







一、综合设置
1.1、-flatten_hierarchy

| 可选值 | 含义 |
|---|---|
| full | 综合时将原始设计打平,只保留顶层层次,执行边界优化 |
| none | 综合时完全保留原始设计层次,不执行边界优化 |
| rebuilt | 综合时将原始设计打平,执行边界优化,综合后将网表文件按照原始设计层次显示,故与原始设计层次相似 |
当选为none时,工具进行的优化最少,消耗的资源最多,层次保留最为完整;
当选为full时,工具进行的优化最多,消耗的资源最少,层次完全被打平(只能看到顶层)。
在通常情况下,使用默认值rebuilt即可,这样在使用Vivado Logic Analyer,可快速根据层次找到待观测信号。
-flatten_hierarchy是一个全局设置(凡是出现在综合设置中的均为全局设置),意味着对设计中的所有模块生效。
如果期望模块中的某个层次使用与-flatten_hierarchy的可选值不同的层次优化方式,则要用到相关综合属性(只能在RTL代码中使用),其优先级高于-flatten_hierarchy,在Verilog HDL中其综合属性的使用方法为:(* keep_hierarchy="yes" *) module_name(); 。使用了该属性的模块,可以在综合阶段保留层级结构,避免被优化。同时在对该模块添加综合属性时也要注意:
1)如果是在该模块设计文件中添加该属性,则所有例化该模块的地方都会保留其层级结构;
2)如果只是在例化时添加该属性,则只有该例化模块保留层级结构,其他例化的地方层级结构仍被打平。
1.2、-gated_clock_conversion

该设置用于管理门控时钟(Gated Clock)。所谓门控时钟是指由门电路而非专用时钟模块(如MMCM或PLL)生成的时钟。门控时钟会给设计带来一些负面影响,典型的危害包括:
(1)时钟信号可能会有毛刺;
(2)时钟歪斜(clock skew)的情况会继续恶化。
除此之外,vivado不会主动对门控时钟插入BUFG,这就意味着该时钟会占用传统的布线资源,也就是Fabric中的布线资源,而不会使用时钟网络资源,从而可能会跟其他关键路径争夺布线资源,并影响时序。所以,一般不建议工程中使用门控时钟,如果时钟的负载少且时钟频率较低(如小于5MHz)时,可以适当使用门控时钟,并且建议手工插入BUFG。-gated_clock_conversion可将门控时钟信号变为使能信号,从而消除门控时钟给设计带来的负面影响。
1.3、-fanout_limit

该综合设置用于设定信号所能承载的最大负载,也就是最高的扇出个数,默认值是10000。不过,该选项对设计中的控制信号,如置位、复位和使能信号是无效的。-fanout_limit只是为vivado提供了一个宏观的指导原则,而非强制命令,所以有时修改该设置值也不起作用。相比之下,综合属性max_fanout就严格很多。因此,如果很明确地需要对某个信号降低扇出,应使用max_fanout综合属性(* max_fanout=<number> *),而不是-fanout_limit综合设置。
