







索引数据结构
https://dev.mysql.com/doc/refman/8.4/en/innodb-physical-structure.html
除了空间索引(spatial index)使用R-tree之外,InnoDB索引数据结构都是B+树。每个节点都是一个Page,Page是InnoDB存储记录的最小单位。非叶子节点存储指向子节点的 key 和指针的值。叶子节点存储记录和指向相邻叶节点的指针。索引记录存储在其B+树的叶子节点Page中。索引页的默认大小为16KB。页的大小由MySQL实例初始化时的设置项innodb_page_size设置决定。
这里推荐一个B+树可视化的网站
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
聚集索引
每个InnoDB表都有一个特殊的索引,称为聚集索引。聚集索引的功能不单单只是索引,更重要的是,它用于存储引擎为InnoDB的表的所有数据行。
一个表最多只能有一个聚集索引,下面是聚集索引的选取规则:
- 当有主键时,则将主键用作聚集索引
- 当没有主键时,使用第一个
NOT NULL UNIQUE索引作为聚集索引。 - 如果以上都没有,InnoDB会在包含行ID值的合成列上生成一个名为
GEN_CLUST_INDEX的隐藏聚集索引

聚集索引按 key 也就是主键值顺序存储记录,父节点的 key 会在子节点复制一份,并且每个叶节点连接到其相邻的叶节点。这有以下几个好处:
- 双向链表允许在页之间快速移动,便于在不同页之间进行导航。这对于遍历和访问数据时非常高效,因为可以在链表中向前和向后移动。
- 在处理行插入和删除时,双向链表可以快速找到需要更新的页。这对于页的合并、分裂和重用都非常有利。
- 执行范围查询不需要扫描整个树。它所需要做的就是找到包含最小值的叶节点,然后加载下一个叶节点,以此类推,直到到达包含最大值的叶结点。
如果以随机的 key 顺序插入记录,会有性能问题。例如,添加一条键为13的记录,MySQL会将该记录保存在第8页。但是,当您使用 9 作为 key 添加记录时,会导致第7页进行拆分。在这种情况下,MySQL会在页之间移动记录并影响性能。
非聚集索引
辅助索引类似于聚集索引,区别在于,它不在叶子节点中存储数据行,而只存储辅助索引的索引 key 和聚集索引的 key (通常是主键)来查找记录:

辅助索引 key 的顺序和聚集索引 key 的顺序通常不相同,因此进行范围查询不如聚集索引有效。此外,由于辅助索引将存储聚集索引 key ,聚集索引 key 的大小将影响辅助索引的大小。
基数和选择性
基数
在数据库中,某一列的唯一键(distinct Keys)的数量叫作基数。比如性别列,该列有F、M、FM三种,所以这一列基数是 3。
SELECT count(DISTINCT column_name) FROM table_name; -- 结果 = 3
主键列的基数等于表的总行数
选择性
列的基数与表中总行数的比值再乘以100%就是某个列的选择性,公式为:选择性= (基数/ 总行数) * 100%。 查询sql如下
SELECT CONCAT((count(DISTINCT column_name) / count(*)) * 100, '%') FROM table_name;
列的选择性是衡量一个列或一组列对于过滤数据的有效程度。我们知道索引最重要的目的之一是尽可能地缩小匹配行的初始候选值,从而减少IO,提升查询性能。选择性高表示该列的值在整个表中分布得比较均匀。通常来说索引列的选择性越高则查询效率越高,因为选择性高的索引可以让数据库在查找时通过该列筛选数据可以过滤掉更多的行,这对于索引的设计和查询性能至关重要。
为什么要关注列的选择性?
