







视频来源1:Transformer从零详细解读(可能是你见过最通俗易懂的讲解)
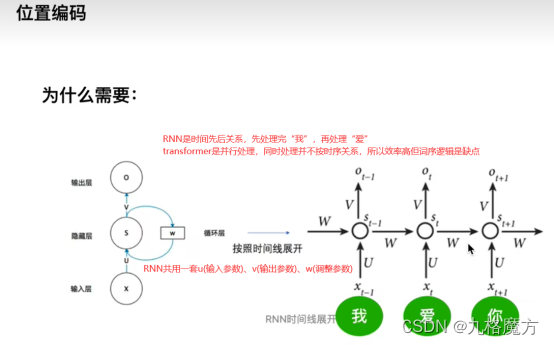
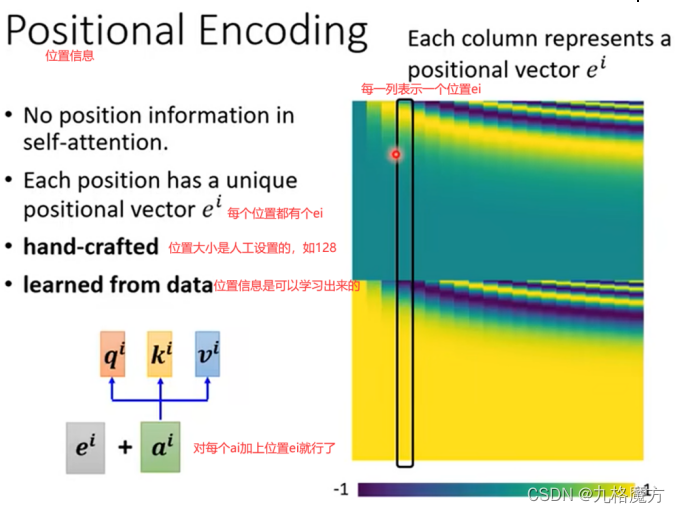
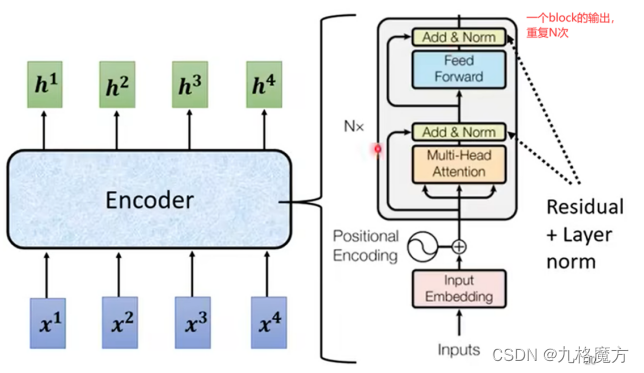
(由于transformer是并行处理,因此Transformer需要位置编码告诉单词出现的位置在哪)

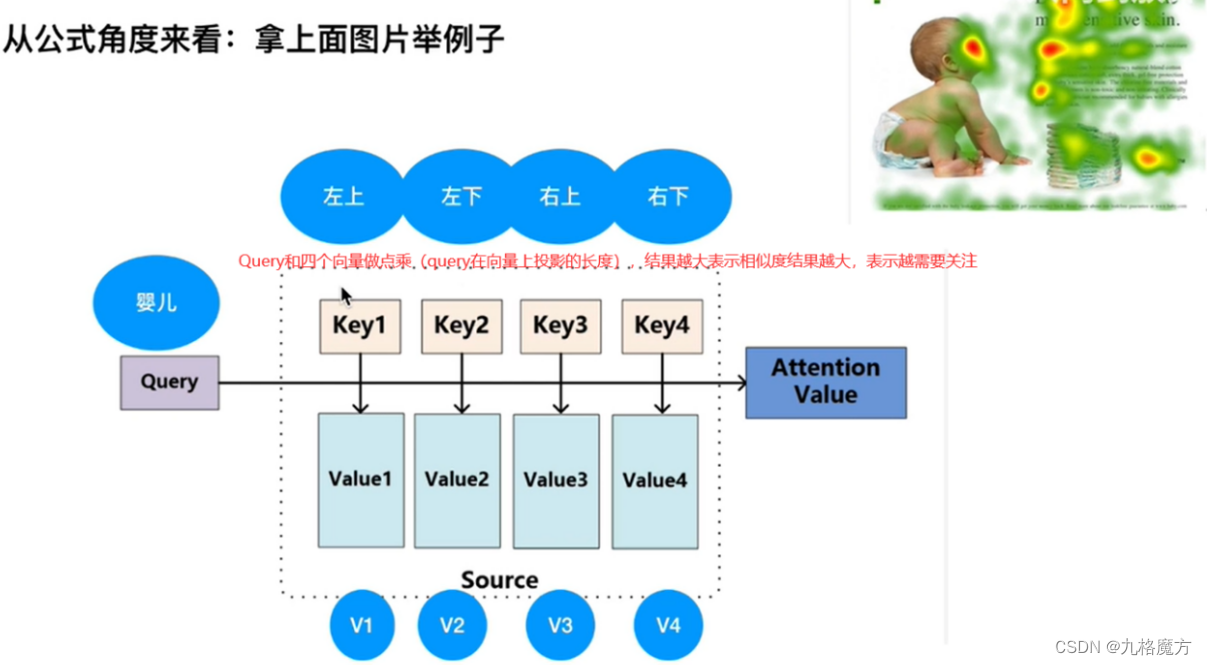
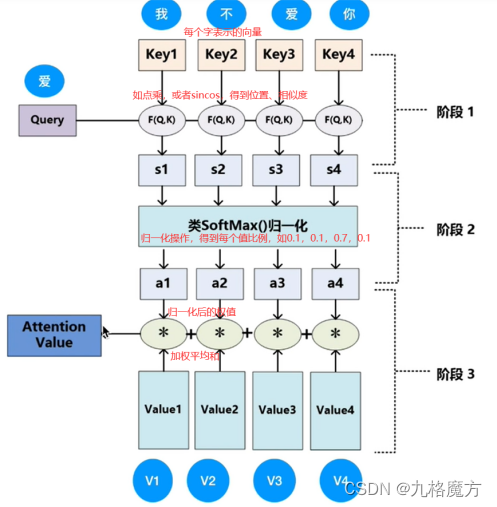
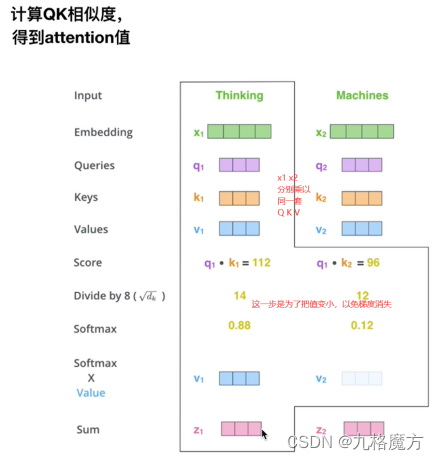