1.4、-fsm_extraction
-fsm_extraction用于设定状态机的编码方式,默认值为auto,此时Vivado会自行决定最佳的编码方式。可选值如下:
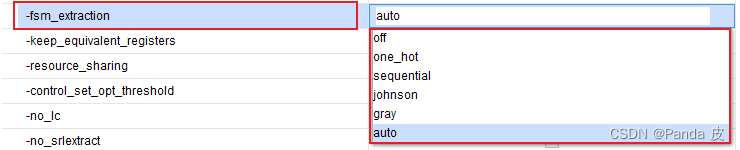
工程综合之后,在log窗口中搜索encoding或者Synth 8-3354,就可找到工程中所有状态机的编码方式, -fsm_extraction设置为默认值auto时状态机的编码方式如下图所示:
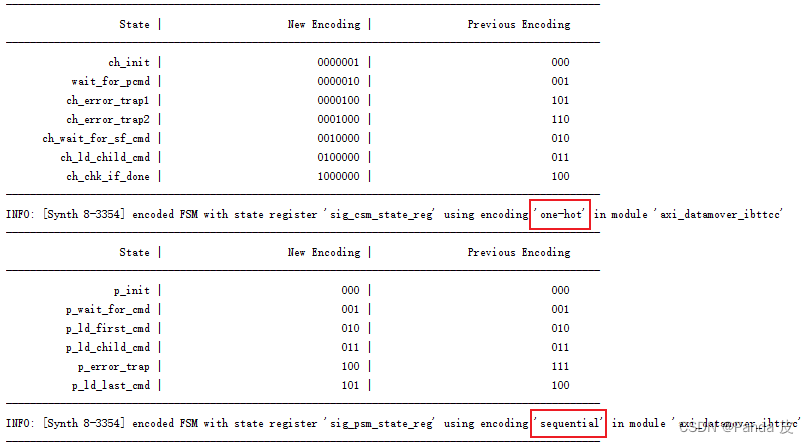
Previous Encoding表示的是该状态机模块已经设定的编码方式,New Encoding是Vivado进行优化之后的编码方式。当 -fsm_extraction设置为one_hot时,相关状态机的编码方式为:
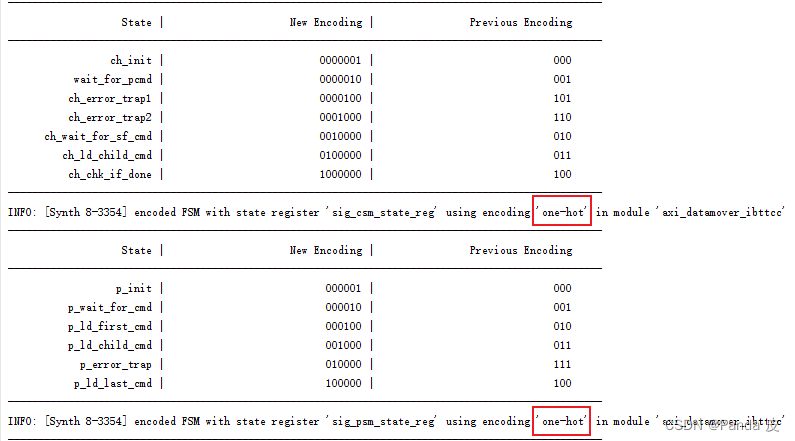
可见, -fsm_extraction设定的编码方式高于HDL代码内部定义的编码方式。与 -fsm_extraction具有同样功能的综合属性是fsm_encoding,它可以在HDL代码中针对某个状态机设定编码方式(例如Verilog的(* fsm_encoding = "one_hot" *)),其优先级高于 -fsm_extraction,但是如果代码本身已经定义了编码方式,如下图所示:

那么fsm_encoding设定的编码方式将无效(如果不想某个状态机被vivado优化成其他的编码方式,可以使用该综合属性,不过实际用的比较少。当然如果省事,可以直接用该属性定义状态机编码方式,不用再用RTL代码定义了,也能避免被优化成其他编码方式。不过也要根据设计定义合理的编码方式,不然也会造成一些时序问题)。
通常情况下,fsm_extraction设定为auto即可满足设计需求。如果工程中使用了fsm_encoding属性,可以在综合报告中搜索Synth 8-5534查看相应的属性配置。
1.5、-keep_equivalent_registers

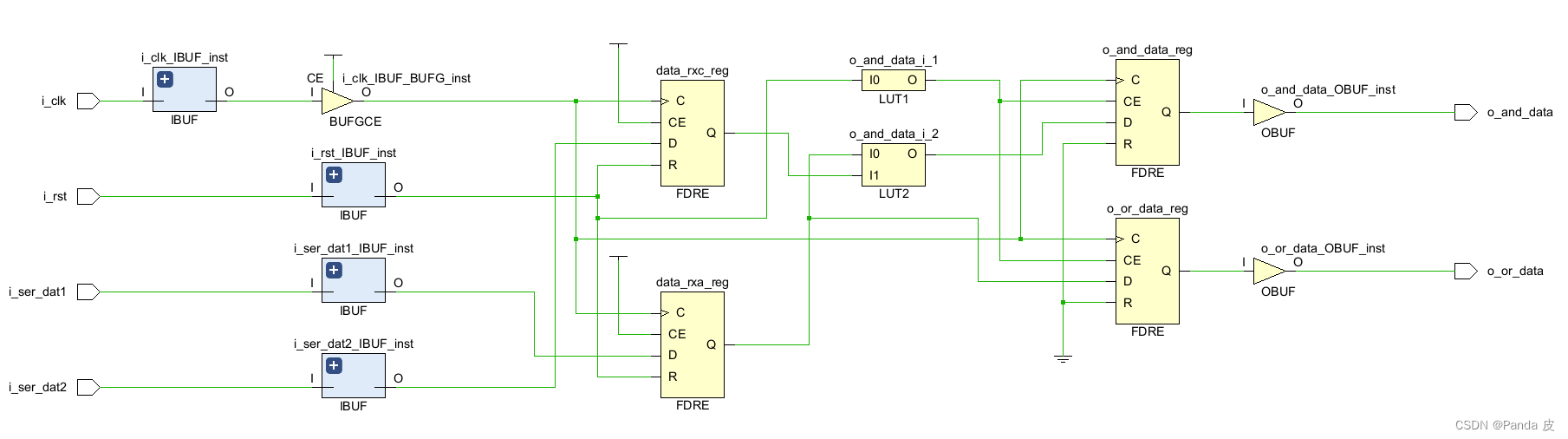
所谓等效寄存器(equivalent registers)是指具有同源的寄存器,即共享输入端口(时钟端口和数据端口)的寄存器。等效寄存器可能是设计者无意引入的,也可能是有意而为之。对于无意引入的寄存器,Vivado在综合阶段可以将其优化,从而避免额外的触发器开销。例如下面代码中的data_rxa和data_rxb:
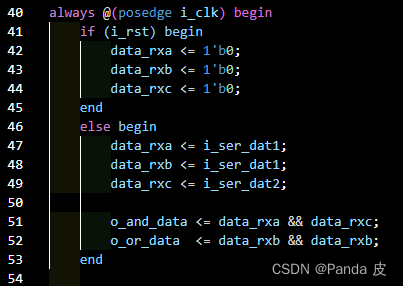