- 帮助我们更好地创建复合索引:在建立复合索引时,一般我们要把选择性更高的列放在前面,以尽可能地缩小匹配行的初始候选值。
- 帮助我们更好地创建前缀索引:比如在mysql中,建立前缀索引的意义在于相对于整列建立索引,前缀索引仅仅是选择该列的部分字符作为索引,减少索引的字符可以节约索引空间,从而提高索引效率,但这样也会降低索引的选择性。建立合理前缀索引的诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长(以便节约空间)
举个例子:
我们知道辅助索引不一定是唯一的,这意味着索引中的每个键都可能包含多个值组成的列表。现在,假设我们选择了一个非常糟糕的索引(基数低),一半的表被映射到辅助索引中的一个键。这个时候索引的结构会是怎么存储呢
以下面这个用户表为例
CREATE TABLE `t_user` (
`ID` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`NAME` varchar(64) DEFAULT NULL COMMENT '名字',
`GENDER` varchar(5) DEFAULT NULL COMMENT '性别',
`MOBILE` varchar(11) DEFAULT NULL COMMENT '手机号',
PRIMARY KEY (`ID`),
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
给性别字段加上索引:ALTER TABLE t_user ADD INDEX INDEX_GENDER(GENDER);
辅助索引中的每个索引项只包含一个值。因此,如果有多行具有相同的索引key,则它们会拆分成多个索引项,即多个B+树节点(复制辅助索引的key值),每行一个。因此,如果一个1 000 000行的表的一半包含辅助键的值 F,则值 F 将在索引中重复50 0000次。
如下图所示,下图只是简单画出了 t_user 表中的 8 行数据,使用 GENDER 字段做索引的情况
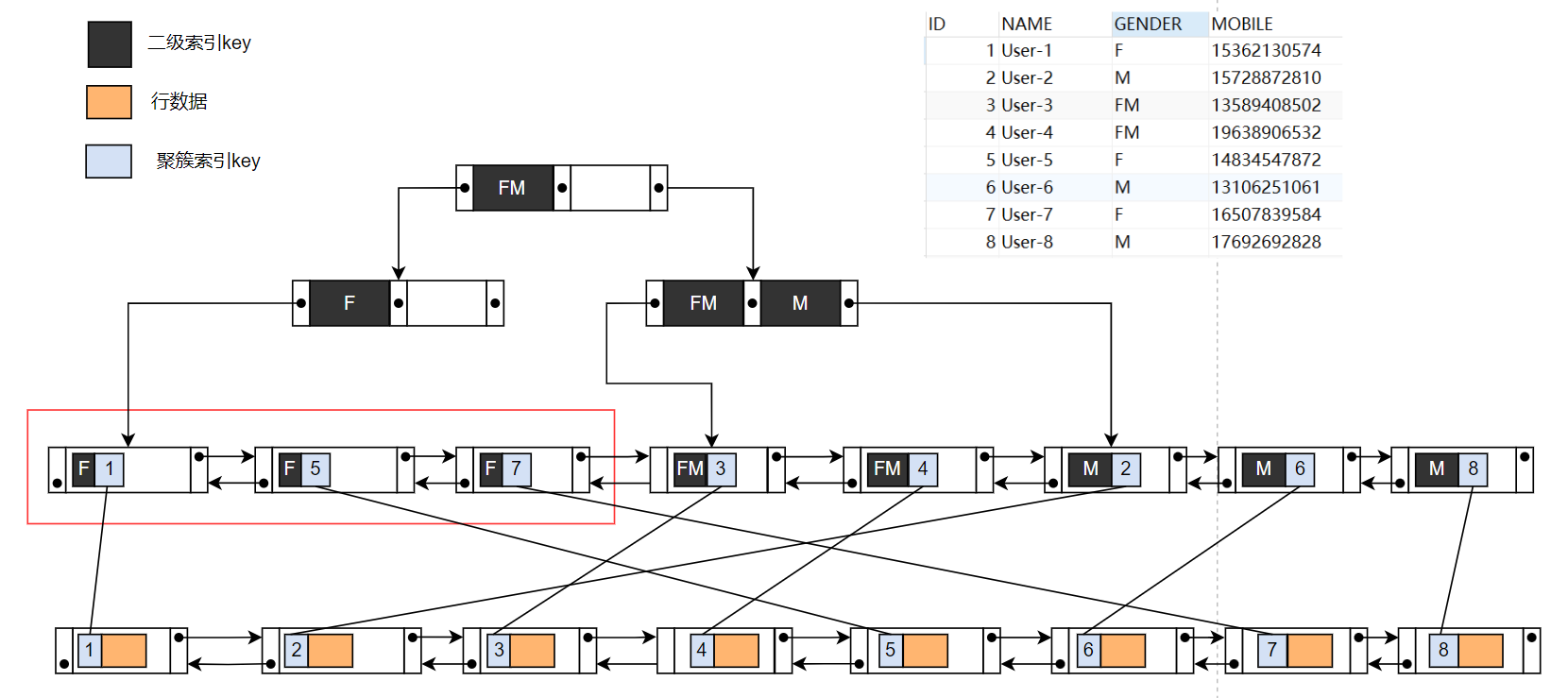
计算一下 GENDER 列的基数和选择性
-- 3
SELECT count(DISTINCT gender) FROM t_user;
-- 0.0001%
SELECT CONCAT((count(DISTINCT `GENDER`) / count(*)) * 100, '%') FROM t_user;
索引维护
MySQL不会填满整个页的空间;相反,它会为以后的修改留下空间,根据MySQL官方文档:
https://dev.mysql.com/doc/refman/8.4/en/innodb-physical-structure.html
当新记录插入到InnoDB聚集索引中时,InnoDB会尝试留出 1/16 的页空间,以便将来插入和更新索引记录。如果按顺序插入索引记录,升序或降序,则生成的索引页的大小占比约为 15/16。如果记录以随机顺序插入,则页面的大小占比为 1/2 ~ 15/16。
顺序插入和随机插入
插入数据的顺序取决于多个因素,包括表的类型、存储引擎、索引设计以及具体的插入操作。以下是一些关键情况:
- 顺序插入
自增主键:使用自增(AUTO_INCREMENT)字段时,插入的记录通常是顺序的。例如,当你插入新的行时,它们会根据自增值的顺序添加到表中。
没有竞争的插入:在没有并发插入的情况下,数据通常按插入的顺序存储。
InnoDB 存储引擎:InnoDB 使用聚簇索引(Clustered Index),数据行按照主键顺序存储,因此在自增主键的情况下,数据会顺序插入。 - 随机插入
非自增主键:如果你使用非自增主键(如 UUID 等),插入的记录可能会在不同的位置随机存储。
并发插入:在高并发环境下,多个并发插入可能会导致数据在存储中的位置不再是顺序的。
使用特定的插入策略:如果你在插入时指定了一个具体的值(而不是自增),并且这些值是随机生成的,那么数据将随机分布在表中。
表类型:
对于某些表类型(如 MyISAM),如果插入数据时没有索引,数据可能会顺序插入。然而,一旦有索引,插入可能会导致随机位置的更新。 - 影响因素
