







不知不觉已经入职3个月了,同事很好,工作充实,学到了很多东西,大大小小的需求也实现了接近20个。负责2个主要component,数据抓取和利用GenAI做数据提取。
1 背景
提取新闻中事件关键信息,比如人名,时间,事件等,并给出摘要,减少人工审查成本。
2 主要组件
- 数据抓取:一键抓取内部可信数据,输入到系统前端界面,免去用户人工填写的成本和差错。
- 前端:将可信数据和新闻事件提交到后台,等待分析结果。
- 后端:权限控制,调用GenAI模块进行提取,将提取结果返回前端,并做数据持久化。
- GenAI:提取新闻中的关键信息,并返回给后端。
- Dashboard:监控整个系统健康状态,如响应时间,消息队列长度,用户反馈,安全检测等。
3 数据抓取
3.1 win32应用程序数据抓取
3.1.1 Windows程序窗口定位
有两种方式定位到Windows程序窗口,1.通过窗口标题,2.通过进程名字找pid,进而定位窗口。第一种适合窗口标题固定,第二种适配多语言系统。
- 通过窗口标题定位窗口
import pygetwindow,win32gui
all_windows = pygetwindow.getAllWindows() # 获取所有窗口
app_title_list = [app.title for app in all_windows if app!=''] # 获取所有非空窗口标题
for item in app_title_list:
if "窗口标题前缀" in item:
find_window = pygetwindow.getWindowsWithTitle(item) # 如果窗口标题是固定的,直接调用这句,这里使用app_title_list再遍历是因为要获取的窗口标题仅有前缀固定
find_window.activate() # 激活窗口
find_window.maximize() # 窗口最大化
win32gui.SetForegroundWindow(find_window._hWnd) # 窗口最前
- 根据进程名字找到pid,进而定位窗口
import psutil,win32process,win32gui
def get_pid_by_name(process_name): # 通过任务管理器中的进程名字定位,一般是固定的,并且是英语不会随系统语言变化
for proc in psutil.process_iter(['pid','name']) # 拉出系统所有进程
if proc.info['name']==process_name: # 名字匹配
return proc.info['pid'] # 返回名字匹配进程的pid
return None
def get_window_title_by_pid(pid): # 根据pid获取窗口名
def callback(hwnd, hwnd_list):
_, process_id = win32process.GetWindowThreadProcessId(hwnd) # 根据hwnd获取窗口的进程PID
if process_id = pid:
window_title = win32gui.GetWindowText(hwnd) # 通过窗口的标题名获取窗口句柄
hwnd_list.append(window_title)
return True # 继续枚举下一个窗口
windows_titles = []
win32gui.EnumWindows(callback, window_titles)# 遍历系统中所有的顶层窗口,并针对每个窗口调用一次 callback 函数。遍历过程中,符合条件(进程 ID 与目标 PID 相等)的窗口标题会被添加到 windows_titles 列表中。
return window_titles
pid = get_pid_by_name("xxx.exe")
window_titles = get_window_title_by_pid(pid)
for item in window_titles:
if "窗口标题前缀" in item:
进行处理咯
win32api 鼠标定位及点击操作:
import win32con,win32api,pygetwindow
find_window = pygetwindow.getWindowsWithTitle(item) #
x,y = int(find_window.left),int(find_window.right)
win32api.SetCursorPos([x,y]) # 鼠标移动到到程序窗口左下角
win32api.mouse_event(win32con.MOUSEEVENTF_RIGHTUP | win32con.MOUSEEVENTF_RIGHTDOWN,0,0,0,0) # 右键点击
win32api.mouse_event(win32con.MOUSEEVENTF_LEFTUP | win32con.MOUSEEVENTF_LEFTDOWN,0,0,0,0) # 左键点击
pyautogui键盘操作, pyperclip剪切板
from pyautogui import press, hotkey
import pyyperclip
pyperclip.copy("") # 剪贴板置为空字符串
prees("tab")
hotkey("ctrl","a")
hotkey("ctrl","c")