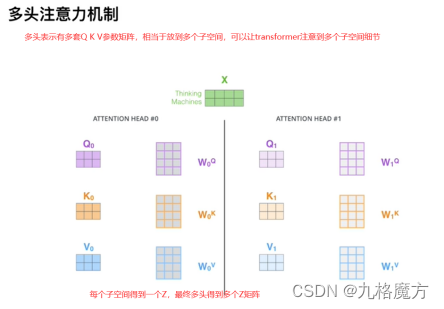
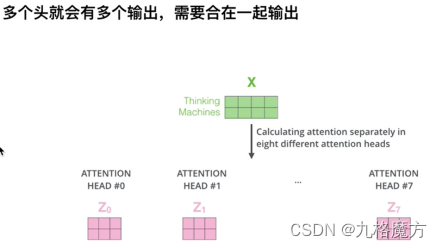
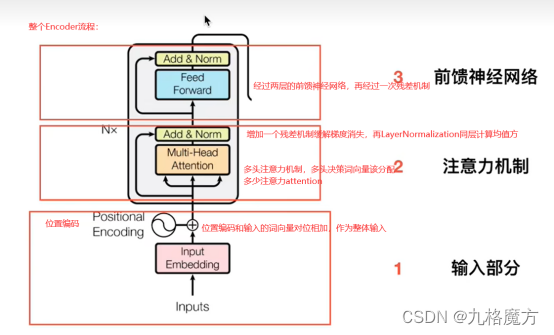
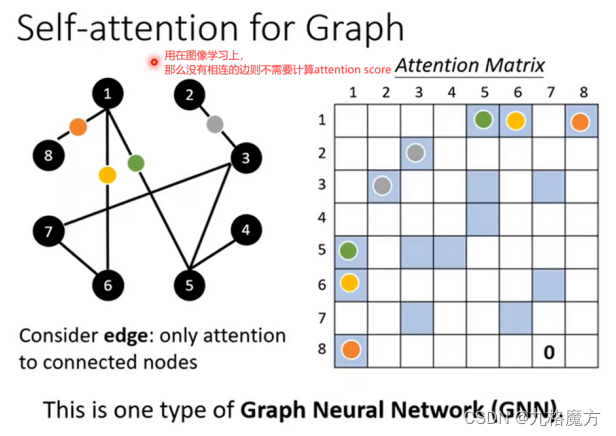
该层为注意力层,表示对输入的词向量投入多少注意力attention
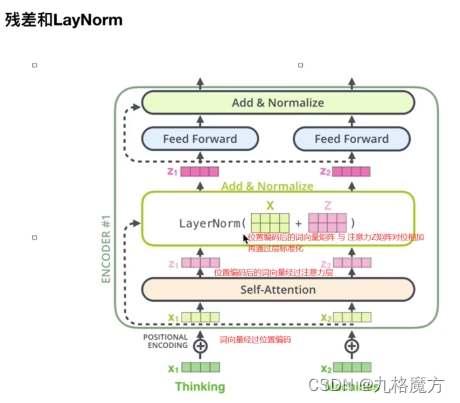
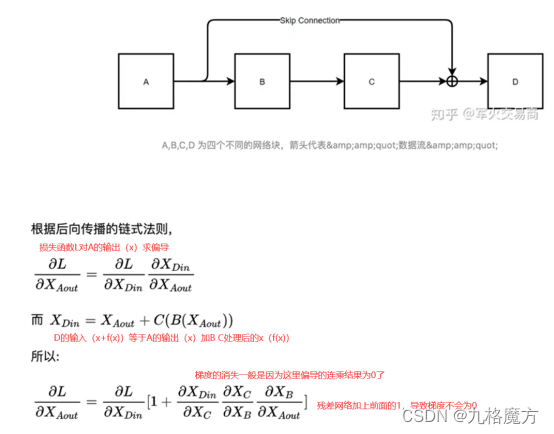
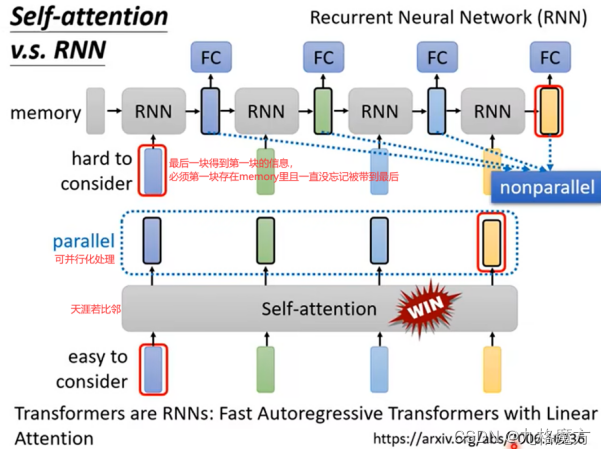
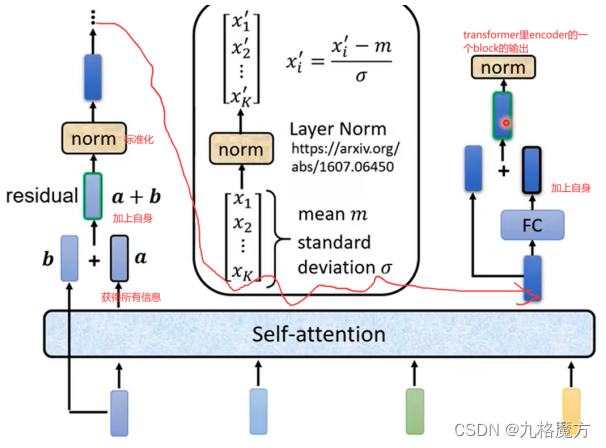
