text:map的文本内容,说白了就是map,key
private static class wordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(
Text key,
Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//1、对map<k,v>进行累加操作
int sum=0;
for(IntWritable value:values){
sum+=value.get();
}
context.write(key, new IntWritable(sum));
}
};
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
/**
* 每一次执行一个作业(job),初始化 HDFS参数
* 假设你的hdfs上有一个/input/demo.txt,hdfs还有一个/output/,保存我们的数据结果
* 申明一个Hadoop专属的配置参数的方法
*/
Configuration conf=new Configuration();
//对外部用户输入参数的设置
String [] arglist=new GenericOptionsParser(conf, args).getRemainingArgs();
//作业设置
Job job=Job.getInstance(conf, "My first program of Hadoop");
job.setJarByClass(WordCount.class);//设置jar包的执行程序类文件
job.setMapperClass(wordCountMapper.class); //指定Mapper运行类文件
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(wordCountReducer.class);
//最终结果的输出格式
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//最终结果的地方/路径
FileInputFormat.addInputPath(job, new Path(arglist[0]));
FileOutputFormat.setOutputPath(job, new Path(arglist[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}三:导出为jar包
右击文件的包”wordCount”——>Export
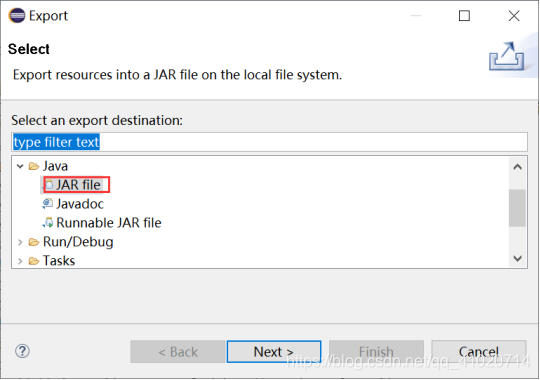
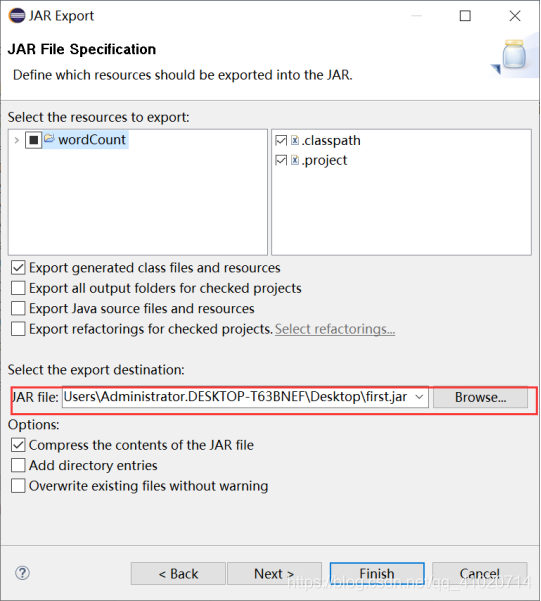
"JAR file"中填入jar的文件名,点击Finish

四:Linux下运行first.jar
1.hadoop下创建input文件夹
hadoop fs -mkdir /input
2.从本地拉去数据test.txt到hadoop下
hadoop fs -put /root/test.txt /input
![]()
报错:"Name node is in safe mode",是因为安全模式打开了,关闭了就好了。
hadoop dfsadmin -safemode leave

