







synchronize的作用
https://blog.youkuaiyun.com/weixin_43732955/article/details/93588860
1、Springbean 的生命周期:
参考:https://www.cnblogs.com/redcool/p/6397398.html
注意:在IoC容器启动之后,并不会马上就实例化相应的bean,此时容器仅仅拥有所有对象的BeanDefinition(BeanDefinition:是容器依赖某些工具加载的XML配置信息进行解析和分析,并将分析后的信息编组为相应的BeanDefinition)。只有当getBean()调用时才是有可能触发Bean实例化阶段的活动
- 为什么说有可能触发Bean实例化阶段?
因为当对应某个bean定义的getBean()方法第一次被调用时,不管是显示的还是隐式的,Bean实例化阶段才会被触发,第二次被调用则会直接返回容器缓存的第一次实例化完的对象实例(因为默认是singleton单例,当然,这里的情况prototype类型的bean除外)
2、spring mvc框架中请求的流转过程:
参考:https://www.cnblogs.com/leskang/p/6101368.html
3、实现一个单利模式的方法:
参考网址:https://www.cnblogs.com/zhaoyan001/p/6365064.html
4、写一个快速排序算法:(二分法排序)
- 二分法的思想:
对于区间[a,b]上连续不断且f(a)·f(b)<0的函数y=f(x),通过不断地把函数f(x)的零点所在的区间一分为二,使区间的两个端点逐步逼近零点,进而得到零点近似值的方法叫二分法。
- 主要代码如下:
int[] arr = {49, 38, 65, 97, 76, 13, 27, 49, 78, 34, 12, 64, 1};
for (int i = 1; i < arr.length; i++) {
int temp = arr[i]; //要插入的第i个元素
int low = 0;
int high = i - 1; //插入目标元素的前 i-1 个元素
int mid = -1;
while (low <= high) {
mid = low + (high - low) / 2;
if (arr[mid] > temp) {
high = mid - 1;
} else {
// 元素相同时,也插入在后面的位置
low = mid + 1;
}
}
// 目标位置 之后的元素 整体移动一位
for(int j = i - 1; j >= low; j--) {
arr[j + 1] = arr[j];
}
arr[low] = temp;
}
for (int i = 0; i < arr.length ; i++) { System.out.print(arr[i]+" "); }
5、与Ajax有关的
https://blog.youkuaiyun.com/qq_40981804/article/details/93743577
ajax由什么部分组成(ajax 简称是 Asynchronous Javascript And Xml(异步的JavaScript和XML))
1.ajax由 JavaScript xml css XMLHttpRequest 组成
1.javascript 负责向服务器请求
2.xml负责封装数据
ajax创建有4个步骤
1.创建XMLHttpRequest
2.设置请求方法和请求的url
3.设置相应的回调方法,用于告知调用者现在的状态
4.发送请求到服务器
ajax的属性
6、spring框架的启动过程
https://blog.youkuaiyun.com/zuochao_2013/article/details/81906611
7、spring框架中IOC应用了Java的反射,具体体现在哪行代码上:
例如:String BEAN_NAME=“com.xp.类命”;
在Spring的配置文件中,经常看到如下配置:
<bean id="courseDao" class="com.qcjy.learning.Dao.impl.CourseDaoImpl"></bean>
下面是Spring通过配置进行实例化对象,并放到容器中的伪代码:
//解析<bean .../>元素的id属性得到该字符串值为“courseDao”
String idStr = "courseDao";
//解析<bean .../>元素的class属性得到该字符串值为“com.qcjy.learning.Dao.impl.CourseDaoImpl”
String classStr = "com.qcjy.learning.Dao.impl.CourseDaoImpl";
//利用反射知识,通过classStr获取Class类对象
Class<?> cls = Class.forName(classStr);
//实例化对象
Object obj = cls.newInstance();
//container表示Spring容器
container.put(idStr, obj);
参考:https://blog.youkuaiyun.com/mlc1218559742/article/details/52774805
8、redis的集群原理
https://www.cnblogs.com/liouwei4083/p/6073120.html
9、redis的存储结构
https://www.cnblogs.com/guanghe/p/9122684.html
10、redis的三种集群方式
https://www.cnblogs.com/51life/p/10233340.html
11、js中的就打内置对象

12、statement和prepare statement的关系与区别
关系:PreparedStatement继承自Statement,都是接口
区别:PreparedStatement 可以使用占位符,是预编译的,批处理比Statement效率高
Statement 用于执行静态 SQL 语句并返回它所生成结果的对象。
详解: https://blog.youkuaiyun.com/lsx2017/article/details/82630838
13、hashmap的使用、存储与查找
hashmap的使用:在执行SQL语句进行查询的时候,可以用hashmap,添加参数。
HashMap的存储结构
- HashMap底层是以数组方式进行存储的。将key-value键值对作为数组的一个元素进行存储。
- Key-value都是Map.Entry中的属性。其中将key的值进行hash之后进行存储,即每一个key都是计算hash值,然后再存储。每一个hash值对应一个数组下标,数组下标是根据hash值和数组长度计算得来的。