残差网络缓解了梯度消失,使得RNN可以往深了做
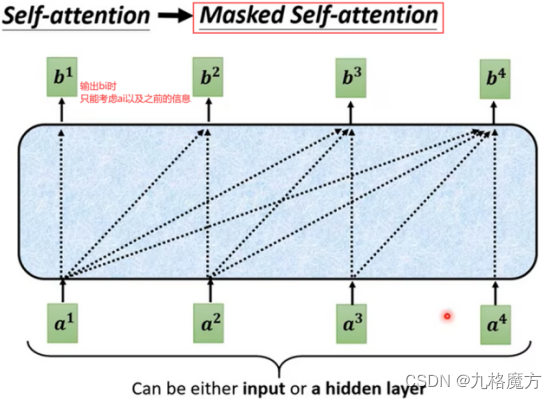
 Masked↑
Masked↑
视频来源2:
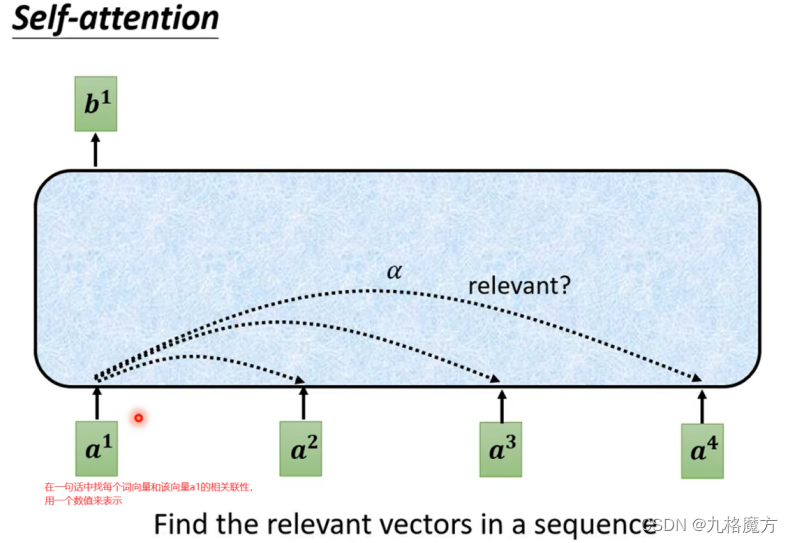
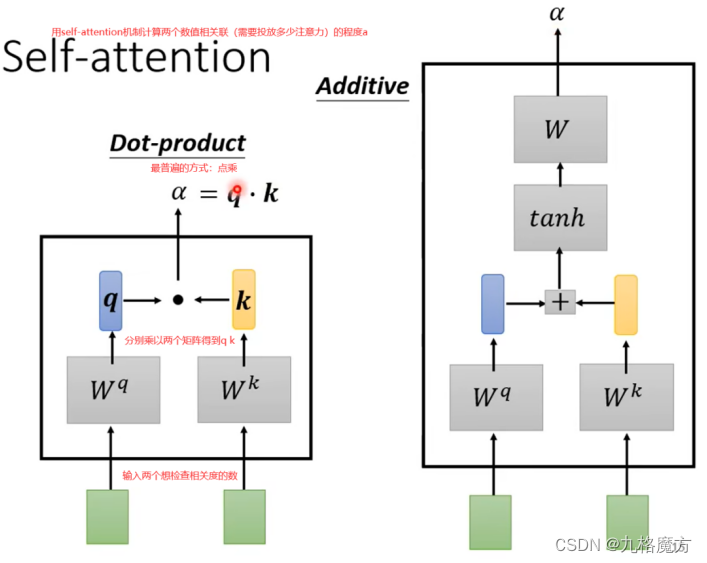
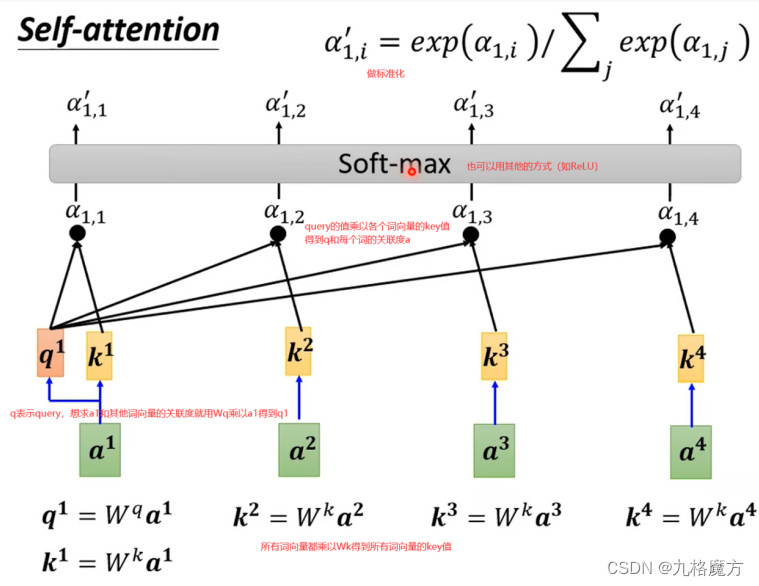
怎么计算a↓
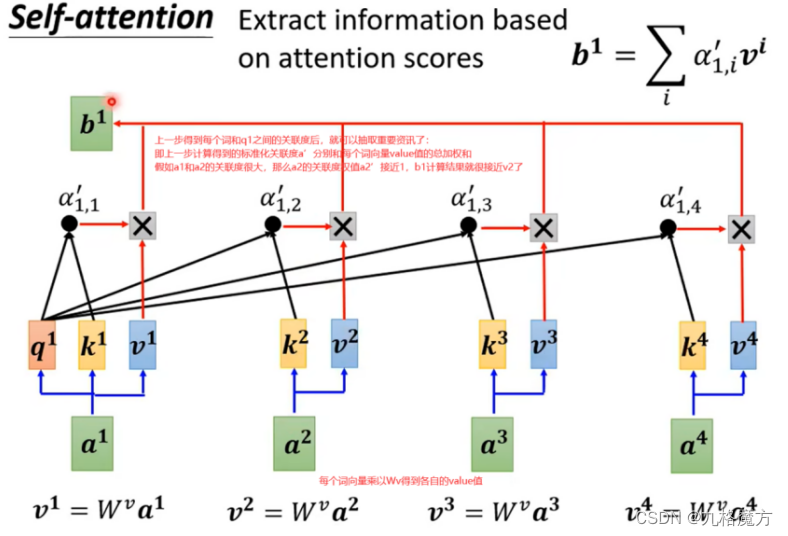
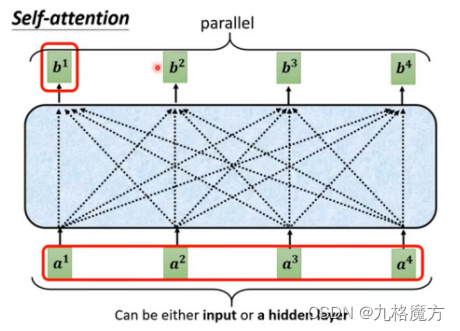
(从一整个sequence→得到b1、b2…的过程如上)
