







经典问题一:如何保证缓存和数据库双写一致?(缓存更新)
该问题只是针对写操作,读操作并发量再大也不会出现数据不一致的情况。
下面有三种基本的解决方案:
1、Cache Aside Pattern(经典缓存模式)
该方案是老外提出来的,据说faceBook就是采用的这种方式。
方案内容:
读:先读缓存,若缓存存在就直接返回;若缓存不存在,就查询数据库,然后将查询结果放到缓存中。
写:先更新数据库,然后删除缓存。
为什么是删除缓存,而不是更新缓存?
更新缓存后并不是每一次都会用到,等到需要的时候在去查询数据库,更新缓存,体现的是一种懒加载思想(像 mybatis,hibernate,都有懒加载思想)。而且若缓存需要经过复杂的计算,才会被放到缓存,每次写都进行复杂的计算,造成不必要的资源浪费。
比如一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的经过复杂计算后的数据确没被访问。但如果只是删除缓存的话,那么在 1 分钟内,这个缓存只不过在访问的时候才被重新计算一次而已,开销大幅度降低,用到缓存才去算缓存。
对于该方案删除缓存失败的情况,我们还可以加入失败重试机制保证成功几率,和设置数据的有效期保证数据的最终一致性。
2、最初的缓存方案
读:先读缓存,若缓存存在就直接返回;若缓存不存在,就查询数据库,然后将查询结果放到缓存中。
写:先删除缓存,再更新数据库。
该方案只在写的顺序上与Cache Aside Pattern不一样。这样如果数据库修改失败了,那么数据库中是旧数据,缓存中是空的。读的时候发现缓存中没有,就将数据库中的数据更新到缓存中。
缺点:对同一个数据进行并发操作时也会出现数据不一致问题。比如在并发量大的时候,数据库还没开始更新时,一个读的请求过来将原来旧的数据更新到缓存中,这样缓存中是旧数据,数据库中是新数据,数据还是不一致。针对这个问题,我们有2.2延时双删这种解决方案。
2.2、延时双删方式
针对上述方案2,我们采用延时双删的方式解决并发造成的数据不一致情况,此方案应用后也会出现暂时的数据不一致情况。方案为更新数据库之后,延时一段时间后,再删除缓存。伪代码为:
cache.del(key);
db.update(data);
Thread.sleep(1200);
cache.del(key);这样即使在更新数据库前,有读的线程来将脏数据放入缓存,也会在更新完成并延迟一段时间后,将缓存中的脏数据删除,下次读取时也会将新的数据放入缓存。也可以等数据库更新完毕后,将剩下的任务放到消息队列中,采用异步的方式继续处理。
关于线程睡眠的时间,原则上应该比重进计算缓存加设置到缓存的时间总和多一点才行。若是mysql采用读写分离时,睡眠时间的计算上也应该把主从复制的时间算进去。
3、加锁
若要求数据必须实时正确的强一致性关系的话,那可以采用分布式锁的方式,使所有的请求全都串行化执行(使读和写前都要先检查是否能拿到锁,以进行下一步的操作),但这样系统中的某些接口的负载量将大幅下降,针对一些关键的地方可以使用这种方式。
综上所述:
对于数据一致性要求不是很高的情况下,采用经典缓存模式即可。对于某些数据一致性要求较高的情况下,我们辅助以分布式锁的方式保证数据的一致性。
经典问题二:缓存击穿、缓存穿透、缓存雪崩是什么情况?如何解决?缓存预热、缓存降级是什么?如何实现?
