







算法复杂度分析
大O复杂度表示法
int factorial(int n) {
int sum = 1;
int i = 1;
for (; i <= n; ++i)
{
sum *= i;
}
return sum;
}
上面是一个阶乘的函数,第二三行消耗两个unit_time,四五行for语句消耗2n个unit_time,这个代码的总执行时间T(n) = (2n + 2) * unit_time,我们只需要取其中最大量级,其时间复杂度为O(n)。
时间复杂度分析
1、关注循环次数最多的一段代码
int cal(int n)
{
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}
上述代码,我们在分析他的时间复杂度时,只需要取其中循环次数最多的一串代码,就是for语句,其时间复杂度为O(n)。
2、总复杂度等于量级最大的那段代码的复杂度
int cal(int n) {
int sum_1 = 0;
int p = 1;
for (; p < 100; ++p) {
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
for (; q < n; ++q) {
sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}
上述代码总共有三个循环,第一个循环100次,是一个常量的执行时间,可以直接忽略,第二个循环n次,第三个循环n2次,这段函数量级最大的为n2,所以整段代码的时间复杂度为O(n2)。
3、嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
int cal(int n) {
int ret = 0;
int i = 1;
for (; i < n; ++i) {
ret = ret + f(i);
}
}
int f(int n) {
int sum = 0;
int i = 1;
for (; i < n; ++i) {
sum = sum + i;
}
return sum;
}
上述代码有两个函数,函数cal()调用函数f(),所以函数cal()的时间复杂度为T(n) = T1(n) * T2(n) = O(n*n) = O(n2)。
常见时间复杂度
O(1)
int f1()
{
int i = 3;
int j = 4;
int sum = i + j;
return sum;
}
int f2()
{
int sum = 0;
for(int i = 1; i <= 1000; ++i)
{
sum += i;
}
return sum;
}
上述代码,函数f1()消耗3个unit_time,为常量,可以忽略,函数f2()查看循环次数最多的,循环1000次也是一个常量,同样可以忽略,所以函数f1()、f2()的时间复杂度都为O(1)。
O(logn)、O(nlogn)
i=1;
while (i <= n) {
i = i * 2;
}
上述代码,while是循环次数最多的一项,当i > n时结束循环,每经过一次循环i的值要乘以2,写出来就是:2、22、23、24……2k,所以计算出2k = n,k的值就好, k = log2n,时间复杂度O(log2n),实际上不管是什么数为底,如:log3n = log32 * log2n,log32为常量,可以忽略,最后都可以换算为O(log2n),所以在对数阶时间复杂度的表示方法里,我们忽略对数的“底”,统一表示为 O(logn)。
O(nlogn)就是将 O(logn) 循环了n遍,比如,归并排序、快速排序的时间复杂度都是 O(nlogn)。
O(n)、O(n2)
int cal1(int n)
{
int sum = 0;
int q = 1;
for (; q < n; ++q) {
sum_2 = sum_2 + q;
}
return sum;
}
int cal2(int n)
{
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
return sum;
}
如上述代码,函数cal1()循环n次,函数cal2()循环n2次,所以cal1()时间复杂度为O(n),cal2()时间复杂度为O(n2)。
O(m+n)、O(m*n)
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}
在上述代码中,有两个循环,循环m次和n次,我们无法判断m和n谁大谁小,所以没法忽略其中一个所以上述代码时间复杂度为O(m + n)。
O(m*n)同理。
最好、最坏、平均情况时间复杂度
上述情况比较简单,而实际的运算中,会有着各种各样的问题,让人难以判断,比如下面这个查找函数。
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
上述函数就不能单纯使用之前的方法了,需要分情况而定,最好情况为查找到第一个就找到,break跳出,那么时间复杂度为O(1)。最坏情况为查找到最后一个才找到,那么时间复杂度为O(n)。
最好和最坏都是比较极端的情况下才会发生,所以我们需要使用平均时间复杂度。查找数组总共有n + 1种情况,查找数据执行的次数为:1 + 2 + 3 + …… + n + n,总共 (1 + n) * 2 / n + n。最终可以得到时间复杂度为O(n)。
查找数字不一定在数组中所以会n + 1种情况,而这个概率也有一定的问题,能够查找到和不能查找到的概率都应该为1 / 2,这样数字出现在数组中每一个的概率就不应该是1 / n,而是1 / 2n。
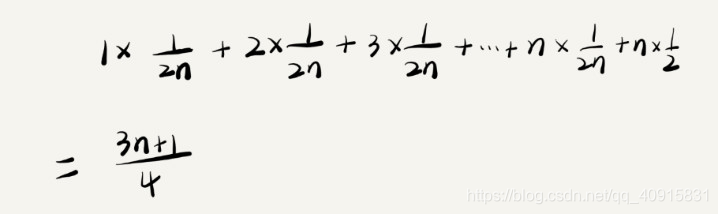
这个值就是概率论中的加权平均值,也叫作期望值,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。这样最终的时间复杂度为O(n)。
均摊时间复杂度
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
上述代码是往数组中插入数据,当数据插满时(count == array.length),将数组中所有数求和,放到数组第一个位置,并清空数组。当数组未满,插入数据,时间复杂度为O(1),当数组满了,时间复杂度为O(n),可以使用之前的平均时间复杂度计算为O(1)。
这里时间复杂度分析其实不用这么麻烦,首先对比一下函数find()和insert()。
一、find()在极端情况下为O(1),而insert()在大部分情况下为O(1)
二、insert()中O(1)插入和O(n)插入是有规律的
所以针对这种比较特殊的情况,我们可以使用均摊时间复杂度,将那一次O(n)均摊到n - 1次O(1)上,这一组连续的操作的时间复杂度就为O(1)。
总之,对一组数据进行连续的操作,并且前后有着连贯的时序关系,这个时候我们就可以将这一组操作放在一起分析,看看能不能将那一次较高的时间复杂度操作均摊到其他较低的时间复杂度上面。
常见的复杂度,从低阶到高阶有:O(1)、O(logn)、O(n)、O(nlogn)、O(n2),我们需要根据复杂度选择最合理的算法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