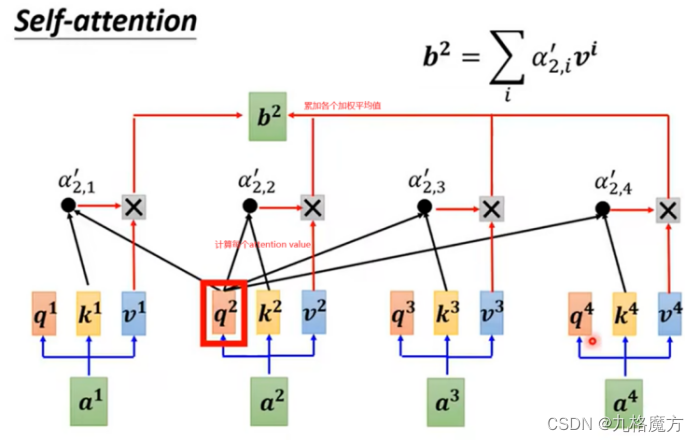
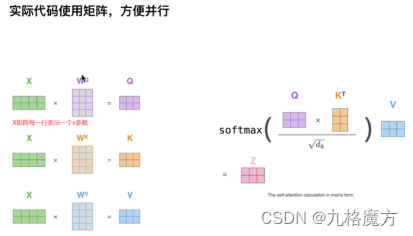
矩阵角度解释过程↓
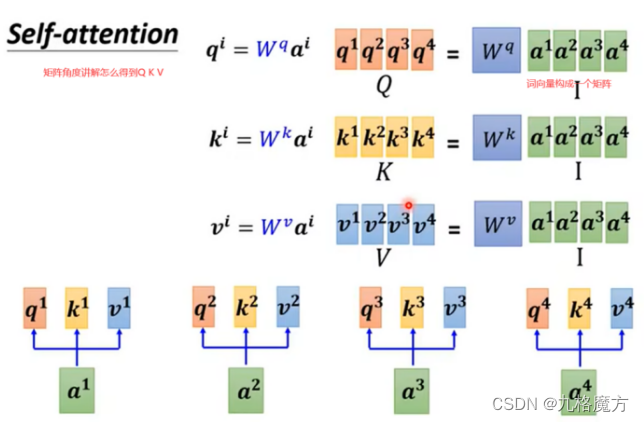
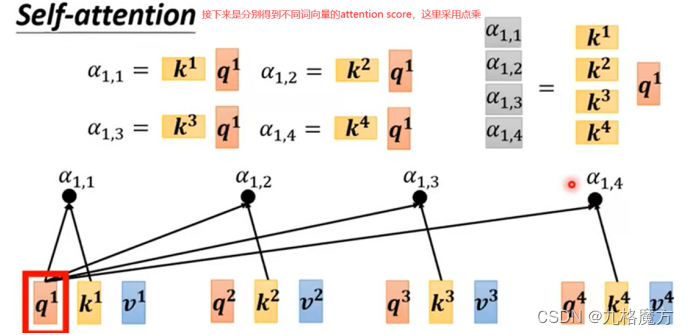
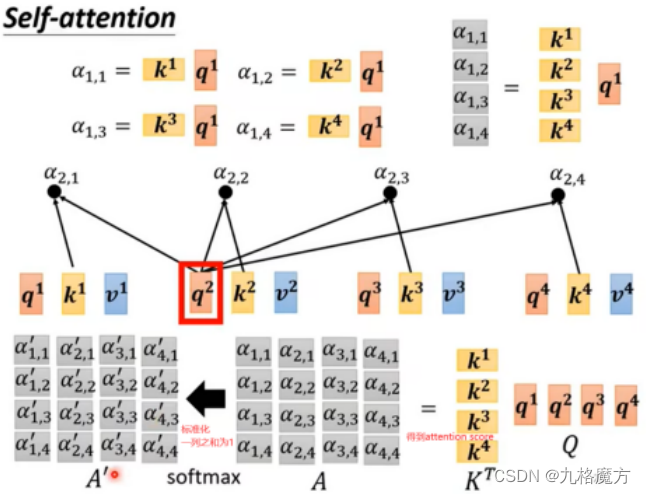
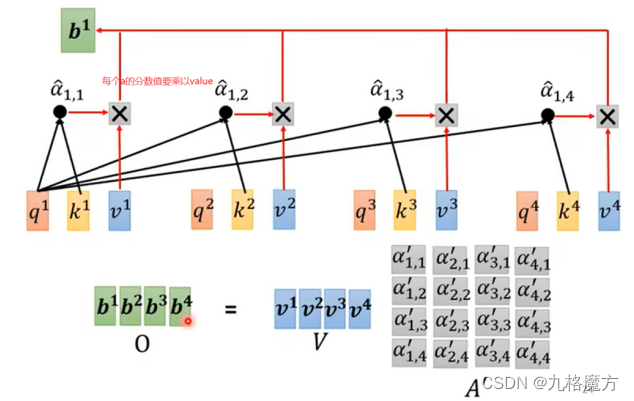
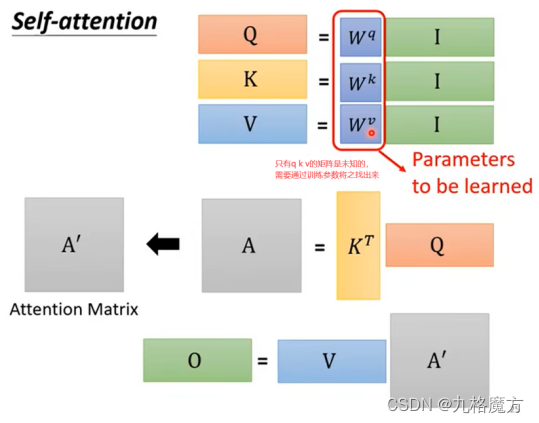
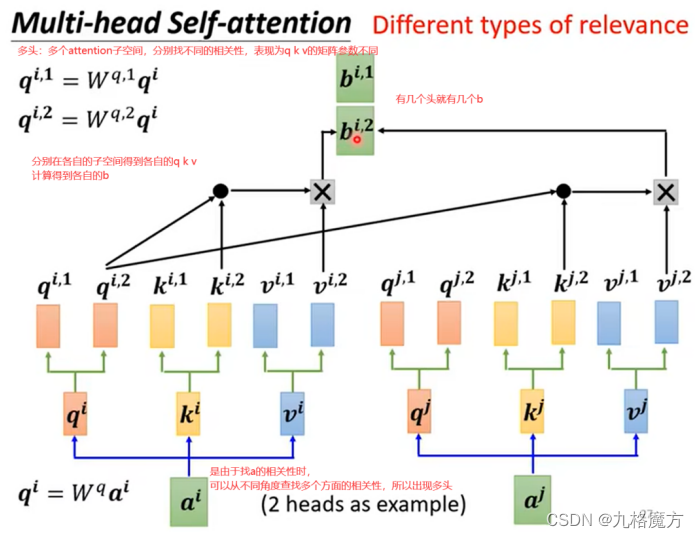
