







 本文详细介绍了Flink的四种部署方式:Local、Standalone、Standalone-HA高可用和Yarn部署。针对不同场景,如开发、测试和生产环境,提供了详细的配置和操作步骤,包括配置文件修改、集群启动、任务提交等。
本文详细介绍了Flink的四种部署方式:Local、Standalone、Standalone-HA高可用和Yarn部署。针对不同场景,如开发、测试和生产环境,提供了详细的配置和操作步骤,包括配置文件修改、集群启动、任务提交等。
部署方式分类
1.Local 本地部署
2. Standalone 使用Flink自带的资源调度平台进行任务的部署
3. Standalone-HA高可用的部署方式
4. Yarn 部署
1. Local 本地部署
- 应用场景:开发环境
- 部署步骤:
- 设置 JDK运行环境
- 配置 SSH 免密登录
- 下载并解压缩 Flink-1.13.1 到 /export/server
- 修改配置文件
jobmanager.rpc.address: node1 - 开启flink环境查看web UI监控
开启集群
[root@node1 bin]# start-cluster.sh
#访问监控页面 webUI
http://node1:8081
- Standalone 使用Flink自带的资源调度平台进行任务的部署
- 应用场景:开发、测试使用
- 安装部署: flink/conf/flink-conf.yaml 基础配置
# jobManager 的IP地址
jobmanager.rpc.address: node1
# JobManager 的端口号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存大小
jobmanager.memory.process.size: 1600m
# TaskManager JVM heap 内存大小
taskmanager.memory.process.size: 1728m
# 每个 TaskManager 提供的任务 slots 数量大小
taskmanager.numberOfTaskSlots: 2
#是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源
taskmanager.memory.preallocate: false
# 程序默认并行计算的个数
parallelism.default: 1
#JobManager的Web界面的端口(默认:8081)
jobmanager.web.port: 8081
- 配置 worker文件
- 将每个从节点 hostname 保存,一行一个
- 将flink的程序及配置拷贝到其他的节点
- scp flink 复制到其他节点
scp /export/server/flink root@node2:/export/server
scp /export/server/flink root@node3:/export/server
- 配置环境变量
vim /etc/profile
FLINK_HOME=/export/server/flink
PATH=$PATH:$FLINK_HOME/bin
# 立即生效
source /etc/profile
-
开启Flink集群
start-cluster.sh -
查看当前的 Flink集群的状态,webUI
node1:8081
-
执行 wordcount 任务执行,run word-count 案例
- 在 hdfs 上上传文件
- flink run 执行这个任务并加载文件
-
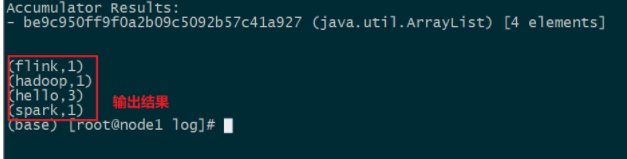
执行 wordcount 命令
flink run /export/server/flink/examples/batch/WordCount.jar -p 1 --input hdfs://node1:8020/words.txt```
参数解释
flink run 提交执行任务 类似于 spark-submit
-p 1 并行度设置为1
–input 当前输入的参数
/export/server/flink/examples/batch/WordCount.jar jar包位置
3.Standalone-HA高可用的部署方式
使用场景:开发、测试使用
部署步骤:和 Standalone 部署方式几乎一样,区别:
- 需要将每一台节点的 flink-conf.yaml 中 HA 高可用的zookeeper设置并将zookeeper集群地址设置好
配置 flink-conf.yaml 在 notepad++ 中
具体配置的参数
node1
#==============================================================================
# Common
#==============================================================================
# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn/Mesos 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









