







 本文分析了场景文本识别(STR)领域的数据集不一致性问题,导致模型性能无法公平比较。提出统一的4阶段STR架构,包括变形、特征提取、序列建模和预测阶段,并通过实验证明模块对准确率、速度和内存需求的贡献。强调未来STR研究应明确训练集,以促进公平的性能评估。
本文分析了场景文本识别(STR)领域的数据集不一致性问题,导致模型性能无法公平比较。提出统一的4阶段STR架构,包括变形、特征提取、序列建模和预测阶段,并通过实验证明模块对准确率、速度和内存需求的贡献。强调未来STR研究应明确训练集,以促进公平的性能评估。
场景文本识别:由于训练数据集和评估数据集的选择不一致,整体和公平的比较在该领域出现了很大的缺失。
三个贡献:(1)检查了不一致的训练和评估数据集,以及不一致导致的性能茶橘。(2)提出了一种统一的4阶段STR架构,大多数STR模型可以放入。使用这个框架可以对以前提出的模块进行扩展评估,也可以发现以前没有研究过的模块组合。(3)从准确率,速度和内存需求分析模块对性能的贡献,在一个一致的训练级和评测级上。这样的分析清除了当前比较的障碍,了解现有模块的性能。我们的代码是公开可用的。
介绍:先前的方法提出了多阶段的通道,每一个通道是一个深层神经网络
应对特定的挑战。例如RCNN处理不同数量的字符,CTC辨别字符的数量。transformation模块将输入标准化为直的文本以减少下游模块处理弯曲文本的负担。
然而,很难评估一个新提出的模块是否或怎样提升当前的性能,由于一些论文提出了不同的评估和测试环境,使得报告的数字难以比较。我们观察到1)训练集2)测试在不同的方法之间存在偏差。例如,不同的工作使用不同的IC13数据集的子集作为评估集合,可能造成超过15%的评估差异,妨碍了不同模型之间性能的公平比较。
我们的论文通过以下主要贡献来解决这些问题。首先,我们分析了所有的训练数据和验证数据集在这些STR论文中共同使用的。揭露了STD数据集使用的不一致性和原因。例如,我们发现了7个漏掉的例子在IC03数据集上和158个漏掉的样例在IC13数据集上。我们对STR数据集上的工作进行了研究,表明不一致造成了不可以比较的结果,在Table1中。第二,我们提出了一个统一的架构用于STR,为现有方法提供一个公共的视角。明确地,我们将STR模型分成四个不同的连续阶段包括:transformation(Trans.), feature extraction(Feats.), sequence modeling(Seq.), prediction(Pred.).这个架构不仅提供现有的方法,而且提供其可能的变体,并对模块间的贡献做一个广泛的分析。最后,我们研究了模块对准确率速度和内存需求的贡献,在一个统一的实验设置下。在这项研究中,我们更严格的评估独立模块的贡献并且提出了以前忽略的模块组合,提升了最佳性能。此外,我们分析了标准数据集的错误样例以指出STR任务中现存的挑战。
STR任务中的数据集问题
检查了先前任务使用的不同的训练和评估数据集,解决了他们之间的差异。强调了每个工作在构建和使用数据集上的差异,并调查了比较性能时不一致所造成的偏差。
合成数据集:
MJSynth(MJ):8.9M word box images
SynthText(ST):通过裁剪文字框来用于STR,会裁剪过滤掉非字母和数字的字符。4.2描述了训练集对最终表现的影响。建议未来的STR研究明确表明训练集,并使用相同的训练集。
真实数据集:
ICDAR03 860 867。
ICDAR13 857相比于1015,长度小于3的字符被删除。
ICDAR15 使用1811代替2077张,丢弃非字母数字字符图像和一些极度旋转、透视移位和弯曲的图像。
造成评估差距,03上有0.8%,13 15上差距更大。
STR架构分析
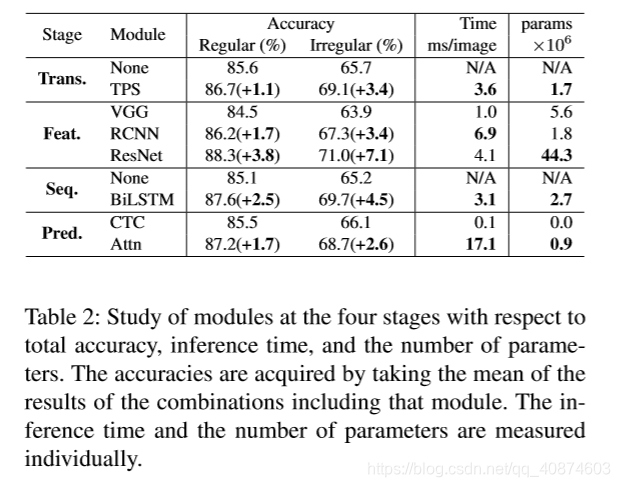
4个模块,对每个模块的选项进行了描述。
由于STR任务与计算机视觉任务(如目标检测)和序列预测任务的相似性,STR受益于CNNs和RNNs的高性能。第一次将CNN和RNN结合用于STR的叫做Convolutional-Recurrent Neural Network(CRNN),从输入图像中提取CNN特征,并使用RNN对其重构用于健壮的序列检测。CRNN之后,多种变种用于提升性能。对于任意形状的文本几何图形,transformation模块提出用于标准化文本实例。为了处理具有高的内在维度和潜在因子的复杂文本图片,改进的CNN特征提取器被使用。另外随着推理时间的考量,有的方法省略了RNN阶段。为了提升字符序列检测能力,基于注意力机制的解码器被提出。