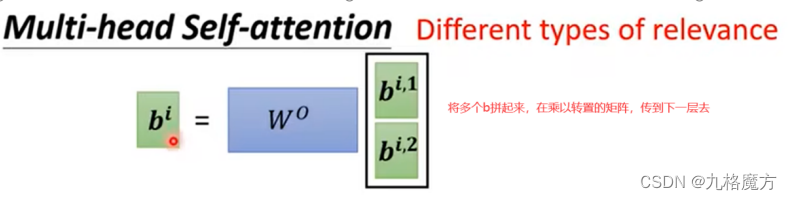
接下来,对于self-attention,句子中每个a都是并行进行的,并不知道各自ai的位置咨讯,我们是为了方别理解添加了ai中的位置“i”,而计算机并不知道。因此要添加位置信息参数
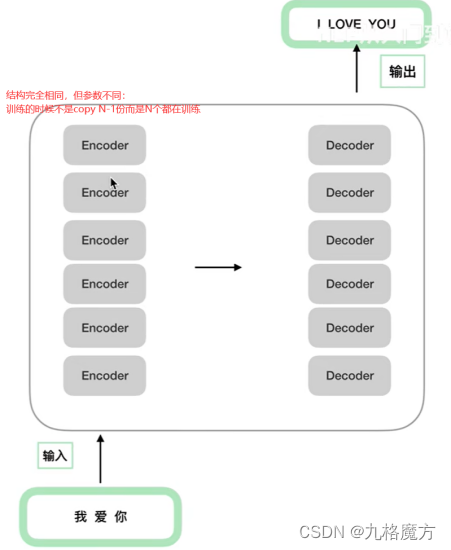
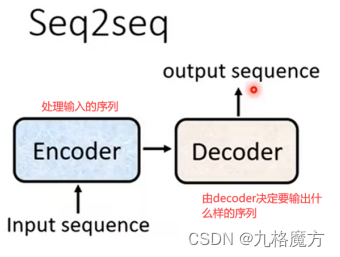
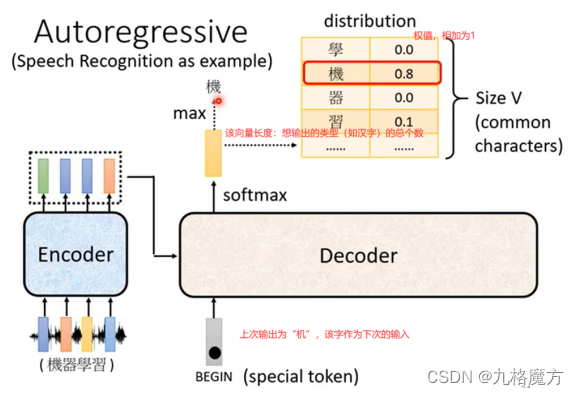
Transformer:seq2seq的模型
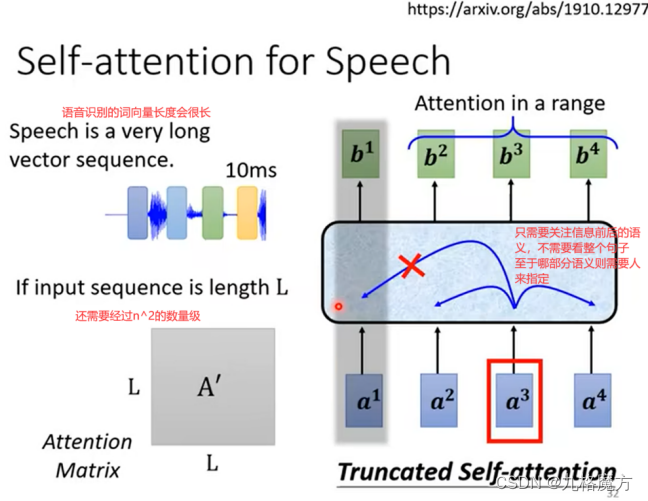
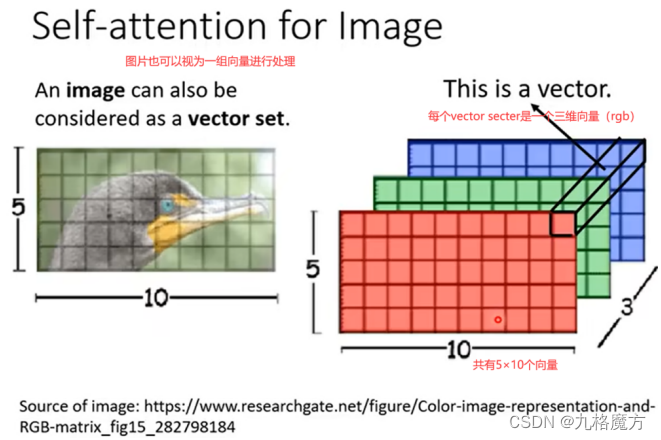
