







1、视图
1.1 概念
视图是一个虚拟的表,是一个表中的数据经过某种筛选后的显示方式,视图由一个预定义的查询select语句组成。
1.2 特点
- 视图中的数据并不属于视图本身,而是属于基本的表,对视图可以像表一样进行增删改查操作。
- 视图不能被修改,表修改或者删除后应该删除视图再重建。
- 视图的数量没有限制,但是命名不能和视图以及表重复,具有唯一性。
- 视图可以嵌套,一个视图中可以嵌套另一个视图。
- 视图不能索引,不能有相关联的触发器和默认值。
1.3 语法
-
创建视图:
create view 视图名称[(字段1)(字段2)(字段3)...] as select 查询语句 [with check option]参数:[with check option]可选项,防止用户对数据插入、删除、更新是操作了视图范围外的基本表的数据。
-
删除视图
drop view 视图名称 [cascade]
2、函数
SQL拥有很多可用于计数和计算的内建函数。
语法:select function(列) from 表;
类型:
- 合计函数(Aggregate):面向一系列的值,并返回一个单一的值
count(column):返回某列的行数,不包括null值count(*):返回被选行数
- Scalar函数:面向某个单一的值,并返回基于输入值的单一的值
ucase(c):将某个域转换为大写lcase(c):将某个域转换为小写len(c):返回某个文本域的长度
3、find_in_set函数
select * from 表名 where find_in_set(str,strlist);
-
str:要查询的字符串 -
strlist:参数以,分隔
返回str在strlist中的索引,从1开始,strlist必须以,分隔开。
SELECT FIND_IN_SET('b', 'a,b,c,d'); 返回2
select FIND_IN_SET('6', '1'); 返回0
一次返回多条记录:
select * from 表名 where find_in_set(id, '1,2,3,4');
id:字段名
like是广泛的模糊匹配,字符串中没有分隔符,Find_IN_SET 是精确匹配,字段值以英文,分隔,Find_IN_SET查询的结果要小于like查询的结果。
4、group_concat
完整语法:
group_concat([distinct] 要连接的字段 [order by asc/desc 排序字段] [separator '分隔符'])
select * from test;
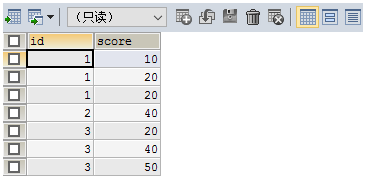
需求:一行显示id下所有的score
select id, group_concat(score) from test group by id;
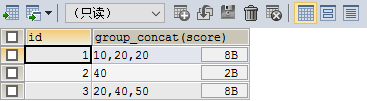
去重:
select id, group_concat(distinct score) from test group by id;
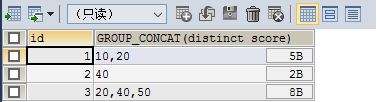
排序
select id, group_concat(score order by score desc) from tset group by id;
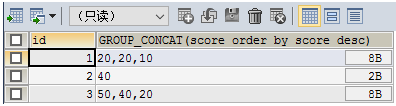
设置分隔符
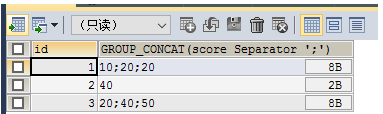
select id, group_concat(score separator ';') from test group by id;

















 7874
7874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