没有勾选-keep_equivalent_registers时:等效寄存器data_rxa和data_rxb被合并为一个:
勾选了-keep_equivalent_registers时:等效寄存器data_rxa和data_rxb没有被合并:
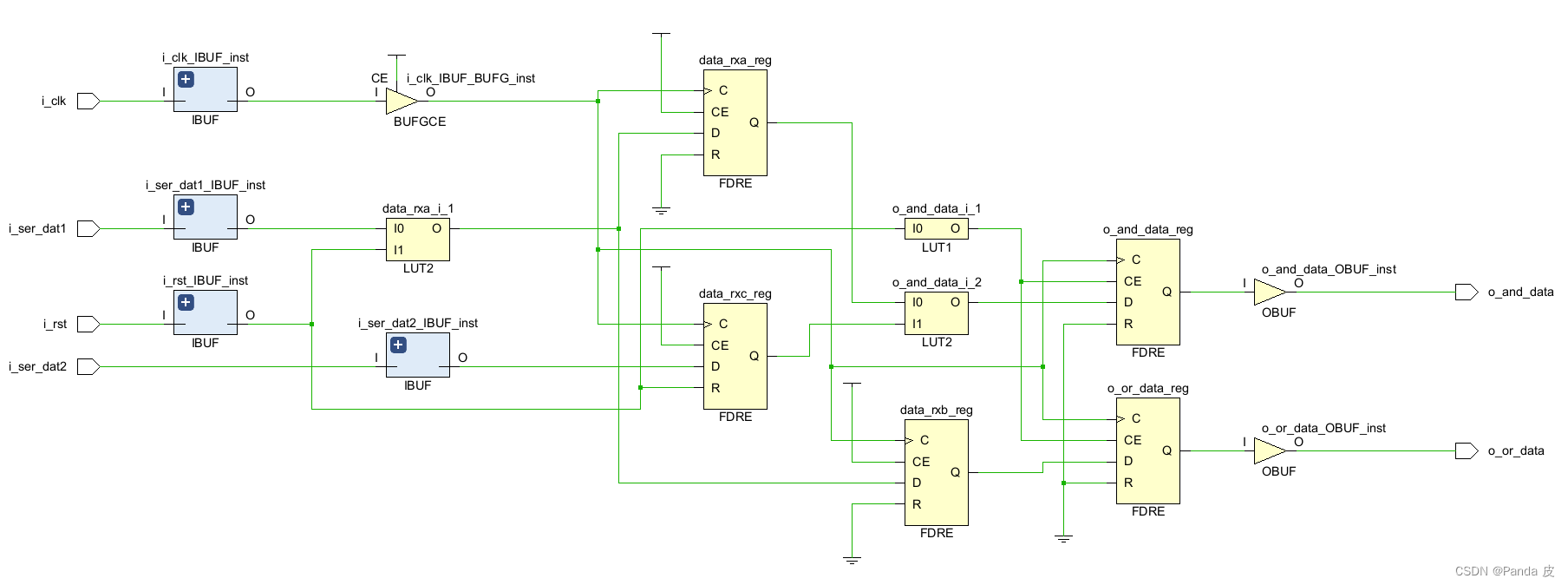
对于等效寄存器,一般只是工程的一小部分,一般不建议勾选-keep_equivalent_registers,因为这样会造成Vivado无法对其它无意引入的等效寄存器进行优化,不利于整体工程。所以对于特意引入的等效寄存器避免被优化较好的解决办法是利用综合属性keep进行保留,例如上面的等效寄存器可以如下添加综合属性:

工程中特意引入的等效寄存器,一般是为了降低关键路径上的扇出、优化时序,尤其是对于全局复位或全局使能信号而言,是一种行之有效的方式。
1.6、resource_sharing

该综合设置的目的是对算术运算通过资源共享优化设计资源,默认值为auto,此时会根据设计时序的需求确定是否资源共享。需要注意的是,它只对算术运算,即加法(减法也可认为是加法运算)和乘法运算有效。一般保持默认值即可。
1.7、-control_set_opt_threshold
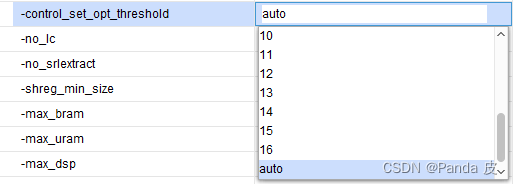
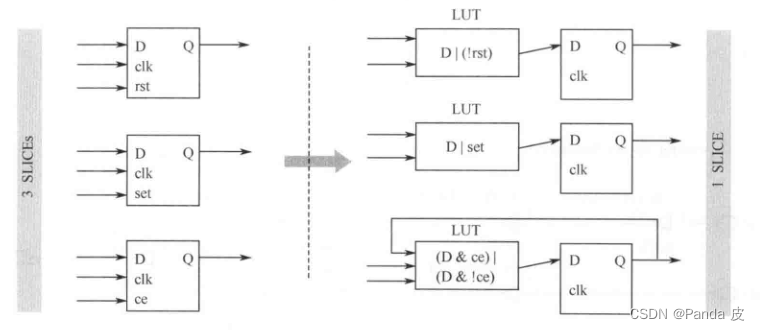
触发器的控制集是由时钟信号、复位/置位信号、使能信号构成。在通常情况下,只有{clk、rst/set、ce}均相同的触发器才可以被放置在同一个slice中。但是,对于同步复位、同步置位、同步使能信号,vivado会根据-control_set_opt_threshold的设置进行优化,其目的是减少控制集的个数。优化的方法如下图所示:
关于优化有一个更具体的例子是:
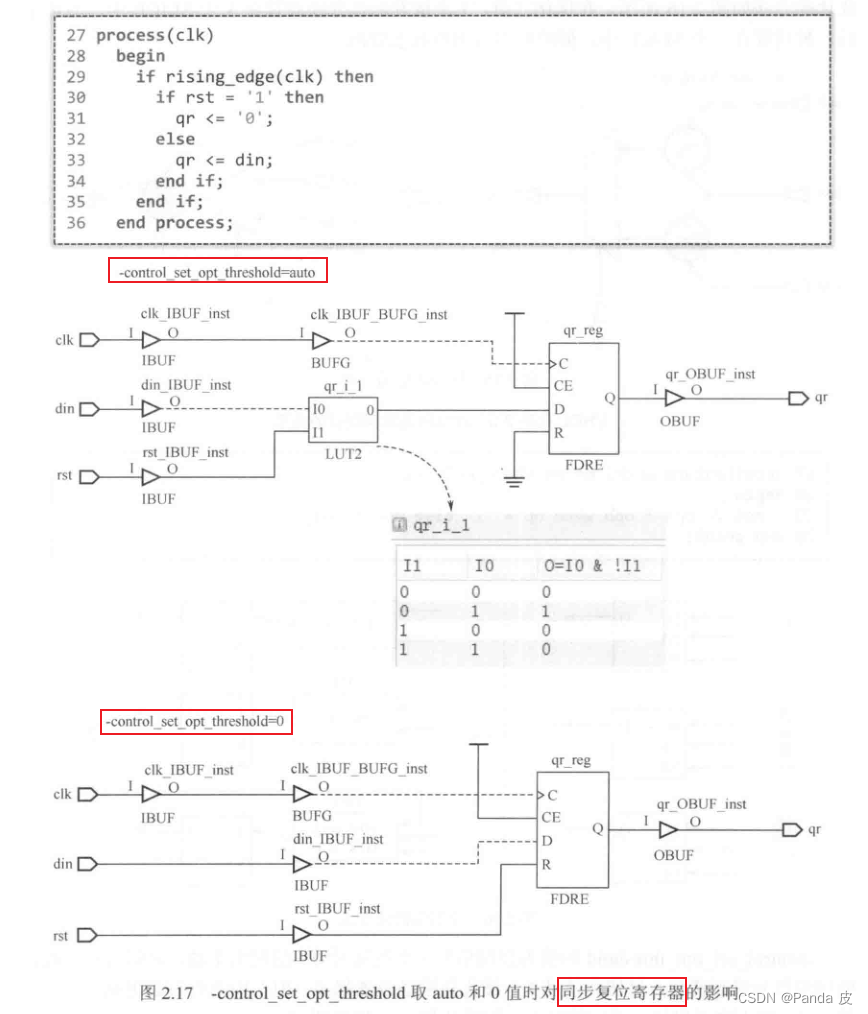
通过图片可知,通过优化,可以将原先分布在不同slice中的同步寄存器放置在同一个slice中,但是需要占用额外的查找表资源。-control_set_opt_threshold的值为控制信号(不包括时钟)的扇出个数,表明对小于此值的同步信号进行优化。此值越大,被优化的触发器越多,被占用的LUT也越多。若此值为0,则不进行优化。在通常情况下,按照默认值auto运行即可。不过在设计初期就应尽可能的减少控制集,否则可能会出现触发器消耗不多但SLICE的占用率却很高的情形。
对控制集百分比的说明(使用于7系列FPGA和UltraScale FPGA)如下表所示:
| 说明 | 控制集百分比 |
|---|---|
| 可接受 | 当前设计的控制集小于整个芯片控制集的7.5% |
| 建议降低 | 当前设计的控制集占整个芯片控制集的7.5%~15% |
| 必须降低 | 当前设计的控制集大于整个芯片控制集的15% |