Transformer的应用:语音识别 翻译 多标签分类 物体识别
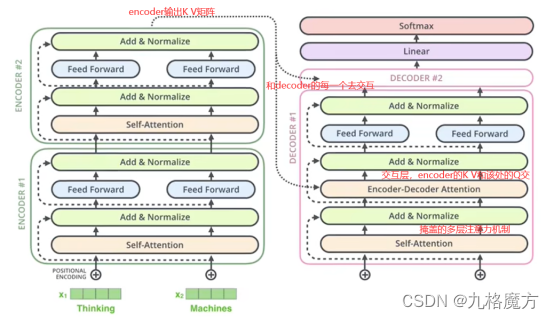
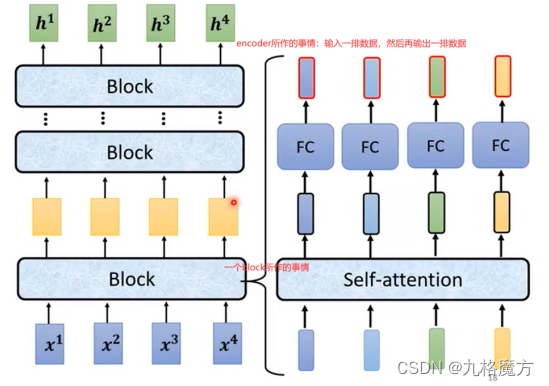
Encoder
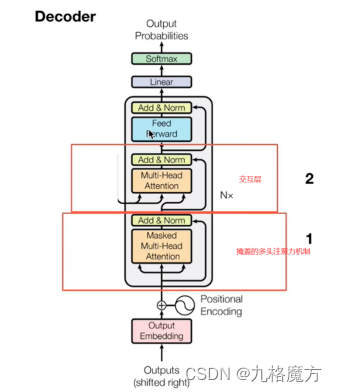
Decoder
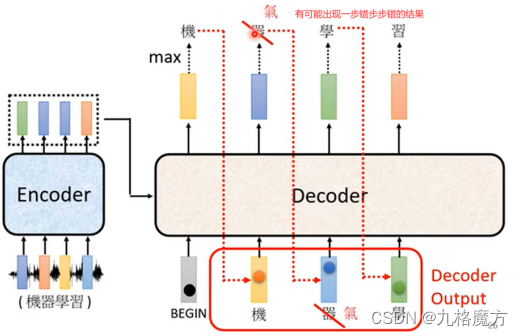
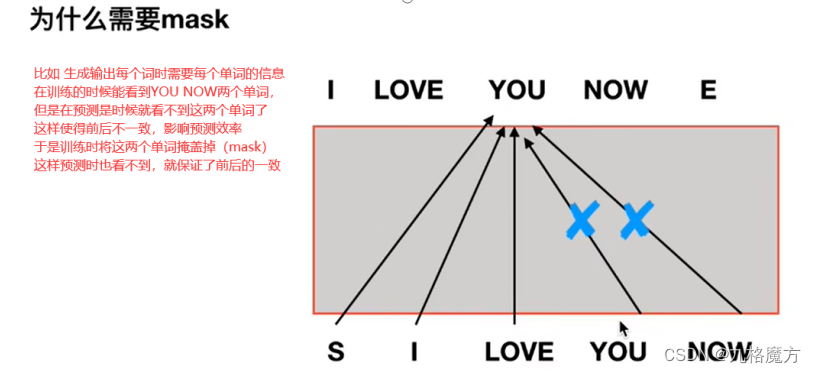
Masked↑ 为了保证训练和预测时,看到的数据保持一致 例如↓
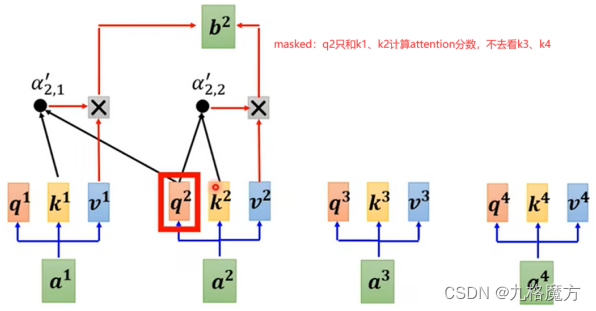