- 由于不同的key值可能具有相同的hash值,即一个数组的某个位置出现两个相同的元素,对于这种情况,hashmap采用链表的形式进行存储。
hashmap的原理查找扩容
简单的来说就是通过计算hash值,即数组的下标。
https://www.cnblogs.com/Jacck/p/8034558.html
hashmap的hash值是如何算的
static int hash(int h) {
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
hash()方法也叫扰动算法:可以有效降低冲突概率。
总结:
a. hash 函数并不能保证得到唯一的输出值,不同的输入也有可能得到相同的输出。
b. HashMap 中的 hash() 方法,将 hashCode 的高位和低位混合起来,降低冲突概率。
c. HashMap 中解决冲突的办法是采用链地址法(jdk7)。
d. HashMap 的初始长度为 16,且每次扩容都必须以 2 的倍数(2^n)扩充。因为在 HashMap 中,采用按位与运算(&)代替取模运算(&),当 b = 2^n 时,a % b = a & (b - 1) 。
https://www.jianshu.com/p/bafb7a3bf6df
如何在使用hashmap的时候保证线程安全
1.替换成Hashtable,Hashtable通过对整个表上锁实现线程安全,因此效率比较低
2.使用Collections类的synchronizedMap方法包装一下。方法如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) 返回由指定映射支持的同步(线程安全的)映射
3.使用ConcurrentHashMap,它使用分段锁来保证线程安全
14、数据结构有哪几种类型
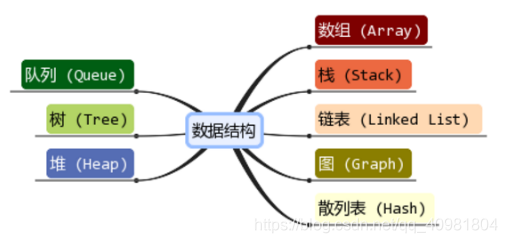
常用数据结构 · 数组(静态数组、动态数组)、线性表、链表(单向链表、双向链表、循环链表)、队列、栈、树(二叉树、查找树、平衡树、线索树、线索树、堆)、图等的定义、存储和操作 · Hash(存储地址计算,冲突处理)
15、死锁的四个必要条件,如何避免和预防
https://www.cnblogs.com/bopo/p/9228834.html
16、如何保证两个数据库之间不重复
如果是两个数据库的话,主键自增,一个插入偶数,一个插入奇数
https://blog.51cto.com/sndapk/922606
17、二叉树的遍历,若使用非递归的方法呢
前序遍历得非递归写法要根据递归运行步骤用栈来实现前序遍历。前序遍历就是在有孩子得情况下先遍历自己再管孩子。每次遍历完自己就从栈中pop出来,再把孩子push到栈里。如此循环就能实现前序遍历。
https://blog.youkuaiyun.com/wangdong20/article/details/86879562
18、如何在一个事务中写一些其他的东西,例如想往redis中存储数据
19、Linux查看日志的相关命令
1.查看日志常用命令
-
tail: tail[参数 ] [文件名]
参数:-f 循环读取 -q 不显示处理信息 -v 显示详细的处理信息 -c<数目> 显示的字节数 -n 是显示行号;相当于nl命令 -n<行数> 显示文件的尾部 n 行内容 --pid=PID 与-f合用,表示在进程ID,PID死掉之后结束 -q, --quiet, --silent 从不输出给出文件名的首部 -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒例子如下:
tail -100f test.log 实时监控100行日志 tail -n 10 test.log 查询日志尾部最后10行的日志; tail -n +10 test.log 查询10行之后的所有日志; -
head:跟tail是相反的,tail是看后多少行日志;例子如下:
head -n 10 test.log 查询日志文件中的头10行日志; head -n -10 test.log 查询日志文件除了最后10行的其他所有日志; -
cat: tac是倒序查看,是cat单词反写;例子如下:
cat -n test.log |grep "debug" 查询关键字的日志
2. 应用场景一:按行号查看—过滤出关键字附近的日志
1)cat -n test.log |grep "debug" 得到关键日志的行号
2)cat -n test.log |tail -n +92|head -n 20 选择关键字所在的中间一行. 然后查看这个关键字前10行和后10行的日志:
tail -n +92表示查询92行之后的日志
head -n 20 则表示在前面的查询结果里再查前20条记录
3. 应用场景二:根据日期查询日志
sed -n '/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p' test.log
特别说明:上面的两个日期必须是日志中打印出来的日志,否则无效;
先 grep '2014-12-17 16:17:20' test.log 来确定日志中是否有该 时间点
4.应用场景三:日志内容特别多,打印在屏幕上不方便查看
(1)使用more和less命令,
如: cat -n test.log |grep "debug" |more 这样就分页打印了,通过点击空格键翻页
(2)使用 >xxx.txt 将其保存到文件中,到时可以拉下这个文件分析
如:cat -n test.log |grep "debug" >debug.txt
20、Linux给用户设置权限
https://www.cnblogs.com/aidegongyang/p/10021415.html
21、二叉树的遍历
-
二叉树的定义
/** * 二叉树的定义 */ public class TreeNode { //此节点的值 int val; TreeNode left; TreeNode right; TreeNode(int x) { val = x; } } -
二叉树层次遍历
