







 本文介绍了数据库索引的基本原理,详细阐述了主键索引、唯一索引和普通索引的特性及创建方法。通过索引,可以显著提高海量数据的检索速度,将线性查找转变为二叉树查找,降低时间复杂度。
本文介绍了数据库索引的基本原理,详细阐述了主键索引、唯一索引和普通索引的特性及创建方法。通过索引,可以显著提高海量数据的检索速度,将线性查找转变为二叉树查找,降低时间复杂度。
索引:提高海量数据的检索速度。
索引的分类:
- 主键索引(primary key)
- 唯一索引(unique)
- 普通索引(index)
- 全文索引(fulltest)
1. 基本原理
新建一个表:
| 字段 | 数据类型 |
|---|---|
| id | int |
| name | varchar(20) |
假设表中有 10000 个记录,id 从 1-10000。
- 若没有建立索引,需要从头到尾遍历记录直到找到你所要查找的数据,若你要查找的 name 的 id 为10000,那么按照 id 查找你就需要查找 10000 次。时间复杂度为 O(N)。
- 如果对这个“ID”建立了索引,即从小到大进行了排序之后我们就可以采用二叉树的形式进行查找。那么我们只需要log210000次。时间复杂度为 log2N。
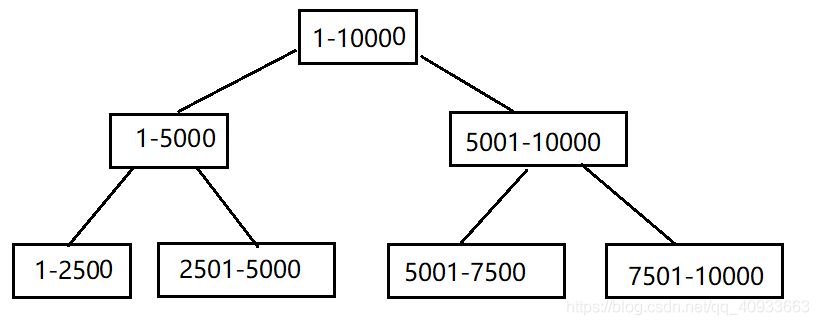
无索引是线性查找,有索引的查找是二叉树查找
2. 主键索引
特点:
- 一个表中,最多有一个主键索引
- 主键索引效率高
- 创建主键索引的嘞,它的值不能为空 (null),且不能重复
- 主键索引的列基本上是 int 类型
- 主键索引可以做外键
创建:
- 在创建表的时候,直接在字段名后指定主键索引,primary key
CREATE TABLE user1(id INT PRIMARY KEY, name VARCHAR(20));
- 在创建表的最后,指定某列或几列为主键索引
CREATE TABLE user2(id INT, name VARCHAR(20),PRIMARY KEY(id));
- 创建表之后再创建主键
CREATE TABLE user3(id INT, name VARCHAR(20));
ALTER TABLE user3 ADD PRIMARY KEY(id);
3. 唯一索引
特点:
- 一个表中可以有多个唯一索引
- 查询效率高
- 如果再某一列建立唯一索引,必须保证这列不能有重复数据
- 如果一个唯一索引上指定 not null,等价于主键索引
创建:
- 在创建表的时候,直接在某列后指定 unique 唯一属性
CREATE TABLE user1(id INT PRIMARY KEY, name VARCHAR(20) UNIQUE);
- 在创建表的最后,指定某列或几列为主键索引
CREATE TABLE user2(id INT PRIMARY KEY, name VARCHAR(20),UNIQUE(name));
- 创建表之后再创建主键
CREATE TABLE user3(id INT PRIMARY KEY, name VARCHAR(20));
ALTER TABLE user3 ADD UNIQUE(name);
4. 普通索引
特点:
- 一个表中可以有多个普通索引
- 如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
创建:
- 在创建表的时候,直接在某列后指定为普通索引
CREATE TABLE user1(id INT PRIMARY KEY, name VARCHAR(20),INDEX(name);
- 在创建表的最后,指定某列为普通索引
CREATE TABLE user2(id INT PRIMARY KEY, name VARCHAR(20));
CREATE INDEX idx_name ON user2(name);
- 创建表之后,创建一个索引名为 idx_name 的索引
CREATE TABLE user3(id INT PRIMARY KEY, name VARCHAR(20));
CREATE INDEX idx_name ON user3(name);

















 1887
1887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