由表格可知,当控制集的百分比超过15%时,需要降低控制集。
计算控制集百分比的步骤如下:
(1)打开综合阶段或实现阶段生成的DCP(Open Synthesized/Implemented Design),Tcl Console 中输入report_control_sets -verbose命令获取unique_ctrl_set,即unique control sets值,如下图所示:

(2)通过两条命令获得当前芯片中SLICE的个数slice_num:(这两条命令要一起输入,单独输入会报错)
set part [get_property PART [current_design]]
set slice_num [get_property SLICES [get_parts $part]]
获取结果如下图所示:
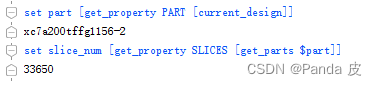
(3)计算控制集百分比,即unique_ctrl_set/slice_num*100%
工程控制集百分比 = 2364/33650*100% = 7.025% => 说明这个工程的控制集数量还是可以接受的
此外, CONTROL_SET_THRESHOLD(可选值为0~128)也是综合设置中的一个选项。利用该选项可以根据设计需求灵活地对某些模块的控制集进行控制。例如:
set_property BLOCK_SYNTH.CONTROL_SET_THRESHOLD {8} [get_cells uart_rx]
set_property BLOCK_SYNTH.CONTROL_SET_THRESHOLD {16} [get_cells uart_tx]
可将上述两条语句写入一个单独的XDC文件中,并将文件设置为综合阶段使用。
1.8、-no_lc

LUT6的内部结构如下图所示:
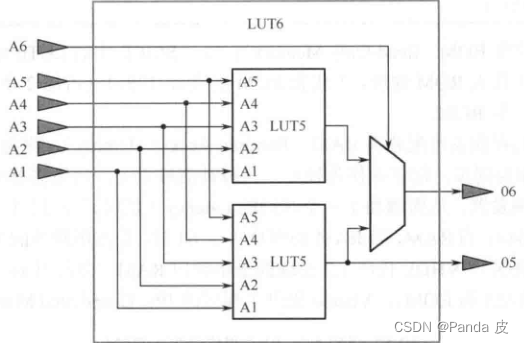
正是由于LUT6的这种结构,决定了对于一个x输入布尔表达式和一个y输入布尔表达式,只要满足x+y≤5(相同变量只算一次),这两个布尔表达式就可以放置在一个LUT6中实现,此时A6=1,运算结果分别由06和05输出。默认情况下,当存在共享变量时,vivado会自动把这两个布尔表达式放在一个LUT6中实现,称为LUT整合(LUT Combining);否则,仍占用两个LUT6分别实现每个布尔表达式。但是,当-no_lc(No LUT Combining)被勾选时,则不允许出现LUT整合。
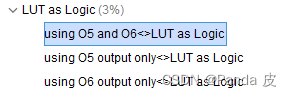
通过LUT整合可以降低LUT的资源消耗率,但是也可能导致布线拥塞。因此,xilinx建议,当整合的LUT超过了LUT总量的15%时,应考虑勾选-no_lc,关掉LUT整合。在实现后的资源利用率报告中可以查看整合的LUT个数,如下图所示:using 05 and 06的个数就是整合的LUT6的个数