事务:在事务中,数据的插入顺序可能会因为锁机制而影响。
索引更新:当插入新记录时,索引的更新可能导致数据在存储中的位置分散。
数据分区:如果使用了数据分区,插入数据的顺序也可能受到影响。
总结
顺序插入:通常发生在使用自增主键且没有并发插入的情况下。
随机插入:发生在使用非自增主键、并发插入或特定插入策略的情况下。
为什么预留空间
在 MySQL 中,页是存储引擎用于管理数据的基本单位。预留空间在 MySQL 页管理中起着关键作用。预留空间是为了提高性能和效率,它能够减少页分裂,提高插入和更新性能,优化空间利用率,并提升整体数据库的并发处理能力和查询性能。以下是一些主要原因:
- 减少页分裂频率
当页满时,如果需要插入新数据,存储引擎会执行页分裂,导致性能下降。预留空间可以减少这种情况的发生,从而减少页分裂的频率。 - 提高插入性能
在批量插入数据时,预留空间可以容纳更多的数据,减少因频繁分裂页而导致的性能开销。 - 优化更新操作
行更新:当更新现有行的大小时,例如增加字符串长度,预留空间可以避免频繁的页移动和分裂,减少锁争用和提高并发性能。 - 提高空间利用率
预留空间有助于维持高效的空间利用率,避免频繁的页合并和碎片化,保持数据的紧凑存储。 - 支持动态行格式
动态扩展:例如,InnoDB 支持动态行格式,长行数据可以存储在不同的页中,预留空间有助于管理这些指针和数据的存储。 - 减轻锁争用
提高并发性:预留空间可以减少因页分裂导致的锁争用,从而提高数据库的并发处理能力。 - 优化读性能
缓存效果:预留的空间可以提高页的缓存效果,减少磁盘 IO,从而提高查询性能。
索引构建过程
https://dev.mysql.com/doc/refman/8.4/en/sorted-index-builds.html
InnoDB在创建或重建B+树索引时执行批量加载。这种索引创建方法被称为排序索引构建。innodb_fill_factor变量定义了在排序索引构建期间填充的每个B+树页面上的空间百分比,剩余空间保留用于未来的索引增长。innodb_fill_factor设置为100时,聚集索引页中有1/16的空间可用于未来的索引增长。
索引构建有三个阶段:
- 第一阶段,扫描聚集索引,生成索引项并将其添加到排序缓冲区。当排序缓冲区已满时,索引项将被排序,然后写入临时中间文件
- 第二阶段,第一阶段执行了一次或多次后,对写入的临时中间文件中的所有索引项执行合并排序
- 第三阶段,将排序后的索引项插入到B+树中;这个过程是多线程的
页的合并拆分
页满率:页的数据量占总数据容量的百分比
如果删除行或通过UPDATE操作缩短行时索引页的页满率低于MERGE_THRESHOLD值,InnoDB将尝试将索引页与相邻索引页进行合并。默认的MERGE_THRESHOLD值为50,最小MERGE_THRESHOLD值为1,最大值为50。
当索引页的页满率降至默认MERGE_THRESHOLD设置的50%以下时,InnoDB会尝试将索引页与相邻页面合并。如果两个页面都接近50%满,则页面合并后很快就会发生页面拆分。如果这种合并-拆分行为频繁发生,可能会对性能产生不利影响。为了避免频繁的合并拆分,您可以降低MERGE_THRESHOLD值,以便InnoDB尝试以较低的容量百分比进行页合并。以较低的页满率合并页会在索引页面中留下更多空间,并有助于减少页的合并拆分行为。
索引页的MERGE_THRESHOLD可以为表或单个索引定义。为单个索引定义的MERGE_THRESHOLD值优先于为表定义的MERGE_THRESHORD值。如果未定义,则MERGE_THRESHOLD值默认为50。
参考资料:
- https://dev.mysql.com/doc/refman/8.4/en/innodb-physical-structure.html
- https://medium.com/@genchilu/a-brief-introduction-to-cluster-index-and-secondary-index-in-innodb-9b8874d4da6a


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