/** * 二叉树的层次遍历 * @param root 二叉树的根节点 * @return */ public List<List<Integer>> levelOrder(TreeNode root) { List<List<Integer>> res = new ArrayList(); //边界条件 if (root == null) return res; //创建的队列用来存放结点,泛型注意是TreeNode Queue<TreeNode> q = new LinkedList(); q.add(root); //队列为空说明已经遍历完所有元素,while语句用于循环每一个层次 while (!q.isEmpty()) { int count = q.size(); List<Integer> list = new ArrayList(); //遍历当前层次的每一个结点,每一层次的Count代表了当前层次的结点数目 while (count > 0) { TreeNode temp = q.peek(); //遍历的每一个结点都需要将其弹出 q.poll(); list.add(temp.val); //迭代操作,向左探索 if (temp.left != null) q.add(temp.left); if (temp.right != null) q.add(temp.right); count--; } //将结果存放到集合中 res.add(list); } return res; } -
二叉树前序遍历
/** * 前序遍历(递归) * @param biTree */ public static void preOrderRe(TreeNode biTree) { System.out.println(biTree.val); TreeNode leftTree = biTree.left; if(leftTree != null) { preOrderRe(leftTree); } TreeNode rightTree = biTree.right; if(rightTree != null) { preOrderRe(rightTree); } } /** * 前序遍历(利用栈) * @param biTree */ public static void preOrder(TreeNode biTree) {//非递归实现 Stack<TreeNode> stack = new Stack<TreeNode>(); while(biTree != null || !stack.isEmpty()) { while(biTree != null) { System.out.println(biTree.val); stack.push(biTree); biTree = biTree.left; } if(!stack.isEmpty()) { biTree = stack.pop(); biTree = biTree.right; } } } -
二叉树中序遍历
public static void midOrderRe(TreeNode biTree) {//中序遍历递归实现 if(biTree == null) return; else { midOrderRe(biTree.left); System.out.println(biTree.value); midOrderRe(biTree.right); } } public static void midOrder(TreeNode biTree) {//中序遍历费递归实现 Stack<TreeNode> stack = new Stack<TreeNode>(); while(biTree != null || !stack.isEmpty()) { while(biTree != null) { stack.push(biTree); biTree = biTree.left; } if(!stack.isEmpty()) { biTree = stack.pop(); System.out.println(biTree.value); biTree = biTree.right; } } } -
二叉树后序遍历(难)
public static void postOrderRe(TreeNode biTree)
{//后序遍历递归实现
if(biTree == null)
return;
else
{
postOrderRe(biTree.left);
postOrderRe(biTree.right);
System.out.println(biTree.value);
}
}
public static void postOrder(TreeNode biTree)
{//后序遍历非递归实现
int left = 1;//在辅助栈里表示左节点
int right = 2;//在辅助栈里表示右节点
Stack<TreeNode> stack = new Stack<TreeNode>();
Stack<Integer> stack2 = new Stack<Integer>();//辅助栈,用来判断子节点返回父节点时处于左节点还是右节点。
while(biTree != null || !stack.empty())
{
while(biTree != null)
{//将节点压入栈1,并在栈2将节点标记为左节点
stack.push(biTree);
stack2.push(left);
biTree = biTree.left;
}
while(!stack.empty() && stack2.peek() == right)
{//如果是从右子节点返回父节点,则任务完成,将两个栈的栈顶弹出
stack2.pop();
System.out.println(stack.pop().value);
}
if(!stack.empty() && stack2.peek() == left)
{//如果是从左子节点返回父节点,则将标记改为右子节点
stack2.pop();
stack2.push(right);
biTree = stack.peek().right;
}
}
}
22、Spring中的核心类及其作用
BeanFactory:产生一个新的实例,可以实现单例模式
BeanWrapper:提供统一的get及set方法
ApplicationContext:提供框架的实现,包括BeanFactory的所有功能
点此查看详情
23、搭建mvc框架所需要的配置及作用
- 创建一个web工程 工程名自定义,创建好了之后按照MVC设计模式创建好所有的包或文件夹
- 编写项目的配置文件:spring的配置文件application-context.xml配置文件
- 编写项目的配置文件:jdbc.property配置文件
- 编写项目的配置文件:mybatis.xml配置文件
- 编写项目的配置文件:springMVC.xml配置文件
- 编写项目的配置文件:web.xml配置文件中需要配置spring和springMVC的相关内容
编写一个方法有30%的概率返回true
double random= Math.random();
if(random<0.3){
return true;
}else {
return false;
}

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