此外,vivado模块化综合技术提供了一个类似选项LUT_COMBINING,可以灵活地对某些模块进行LUT整合或者不进行LUT整合。其值是0或1(1表示进行LUT整合)。一个可能的判断依据是设计的布线拥塞报告。
1.9、-no_srlextract

该综合设置用于阻止工具将移位寄存器映射为LUT,其优先级高于-shreg_min_size。例如:当移位寄存器的深度为4、-shreg_min_size为3、-no_srlextract被勾选时,最终的实现方式是4个触发器级联的形式,而不是FF+LUT+FF的形式。
1.10、-shreg_min_size

该综合设置用于管理移位寄存器是否映射为LUT(SRL),默认值为3。当移位寄存器的深度小于-shreg_min_size时,最终的实现方式为触发器级联的形式,即FF+FF或FF+FF+FF;当其深度大于等于-shreg_min_size时,实现方式则为FF+LUT+FF的形式。移位寄存器采用LUT+FF或者FF+LUT+FF形式的好处在于节省了FF(尤其对于较大深度的延迟);因为SLICE中的FF,其Tco(时钟到输出延迟)小于LUT的Tco,所以对时序收敛也是有好处的。
对于移位寄存器的实现方式,可通过-shreg_min_size进行全局管理,也可通过模块化综合技术中的选项shreg_min_size进行细粒度管理,还可通过综合属性srl_style进行控制。采用LUT实现的移位寄存器不支持复位。
二、综合属性
2.1、ASYNC_REG
在异步跨时钟域场合,对于控制信号(通常位宽为1bit)常使用双触发器(或多触发器)的方式完成跨时钟域操作,也就是我们常说的“打两拍”,使用这种方法时,最好给进行同步的两个(或多个)触发器添加ASYNC_REG属性(* ASYNC_REG="true" *)。如下图所示:给①号和②号寄存器添加该综合属性
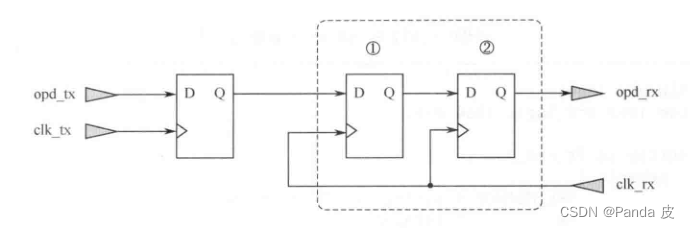
添加ASYNC_REG综合属性有两个目的:
(1)表明①号触发器接收的数据是来自于与接收时钟异步的时钟域;
(2)表明②号触发器是同步链路上的触发器。
从而保证①②号触发器在布局时会被放置在同一个slice中,减少线延迟对时序的影响。在实际使用时,为了避免忘记给同步寄存器添加 ASYNC_REG综合属性,可以直接使用xilinx提供的XPM_CDC模板,如下图所示:
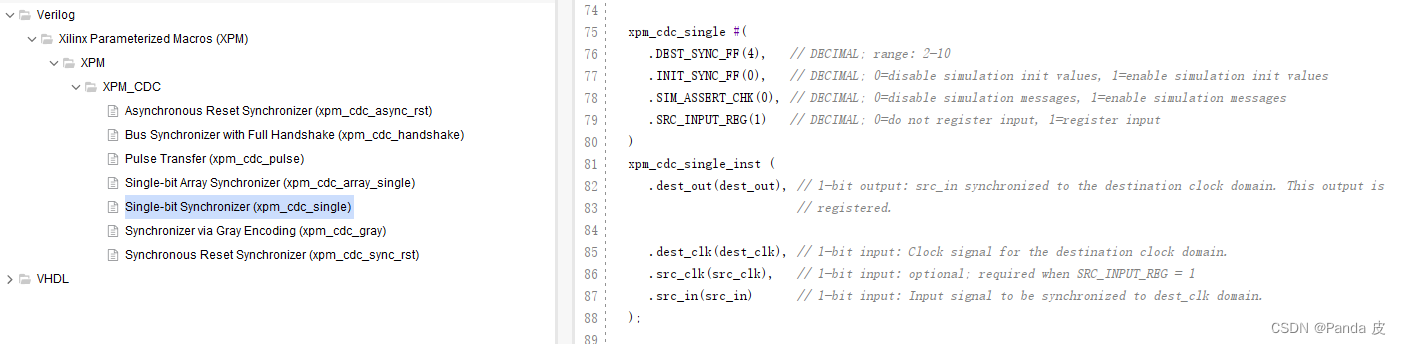
该模板实例化(DEST_SYNC_FF(2))综合结果如下图所示:
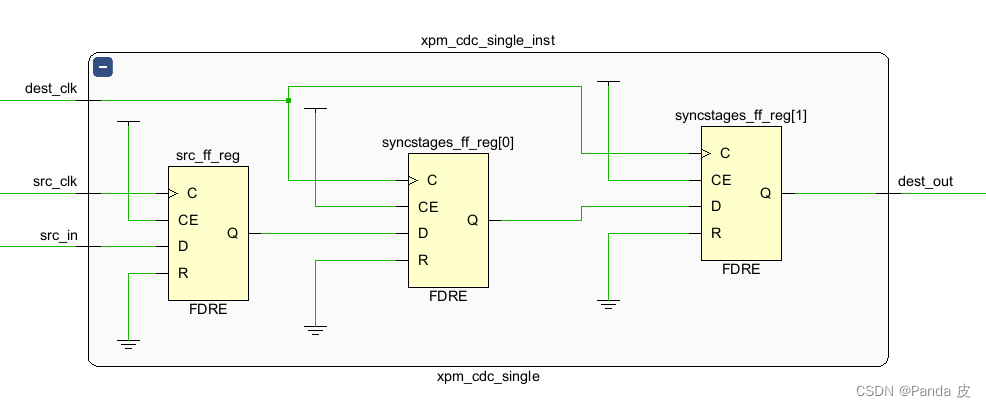
2.2、MAX_FANOUT
高扇出信号可能会因为布线拥塞而导致时序问题,常用的方法是通过寄存器复制以降低扇出。 有以下两种方式:
(1)手工采用HDL代码复制寄存器,但此时要注意确保综合时复制的等效寄存器不会被优化掉;==> 可以用 (* keep="true" *) 综合属性进行保持,避免被优化
(2)通过综合属性MAX_FANOUT实现寄存器复制。
综合属性MAX_FANOUT即可用于RTL代码中,也可用于XDC中,xilinx提供的模板如下所示:
(1)(* max_fanout=<number> *) => 用于RTL代码中
(2)set_property max_fanout <number> [get_nets <net_name>] => 用于XDC中
相对于全局设置-fanout_limit,综合属性MAX_FANOUT的优先级要高一点。使用max_fanout时,不用勾选综合设置中的-keep_equivalent_registers,因为本身MAX_FANOUT的目的就是复制寄存器,而且被复制的等效寄存器在后续实现时也不会被优化掉。不过在使用MAX_FANOUT综合属性时可能会出现MAX_FANOUT不生效的情况,造成这种情况的原因之一是其作用对象与负载不在同一层次。
例如,下图左边所示,触发器位于inst_0模块中,inst_0与inst_1位于同一层次,但负载位于inst_1下的三个模块inst_10、inst_11、inst_12中,这个时候对触发器使用MAX_FANOUT综合属性可能会不生效。
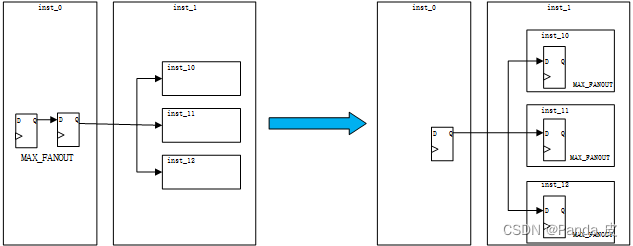
对于这种情况,一个可行的解决办法是将触发器搬移到相应的层次之后,再使用MAX_FANOUT综合属性,如上图右边所示。
此外,这里还要提一下-flatten_hierarchy对综合属性MAX_FANOUT的影响,如下表所示:
| 情形 | -flatten_hierarchy | 是否生效 |
|---|---|---|
| max_fanout的作用对象与负载位于同一层次 | full、none、rebuilt | 是 |
| max_fanout的作用对象与负载不位于同一层次 | full、rebuilt | 是 |
| none | 否 |
同时,MAX_FANOUT可作用于Xilinx IP内部信号,但未必生效。因为IP本身会有一些保护属性,使得层次保留、触发器与负载不在同一层次,那么可以使用如下的方法优化高扇出信号:
phys_opt_design -force_replication_on_nets [get_nets net_name]另外,当MAX_FANOUT作用于bus中的某一位时,会造成其他位对应的寄存器也被复制的情况,
2.3、SRL_STYLE
SRL_STYLE用于指导Vivado将SRL(移位寄存器)映射为何种形式,该属性共有6个可选值,以一个深度为4的移位寄存器为例,不同属性值对应的综合结果如下所示:
module shift_registers #(
parameter DEPTH = 4