缓存击穿、缓存穿透、缓存雪崩按照对数据库的破坏程度依次递增。
1、缓存击穿
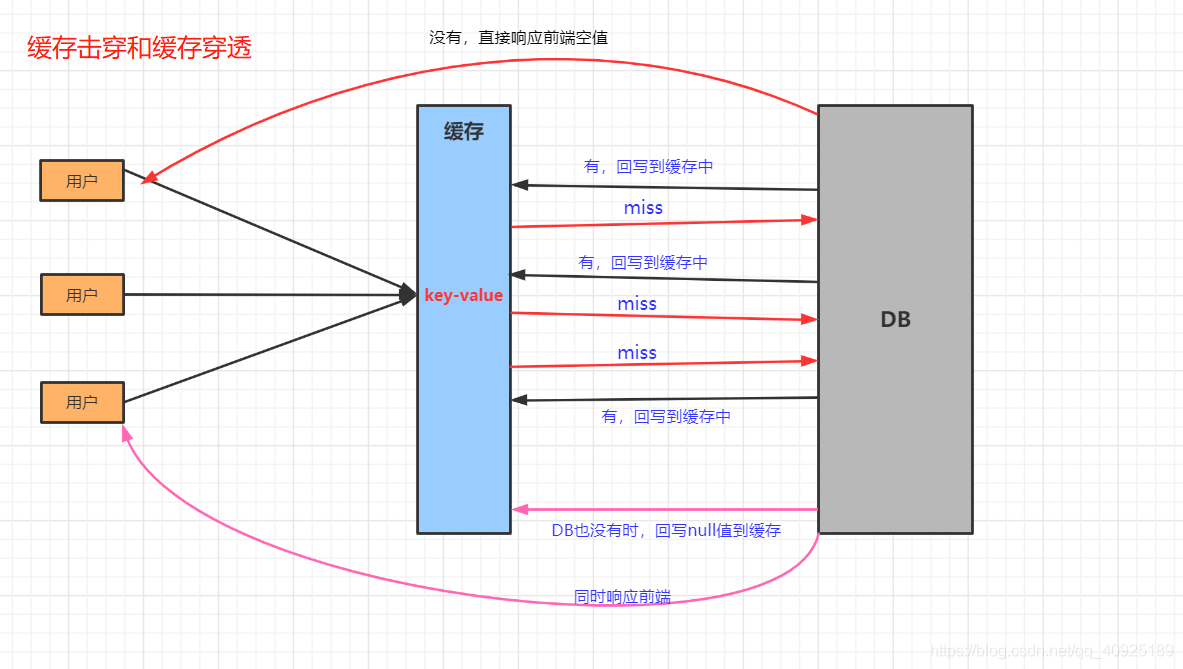
缓存击穿是指缓存中某个key不存在或key过期了,按照上面的缓存模式,此时应该从DB中读取数据并更新到缓存中。但若该key是个热点key,将会有大量的读请求冲向数据库,一时间DB压力暴增大量请求阻塞,极度情况下DB可能会宕掉。
刚开始针对某个key不存在的情况,可以采用缓存预热的方式,提前缓存好数据。
针对key过期的情况,为了保护数据库没那么大压力,一般有以下几种方式:
1、加互斥锁,至于是加分布式锁还是单机锁看情况(集群分布式环境下用分布式锁会好一些,单机时加单机锁就好了)。就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。伪代码如下:
Object result = getDataFromCache(key);
if(result != null){
return result;
}else{
synchronized(Object.class){
//注意这里要再从缓存中读取一下形成闭环,否则刚才在此锁上等待的线程,又会查询DB回写缓存。
Object result = getDataFromCache();
if(result != null){
return result;
}else {
//这里如果查询结果为null,就是缓存穿透问题了。此时缓存null值,也是解决缓存穿透的手段之一。
Object dbResult = getDataFromDB();
//回写缓存
cacheUtils.setex(key,dbResult,3600);
return dbResult;
}
}
}
加锁确实是个简单粗暴的方法,有效的保护了DB。但治标不治本,大并发情况下,会造成短时间大量请求阻塞问题。
2、热点数据永不过期
即不给热点key设置过期时间。
3、假的过期时间戳
即在设置缓存时,给每个缓存附件一个比实际过期时间小的假的过期时间戳,每次请求时若达到了假的过期时间,就利用串行删除或者用消息队列、异步线程的方式,重新更新缓存,这样只要该key一直热,他就一直有效。“你动我就动”,该方式在大并发下性能最好。
2、缓存穿透
上面缓存击穿是cache中没有,DB中有。若此时DB中也没有,就变成缓存穿透了。这样按照缓存模式的读模式,每次请求都会将缓存层和数据库层全都穿透一遍,缓存层完全失去了保护数据库层的作用。系统正常设计的情况下,一般是不会出现缓存穿透现象的,出现缓存穿透的原因一般是恶意攻击较多。知道了缓存穿透的原因,解决起来也好办了:
1、缓存空值
缓存空值是最简单有效的方式了,当DB中没查着,回写null值到缓存中。当该值有更新的时候在重新回写新的值到缓存中。思路就和上面缓存击穿时加互斥锁的代码一样。同时可以在本地使用一个保存空值对应key的缓存区域,查询时先检查是否包含某个空值key,若存在都不用查询缓存了,等更新缓存是再检查是否需要从该区域移除该空值key。
2、布隆过滤器
