






 本文介绍如何利用Scrapy框架爬取360图片网站上的动态加载美女图片,包括项目搭建、Spider编写、数据持久化及使用Selenium辅助爬取。
本文介绍如何利用Scrapy框架爬取360图片网站上的动态加载美女图片,包括项目搭建、Spider编写、数据持久化及使用Selenium辅助爬取。
爬取360图片上的美女图片
360图片网站上的图片是动态加载的,动态加载 就是通过ajax请求接口拿到数据喧染在网页上。我们就可以通过游览器的开发者工具分析,在我们向下拉动窗口时就会出现这么个请求,如图所示:
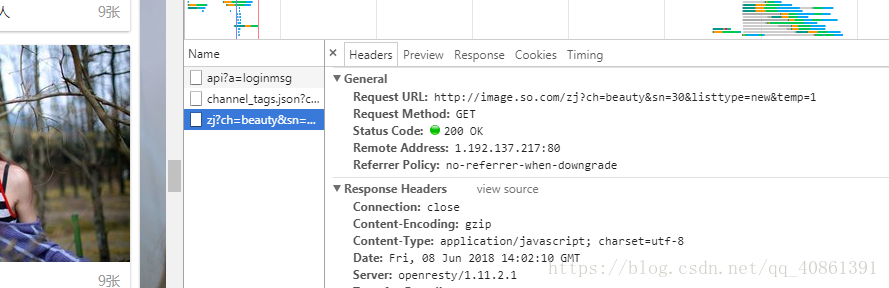
所以就判定这个url就是ajax请求的接口:,http://image.so.com/zj?ch=beauty&sn=30&listtype=new&temp=1,通过分析,sn=30 表示取的是前面30条数据,sn=60取的是30到60条的数据,我们就可以通过改变sn的数来拿到不同的数据,下面就开始我们的scrap项目:
# 在虚拟环境里创建项目
scrapy startproject image360
# 创建蜘蛛
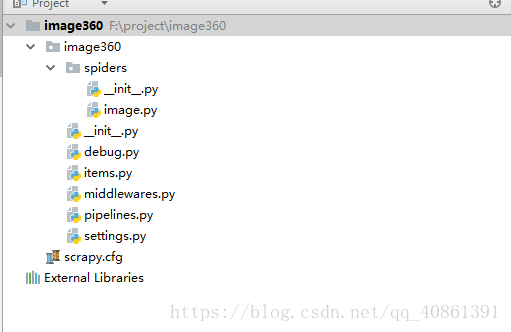
scrapy genspider image image.so.com项目目录结构如下:
首先建立保存数据的模型:在items.py文件中
import scrapy
class ImageItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 图片的标题
tag = scrapy.Field() # 图片的标签
width = scrapy.Field() # 图片的宽度
height = scrapy.Field() # 图片的高度
url = scrapy.Field() # 图片的url开始写蜘蛛:在iamge.py文件中
import scrapy
from urllib.parse import urlencode
from json import loads
class ImageSpider(scrapy.Spider):
name = 'image' # 蜘蛛的名字
allowed_domains = ['image.so.com'] # 允许访问的域名
# 因为不和以前一样给一个初始url,所以需要重写父类的start_requests方法
def strat_requests(self):
# 定义一个基础的url
base_url = 'http://image.so.com/zj?'
# 把固定的参数保存在一个字典里
param = {'ch': 'beauty', 'listtype': 'new', 'temp': 1}
# 我们拿数据只需要改变sn的值,所以我们来个循环,我们拿300条数据
for page in range(10):
# 把sn和对应的数添加到字典里
param['sn'] = page * 30
# 一个完整的url
full_url = base_url + urlencode(param)
# 返回一个生成器,
yield scrapy.Request(url=full_url, callback=self.parse)
def def parse(self, response):
# 把从接口里拿到的数据转成字典
model_dict = loads(response.text)
# 找到对应的数据放在item里
for elem in model_dict['list']:
item = ImageItem()
item['title'] = elem['group_title']
item['tag'] = elem['tag']
item['width'] = elem['cover_width']
item['height'] = elem['cover_height']
item['url'] = elem['qhimg_url']
yield item
数据的持久化:在pipelines.py文件中
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
from pymongo import MongoClient
# 下载图片的类,继承了scrap的ImagesPipeline类,并且重写了里面3个方法
class SaveImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield Request(url=item['url'])
def item_completed(self, results, item, info):
if not results[0][0]:
raise DropItem('下载失败')
return item
# 获取文件的文件名的方法
def file_path(self, request, response=None, info=None):
return request.url.split('/')[-1]
# 保存到数据库的类
class SaveToMongoPipeline(object):
def __init__(self, mongo_url, db_name):
self.mongo_url = mongo_url
self.db_name = db_name
self.client = None
self.db = None
self.collect = None
# 把item数据存入mongo数据库里
def process_item(self, item, spider):
# item['image_name'] = item['url'].split('/')[-1]
# self.db.image.insert(dict(item))
self.collect.insert_one(dict(item))
return item
# 创建连接mongo数据库的方法,在开始爬虫程序时自动调用
def open_spider(self, spider):
self.client = MongoClient(self.mongo_url)
self.db = self.client[self.db_name]
self.collect = self.db.image
# 关闭连接的方法,在爬虫程序结束时自动调用
def close_spider(self, spider):
self.client.close()
# 这是个类方法
@classmethod
def from_crawler(cls, crawler):
# 当return cls时就会调用该类的初始方法__init__,就把连接mango数据库的参数和数据库名字传过去
# crawler.setting.get('MONGO_URL')就是拿到settings.py文件里设置的 MONGO_URL
return cls(crawler.settings.get('MONGO_URL'),
crawler.settings.get('MONGO_DB'))
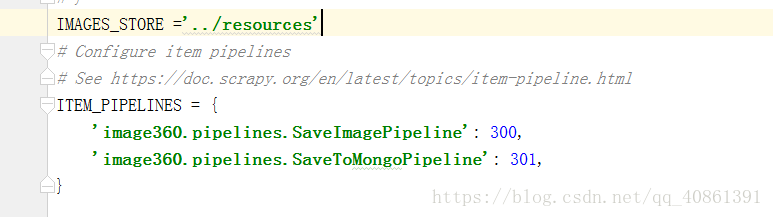
在配置文件中开启pipelines
使用webdriver
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
def main():
driver = webdriver.Chrome()
driver.get('https://v.taobao.com/v/content/live?catetype=704&from=taonvlang')
soup = BeautifulSoup(driver.page_source, 'lxml')
for img_tag in soup.body.select('img[src]'):
url = img_tag.attrs['src']
try:
if not str(url).startswith('http'):
url = 'http:' + url
filename = url[url.rfind('/') + 1:]
resp = requests.get(url)
with open('../images/' + filename,'wb') as f:
f.write(resp.content)
except OSError:
print(filename + '下载失败')
print('图片下载完成')
if __name__ == '__main__':
main()

















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