)
(
input clk ,
input en ,
input din ,
output dout
);
(* SRL_STYLE = "register" *)reg [DEPTH-1:0] shreg;
always @(posedge clk)
begin
if(en == 1)
shreg <= {shreg[DEPTH-2:0], din};
end
assign dout = shreg[DEPTH-1];
endmodule1) SRL_STYLE = register
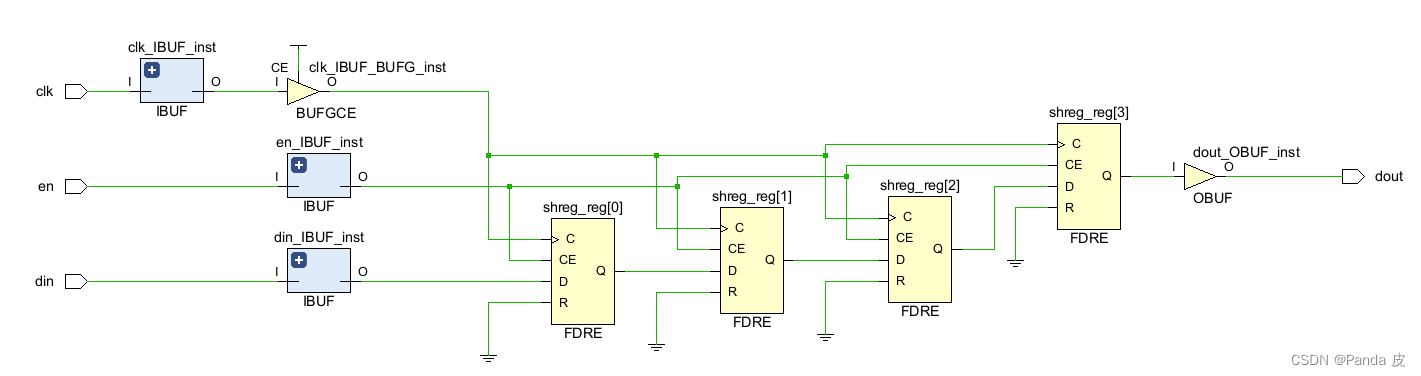
2) SRL_STYLE = srl
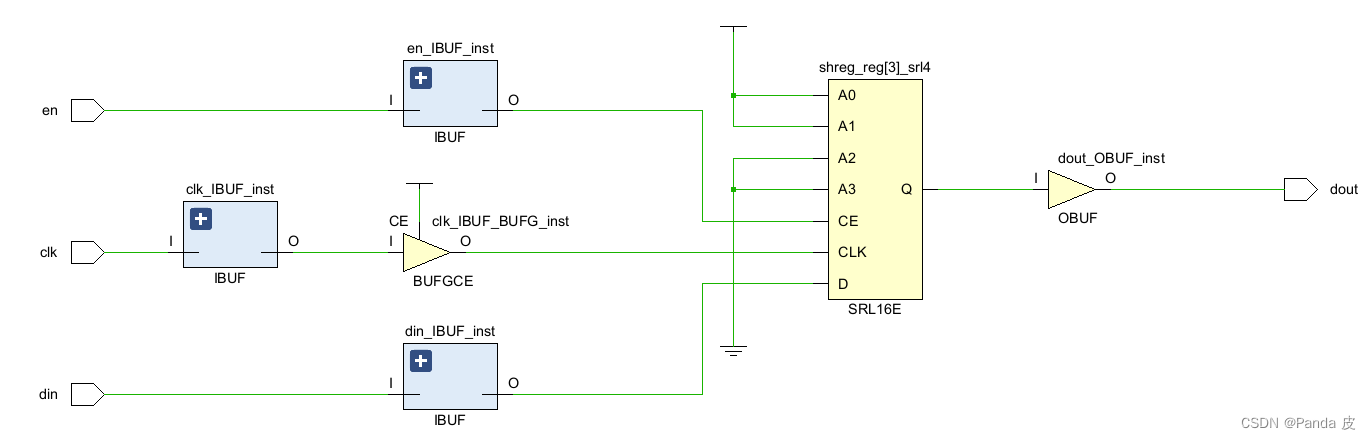
3) SRL_STYLE = srl_reg
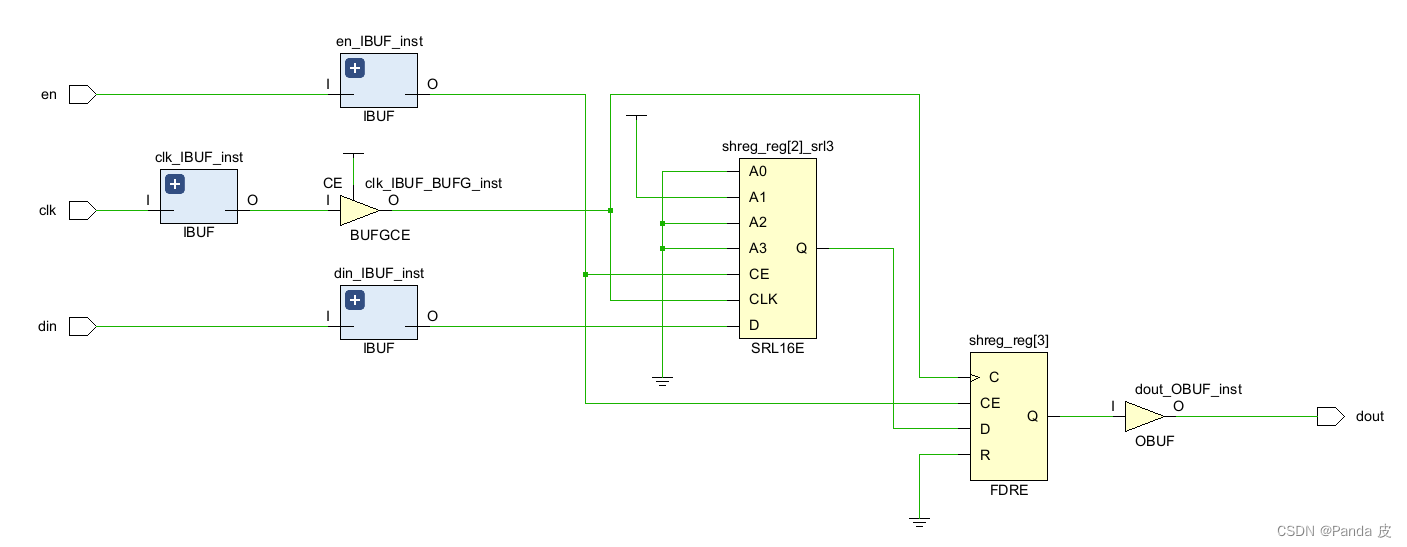
4) SRL_STYLE = reg_srl
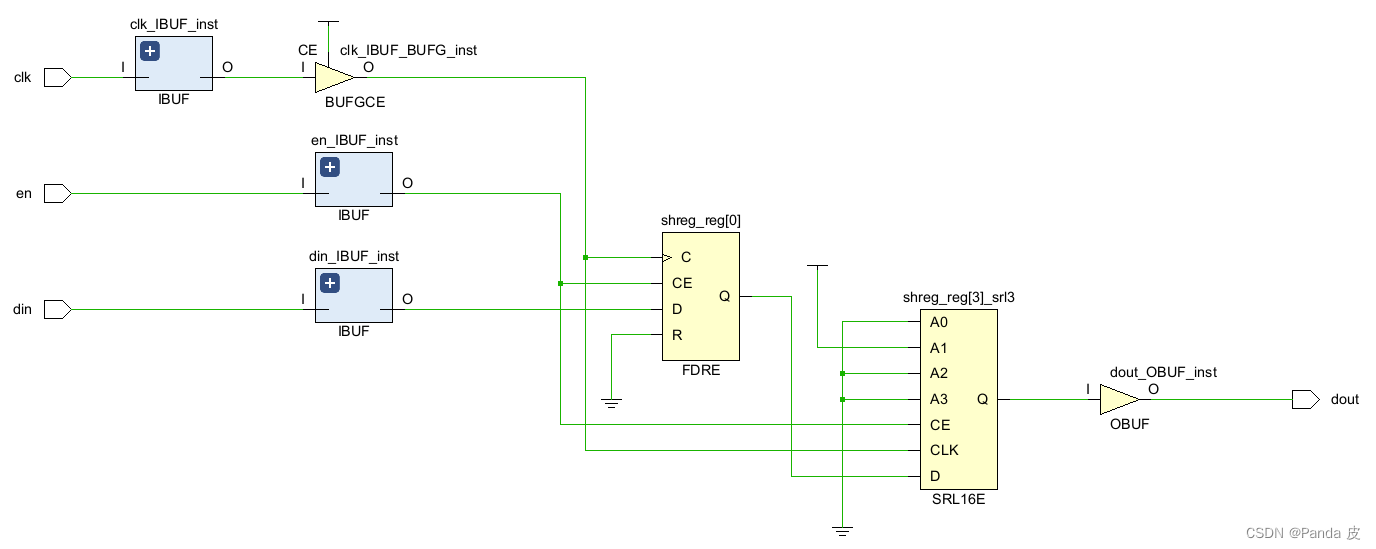
5) SRL_STYLE = reg_srl_reg
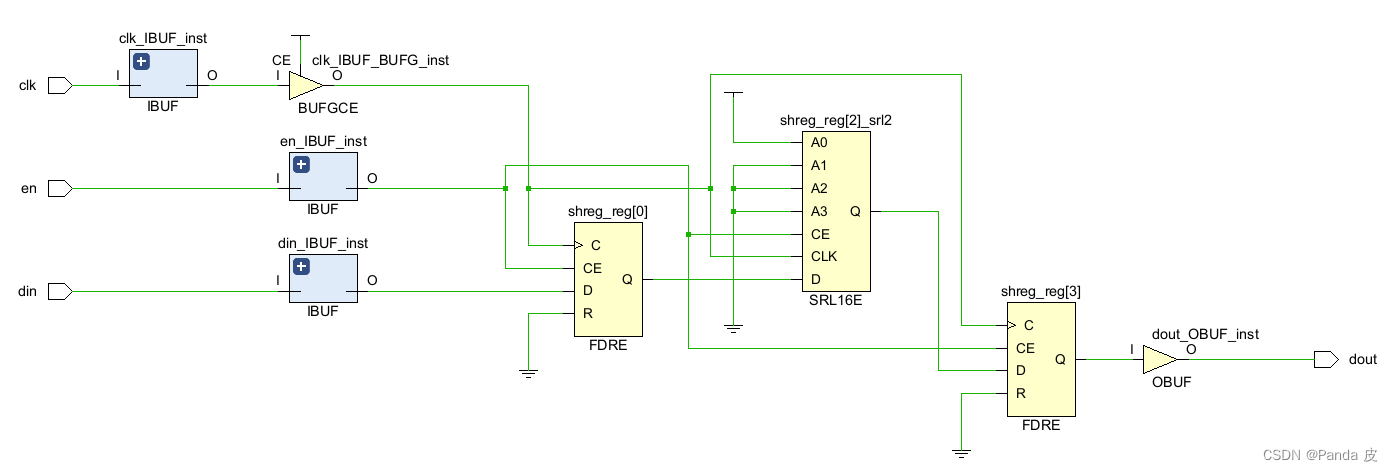
6) SRL_STYLE = block
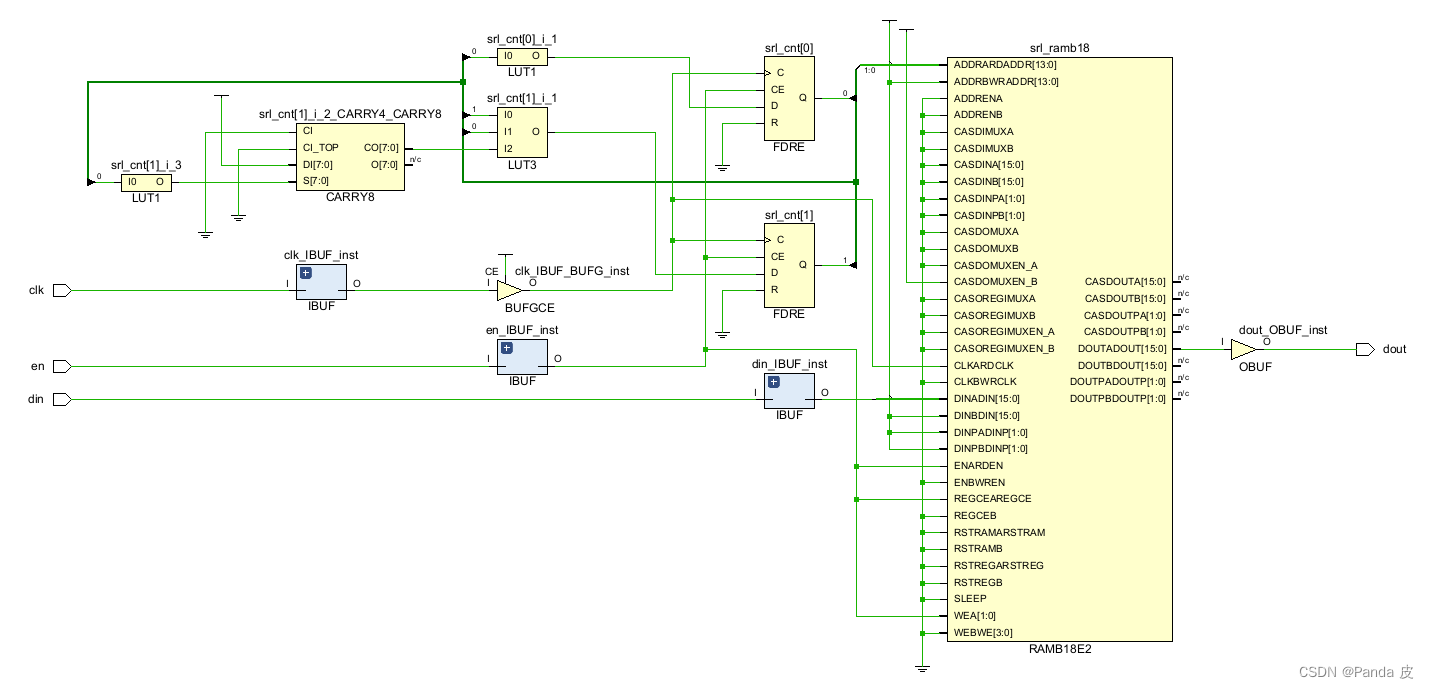
Notes:
① 从时序角度而言,不建议时序路径的终点是移位寄存器,所以对于“FF + 组合逻辑 + SRL”的路径可以优化为“FF + 组合逻辑 + FF”。
②对于较大深度的移位寄存器,可以将其映射为Block RAM,也就是SRL_STYLE的值为block,否则会消耗过多的LUT。
③对于深度较小的移位寄存器,如果在某个模块内的资源利用率较高的话,就有可能给时序收敛带来负面影响,此时可以考虑将深度较小的移位寄存器转化为FF。
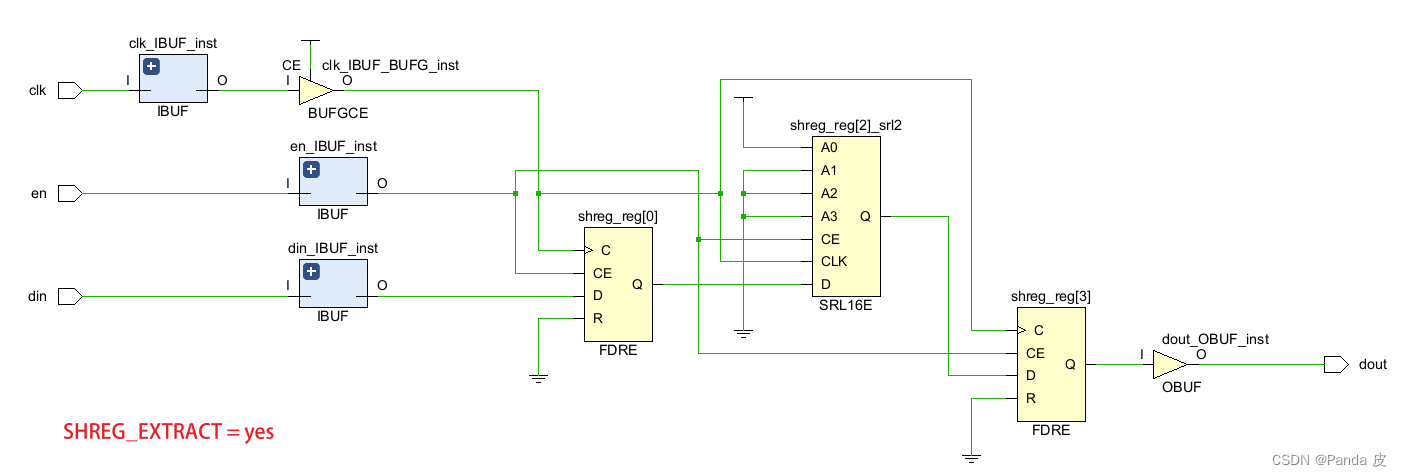
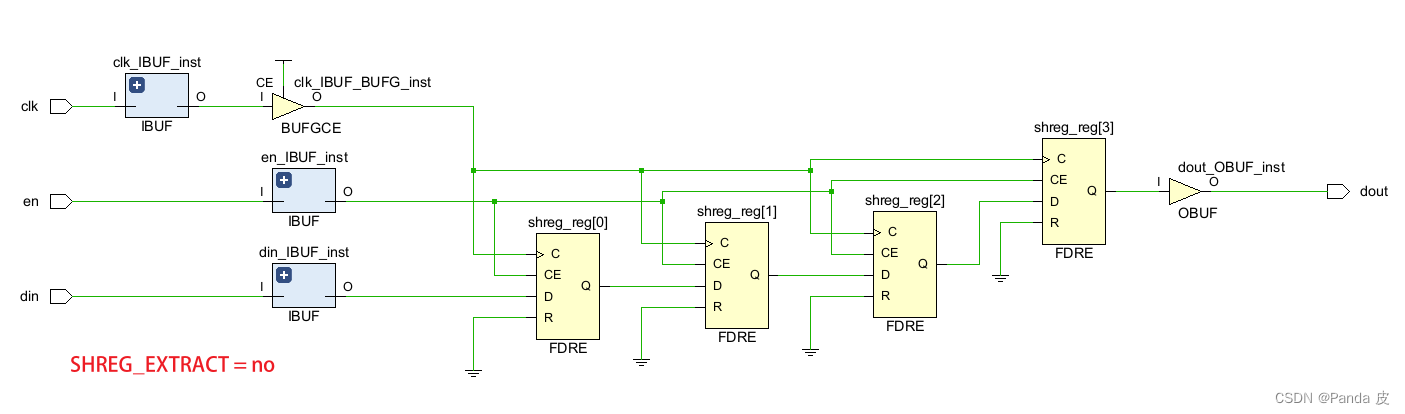
2.4、SHREG_EXTRACT
该综合属性和SRL_STYLE属性类似,不过优先级比SRL_STYLE高,它有两个值,yes和no。当其为yes时,等效于SRL_STYLE = reg_srl_reg;当其为no时,等效于SRL_STYLE = register。
2.5、USE_DSP
在默认情况下,用HDL描述的乘法、乘加、乘减、乘累加,以及预加相乘运算,最终都会映射到DSP48中,但是加法、减法和累加运算则会用常规的逻辑资源,即查找表(LUT)、进位链等实现。相比与LUT,DSP48在功耗和速度上都有优势。如果希望加法运算也能映射到DSP48中,那么就要用到综合属性USE_DSP(取代了之前的USE_DSP48)。
该综合属性有4个值,分别是