Why masked?decoder的运作方式是一个一个输出的(和self-attention不一样,self-attention是一次性几个数据全输入到model里没有位置距离远近的) 先有a1再有a2,计算b2的时候还没有a3、a4考虑进来
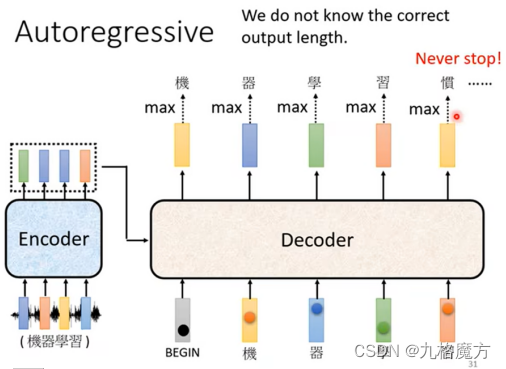
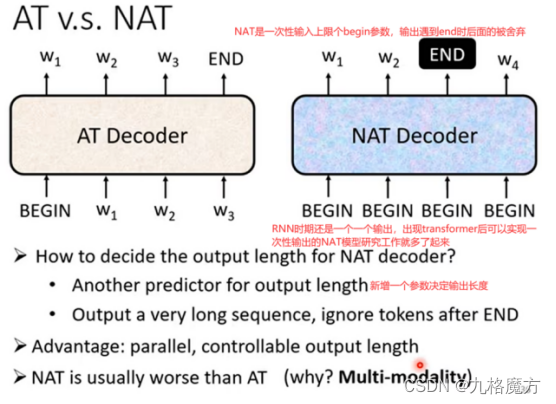
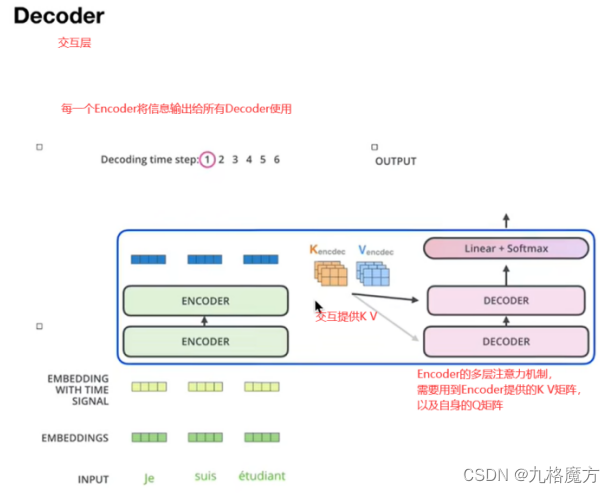
Encoder&Decoder传递信息:
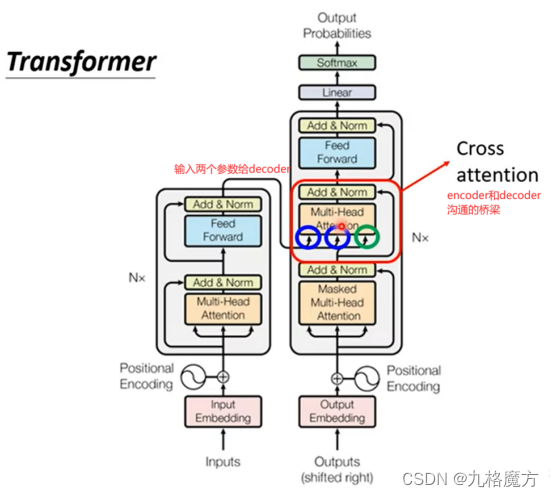
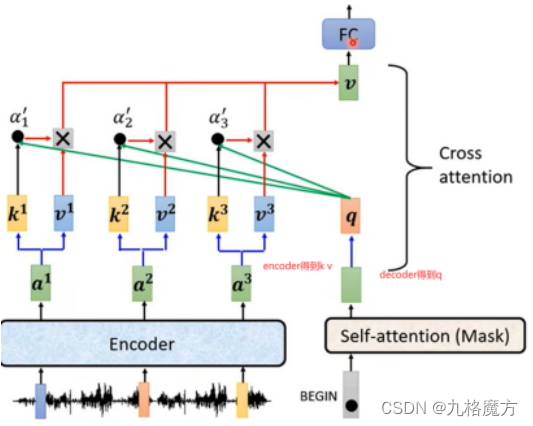
