







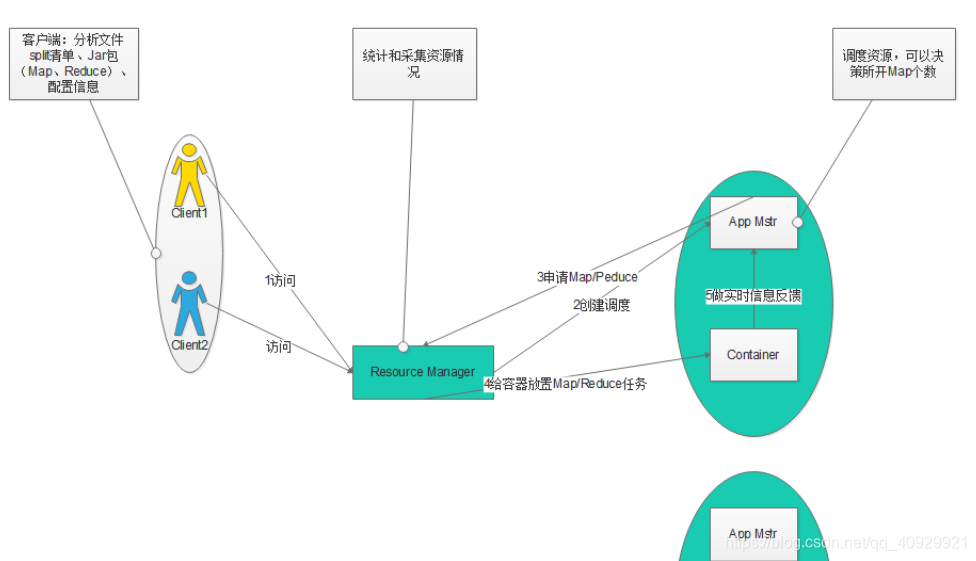
 本文介绍了大数据领域的MapReduce和YARN。MapReduce中强调了切片逻辑、map与reduce的关系,以及优化策略。切片大小可调节,map数量由切片决定,reduce数量人为设定。reduce的排序依赖map输出,MapReduce速度关键在于减少shuffle数据。YARN的工作流程包括客户端分析文件,资源管理器(RM)调度,应用管理器(App Mstr)分配任务到容器(Container)。
本文介绍了大数据领域的MapReduce和YARN。MapReduce中强调了切片逻辑、map与reduce的关系,以及优化策略。切片大小可调节,map数量由切片决定,reduce数量人为设定。reduce的排序依赖map输出,MapReduce速度关键在于减少shuffle数据。YARN的工作流程包括客户端分析文件,资源管理器(RM)调度,应用管理器(App Mstr)分配任务到容器(Container)。
大数据
MapReduce
随心记:
1.默认切片=块 所以默认map就处理一个块
2.切片大小可以人为调节,故一个切片可以对应一个或者多个map,也可以一个切片对应多个块(当要求切片数据>128M时)
3.切片是逻辑的,属于计算层
4.map数量由切片决定 reduce数量由人决定,所以map和reduce可以是任何对应关系
5.reduce最优化案例分析
1.5组数据
2.3人,每人3个程序
6.以一条记录为单位调取一个map方法,默认一行是一个记录
7.map输入以记录为单位,但记录的样式由切片决定,切片可以将输入数据样式化
8.reduce输入以组为单位,一组的可以有多条记录
9.”相同“的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
10.map的<k,v>的k主要做特征抽取
11.MapReduce运算速度快的核心是减少shuffer的数据量
12.reduce的排序强依赖map输出的排序结果
没有重排序的能力,仅可以归并数据
13.就近原则优点:数据没有移动,不会产生IO
14.为减少数据移动做法:
1、磁盘设大 2、副本设多
yarn
客户端:分析文件,做切片清单,产生配置信息,jar包(Map类、Reduce类)
RM统计资源DN情况
App Mstr调度作业
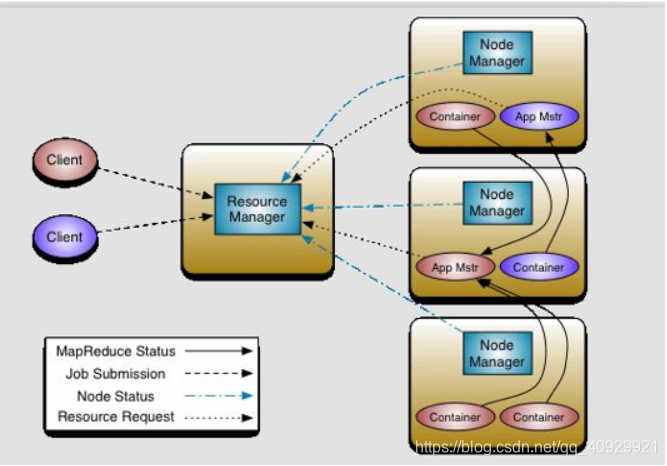
客户端访问RM,RM创建App Mstr调度,App Mstr拿清单(Map个数),返回RM申请Map/Resour,RM分配容器Container放Map任务,容器Container心跳App Mstr调度

















 10
10

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