① simd(Signal Instruction Multiple Data):将单指令多数据流功能映射到DSP48E单元,使得一个48bit的ALU可配置为多个较窄的ALU,例如4个12bit或者2个24bit的ALU。
② logic:使用DSP48E资源的异或结构来实现特定的逻辑运算。该值只能放置在模块级别上。
③ yes:强制将指定的加法、减法等逻辑单元映射到DSP48E单元找中。可以设置在信号或者模块上,信号的优先级高于模块。
④ no:指定不将逻辑单元映射到DSP48E资源中,而是使用常规的逻辑资源(如LUT)。
具体用法:
(1)module级应用:在模块声明前使用(* USE_DSP="yes" *),会影响整个模块内所有的算术运算使用DSP资源。
(2)signal级应用:在使用信号声明前使用(* USE_DSP="yes" *),只有该信号参与的运算会被映射到DSP资源。
(3)simd特性利用:当使用simd时,应遵守特定的代码风格,可以有效节省LUT和FF资源,同时提升时钟频率。例如当存在大量并行的简单运算时,使用simd特性可以提高资源利用效率和运算速度。
2.6、RAM_STYLE & ROM_STYLE
属性RAM_STYLE用于指导综合工具推断出RAM的实现方式,该属性有4个可选值:block(将RAM映射为Block RAM)、distributed(将RAM映射为分布式资源)、registers(将RAM映射为寄存器)、ultra(针对UltraScale Plus芯片,将RAM映射为UltraRAM)。
属性ROM_STYLE用于引导综合工具将ROM采用不同的资源实现,该属性有两个可选值:block(将ROM映射为Block RAM)、distributed(将ROM映射为分布式资源)。对于UltraRAM,不能用作ROM,同时不建议采用手工编写HDL代码,最好使用XPM_MEMORY。
2.7、EXTRACT_ENABLE & EXTRACT_RESET
属性EXTRACT_ENABLE可控制寄存器是否使用使能信号,当其为yes时,使能端口被使用;当其为no时,使能端口将恒高。该属性的作用对象是目标寄存器,而不是连接到寄存器使能端口的网线。
通常情况下,连接到触发器数据端口(D端口)的延迟小于CE、R、S端口的延迟,这是因为在同一个Slice内,紧邻触发器的LUT可直接连接该触发器的D端口。从时序收敛的角度而言,这是有好处的,因为可以把关键路径移至数据端口。这样做的前提是没有额外的损失。
属性EXTRACT_RESET用于控制寄存器是否使用复位信号,不过需要注意的是,这里的复位信号必须是同步复位。
2.8、MARK_DEBUG
PASS
持续更新中~
~ END ~


















 2042
2042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