布隆过滤器由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组初始化均为0,所有的哈希函数都可以分别把输入数据尽量均匀地散列。由于哈希碰撞的原因,布隆过滤器有个特点:BF认为不存在的数据一定不存在,但BF认为存在的数据可能不存在。
3、具体的小操作
比如:拦截id<=0,大于多少多少请求等
3、缓存雪崩
相比于缓存击穿和缓存穿透是针对于单个key过期,缓存雪崩是多个key大面积集中过期,致使大量请求直接砸在了DB上,造成DB瞬间压力过大甚至瘫痪,对数据库危害性最大。几个比较有效的方法是:
1、均匀过期
均匀过期是解决缓存雪崩比较有效的方法,即给每个数据设置不同的过期时间(可以在原有的过期时间上加上随机时间如0-20分钟之间)。
2、假的过期时间(还是比较通用的方法)
3、加互斥锁(还是比较通用的方法)
4、设置二级缓存(还是比较通用的方法)
5、数据永不过期
4、缓存预热
从字面意思就可以看出来,缓存预热就是将热点数据,在正式对外提供服务之前预先放到缓存中,避免了缓存击穿的问题。解决方法大致分为两种:
1)数据量不大时,在项目启动的时候预热到缓存中就行。如在springBoot中可以利用实现<code>ApplicationRunner</code>接口来完成该功能。
2)数据量很大时,将缓存预热的工作单独进行,比如可以单独一个项目专门用于缓存预热功能。
5、缓存降级
缓存降级和分布式微服务中的服务降级是一个目的,都是在系统访问量巨大,导致系统的资源不足时,将一些非核心的业务暂时关闭或者限制它的一些非常消耗资源的功能,将更多地系统资源交给核心业务,要保证核心功能正常可用,算是一个弃卒保帅、集中力量办大事的思想吧。比如说我们可以限制缓存为只读的,或者读取一些本地的旧缓存,甚至直接关闭该功能。
经典问题三:几种常见的缓存使用模式
1、暂存(cache-aside pattern)
即将数据库中的数据暂时存储在缓存中,访问数据时先读取缓存,若缓存中有直接返回;缓存中没有再读取数据库,然后同步数据到缓存。写操作时先更新数据库,再删除缓存。缓存的位置是处在数据库之前,起到了加速读取和保护数据库的作用。
2、只有高速缓存(cache-as-sor)
去掉数据库,让缓存来充当数据库的角色,所有的操作全在缓存中进行。
3、直写(write-through)
当发生写操作时,所有的写操作全都在一个线程中串行执行。保证了数据的实时一致性,但每个写操作的响应时间会加长,总的降低了系统的吞吐量。
4、后写(write-behind)
当发生写操作时,将一些写操作异步执行,比如对于复杂的写操作另起一个线程去异步执行,或者像剩余操作放到消息队列里面,后续异步执行。后写不能保证数据的实时一致性,但可以保证数据的最终一致性,同时每个写操作的响应时间会缩短,总的提高了系统吞吐量。
关于缓存无非就是读和写,以上四种基本涵盖了缓存读写所有的情况,关于选用直写还是后写,可以从数据的实时一致性和系统的访问量上来综合考虑,针对具体的情况灵活运用即可。
其他问题遇到再说吧。
下一篇:系统多级缓存架构如何设计?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