3.查看input下的文件
hadoop fs -ls /input
![]()
4.将jar包传到服务器,这里传到的目录为/root/zwq/pagesJar/first.jar
5.hadoop运行first.jar
hadoop jar /root/zwq/pagesJar/first.jar /input/test.txt /output
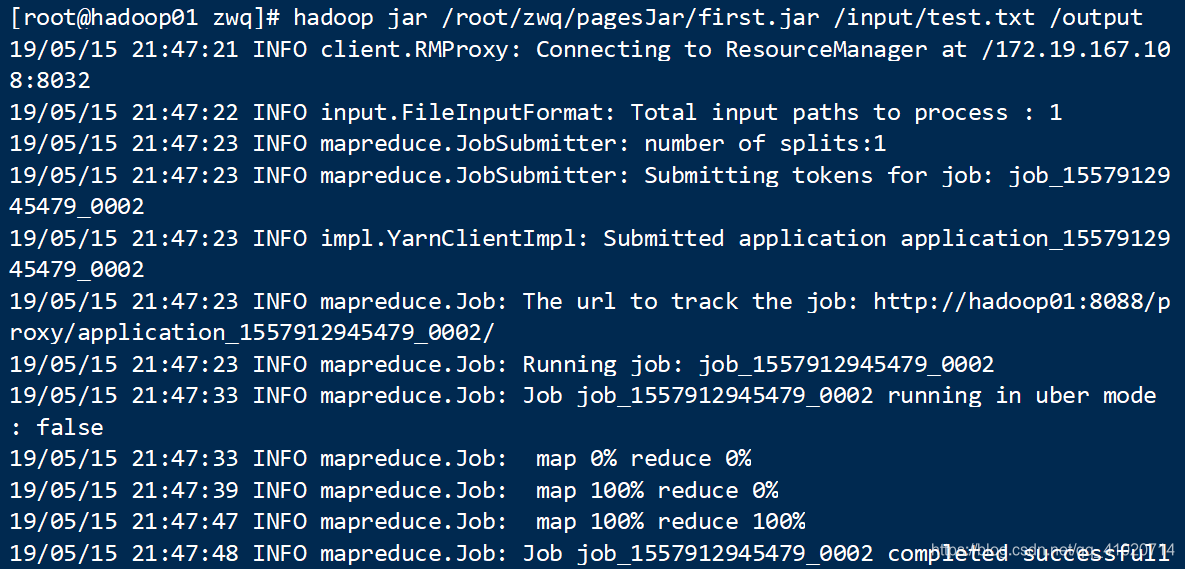
此时运行成功....
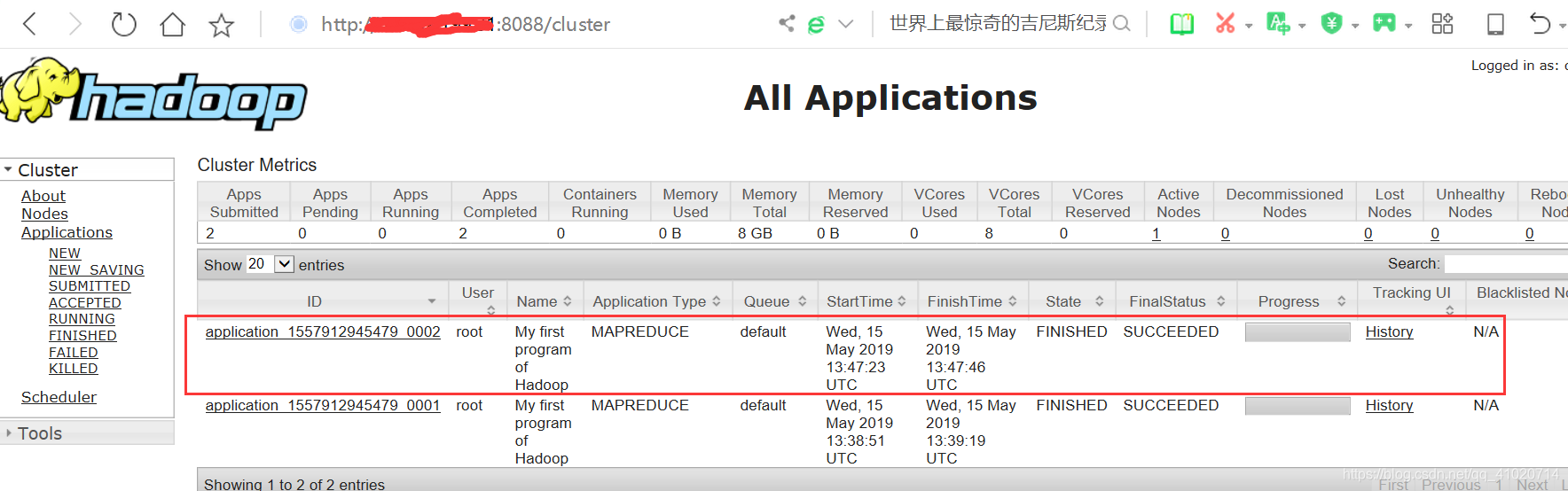
五:查看运行结果
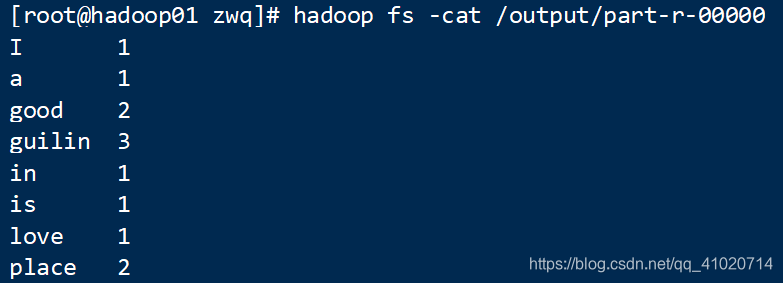
hadoop fs -ls /output

hadoop fs -cat /output/part-r-00000

















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