采自现存STR模型的4个模块如下:
1.Transformation(Trans.)使用空间变换网络标准化文本图片以减轻后续阶段负担。
2.Feature extraction(Feat.)将输入图像映射到一个可以关注于字符识别相关属性的表示,同时抑制不相关的特性如字体颜色大小背景。
3.Sequence modeling(Seq.)捕获一个字符序列内的上下文信息用于下一阶段更健壮的预测每一个字符,而非独立地预测他们。
4.Prediction(Pred.)根据已识别的图像特征估计输出的字符序列。
提供图3作为概述,本文中使用的所有架构可以在补充材料中找到。
Transformation stage
将输入图片X转换为规范化的图片X’ ,自然场景中的文本图像有不同的形状,比如弯曲和倾斜的文本。如果这样的输入图像不被改变,接下来的特征提取阶段需要学习关于这样的几何形状的不变性表示。为了减轻这种负担。thin-plate spline(TPS)transformation,薄板样条变换,一种空间变换网络(STN)的变体,因为其应对不同长宽比文本行的灵活性被应用。TPS在一组基准点中使用平滑的样条插值。更确切地说,TPS在上下边界点上找到多个基准点,将文字区域规范化为一个预定义的矩形,我们的框架允许使用或不使用TPS。
Feature extraction stage
在这个阶段,一个CNN提取一个输入图像并输出一个视觉特征图。研究
了VGG,RCNN,ResNet三种架构。
Sequence modeling stage
从Feat.阶段提取的特征被改造成序列信息,特征图的每一列作为序列架构。这个序列可能会缺少上下文信息。先前的方法使用BiLSTM来获得更好的序列H。另一方面,Rosetta删除了BiLSTM以减少计算复杂度和内存消耗。我们的框架允许使用或不使BiLSTM
Prediction stage
在这一阶段,从输入H中,一个模块预测一个字符序列。通过总结先前的方法,我们对于预测有两种选择:(1)CTC(2)attention-based。CTC允许预测不固定数量的特征即使给予固定数量的特征,CTC方法的关键是在每一列预测一个字符,通过删除重复字符和空格来将整个字符序列改善为不定长的字符流。另一方面,基于attention的方法自动捕获输入序列的信息流来预测输出序列。它使得STR模型可以学的一个字符级的语言模型以表示输出类的依赖关系。
实验研究和分析
这个模块包括对所有可能的STR模型组合的评估和分析(2 x 3 x 2 x 2=24),所有的评估在2阶段列举的训练与评估数据集下进行。
4.1实现细节
4.2数据集分析
4.3模型组合的取舍分析:关注准确率-速度和准确率-内存的平衡。就准确率和时间的权衡上,Rosetta和STAR-net还在前列。它们依次增加了整个模型的复杂性,以提高计算效率为代价提高了性能。
另一方面,最后的改变Attn只提高了1.1%的准确率,但却耗费了巨大的效率(27.6 ms)。
Attention时间花费大 resnet内存花费大。
故障案例:1)书法字体2)垂直文本3)特殊字符4)重大遮挡5)低分辨率6)标签噪声
STR Framework 架构细节:
D1 Transformation stage:
TPS transformation:TPS生成一个标准化的图片,包括以下序列过程:找到一个文本边界,将像素位置连接到标准化的图片位置。利用像素值和连接信息生成标准化的图片。可以叫做定位网络,网格生成器和图像采样器。概念上讲TPS使用一个smooth spline interplation光滑样条插值在一系列表示文本注意边界的基准点上。F表示基准点的数量。定位网络明确计算图像上F个基准点的坐标。表示预定义的上下基准点。
网格生成器提供一个映射函数从定位网络定位的区域到标准化的图片。
最后图像采样器通过插值输入图像的像素(由网格生成器)产生标准化的图片。
TPS实现:需要定位了网络计算输入图像的基准点。我们依照先前的工作设计了定位网络,并且增加了BN层和自适应平均pooling层来稳定网络的训练。
D4 prediction:
(1)Connectionist Temporal Classification(ctc)
(2) Attention mechanism(Attn)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