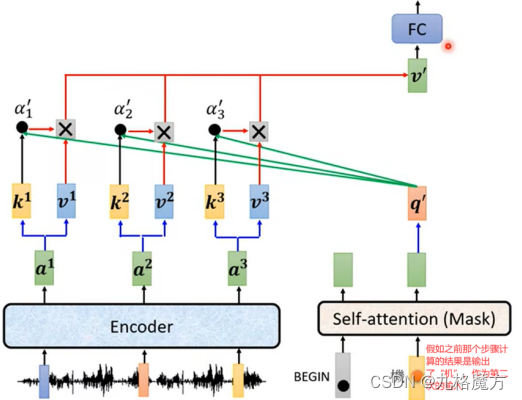
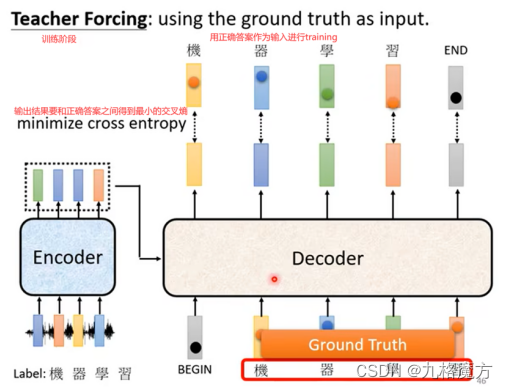
Training阶段↓
Copy mechanism:看不懂的话,机器会进行复制
Guided attention:语音合成 输入和输出结果会自动联合
Beam search:需要有创造力 有很多答案的类型 更适合 如给出故事的前段自己弥补后面的 期待随机性
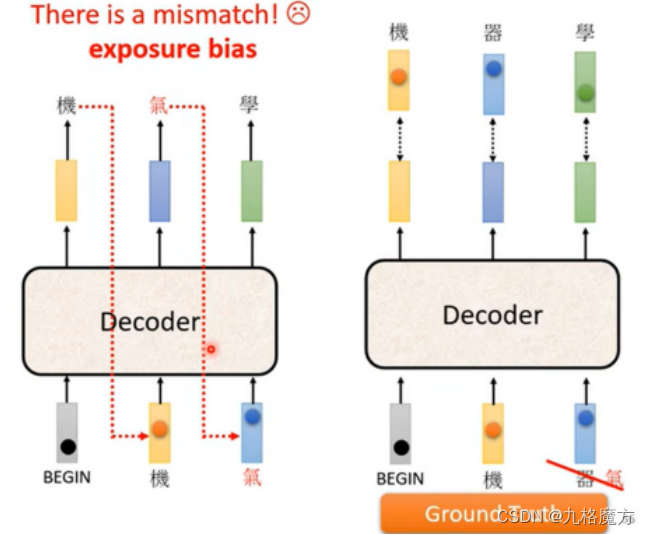
Scheduled sampling训练的时候偶尔给错误的东西反而学的很好 以防一步错步步错


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