text = pyperclip.waitForPaste() # 一直等待,获取剪贴板内容
3.2 利用selenium将数据传入前端
两种方法:
- 前端设置1个隐藏元素demo,用js脚本把json传过去
driver.execute_script("return document.getElementById('demo').value='"+data+"';") - 通过id定位元素,然后sendkeys发送值
element = driver.find_element_by_id('demo1') # 定位到id为demo1的元素 element.sendkeys(data) # 把data传给demo1元素
避免chrome重复启动
import os
import PySimpleGUI as sg
from selenium import webdriver
from selenium.webdriver.common.utils import is_connectable
from selenium.webdriver.chrome.options import Options
if not is_connectable(9527):
os.popen(r'start chrome --remote-debugging-port=9527')
options = Options()
options.add_experimental_option("debuggerAddress","127.0.0.1:9527")
try:
driver = webdriver.Chrome(executable_path="chromedriver.exe",options=option)
except:
sg.popup("pleas update chromedriver.exe")
exit()
local_token = driver.execute_script("return window.localStorage.getItem('proj_token')") # login之后设置token保存状态, 避免重复login
driver.switch_to.window(driver.current_window_handle) # 切换焦点到当前窗口
3.3 pyinstall打包成exe
如果涉及到一些配置文件打包,比如excel文件,可以用–add-data指定
pyinstall --noconfirm --onefile --nowindow --noconsole --add-data "demo.xlsx:." --name="app." main.py
这是打包成一个exe,运行时可以读取demo.xlsx内容
4 GenAI
4.1 prompt编写
langchain的PromptTemplate,可以传递参数到prompt,实现定制化
pip install langchain==0.3.2
from langchain_core.prompts import PromptTemplate
prompt_sample = """ 假设你是一位老师,请你回答如果面对{place_holder}这种情况会怎么办""" # 这里的place_holder就是一会要传入的参数
prompt_final = PromptTemplate(input_variables=["place_holder"],template=prompt_sample)
prompt_final = prompt_final.format(place_holder="有小朋友在大哭")
4.2 asycio异步IO
老生常谈,多进程适用于CPU密集型任务,比如数学运算,多线程适用于IO密集型任务,比如耗时的爬虫。但是异步IO既不是多线程,也不是多进程。
异步IO(async IO)并不是多线程,也不是多进程。它没有建立在这两者之上。
事实上,异步IO(async IO)是一种单线程、单进程的设计:它使用协作式多任务处理。换句话说,虽然在单个进程的单个线程中运行,但异步IO给人一种并发的感觉。协程(异步IO的核心特性)可以并发调度,但它们本身并不是并发的。
再次强调,异步IO是一种并发编程风格,但它并不是并行。它与线程更为相似,而不是多进程,但与这两者都有明显区别,并且作为并发编程中独立的成员存在。
- 异步例程能够在等待最终结果时"暂停",同时让其他例程运行。
- 通过上述机制,异步代码实现了并发执行。换句话说,异步代码给人一种并发的感觉。
协作式多任务处理就是程序的事件循环(稍后会详细介绍)与多个任务进行通信,在最佳时间让每个任务轮流运行。(棋盘对局,高手每盘棋只走一步,然后换棋盘)
异步IO利用长时间的等待期间,允许其他功能在这段空闲时间内运行。(阻塞的函数会在开始执行时禁止其他函数运行,直到其返回为止。)
4.1 asyncio包和async/await关键字
Python的asyncio包(在Python 3.4中引入)以及它的两个关键字async和await,分别担当着不同的角色,协助你声明、构建、执行和管理异步代码。
async/await 语法和原生协程
异步 IO 的核心是协程。协程是 Python 生成器函数的一个特殊版本。让我们从一个基本定义开始,然后随着你的进展逐步构建:协程是一个函数,它在达到 return 之前可以暂停其执行,并且可以间接地将控制权传递给另一个协程一段时间。
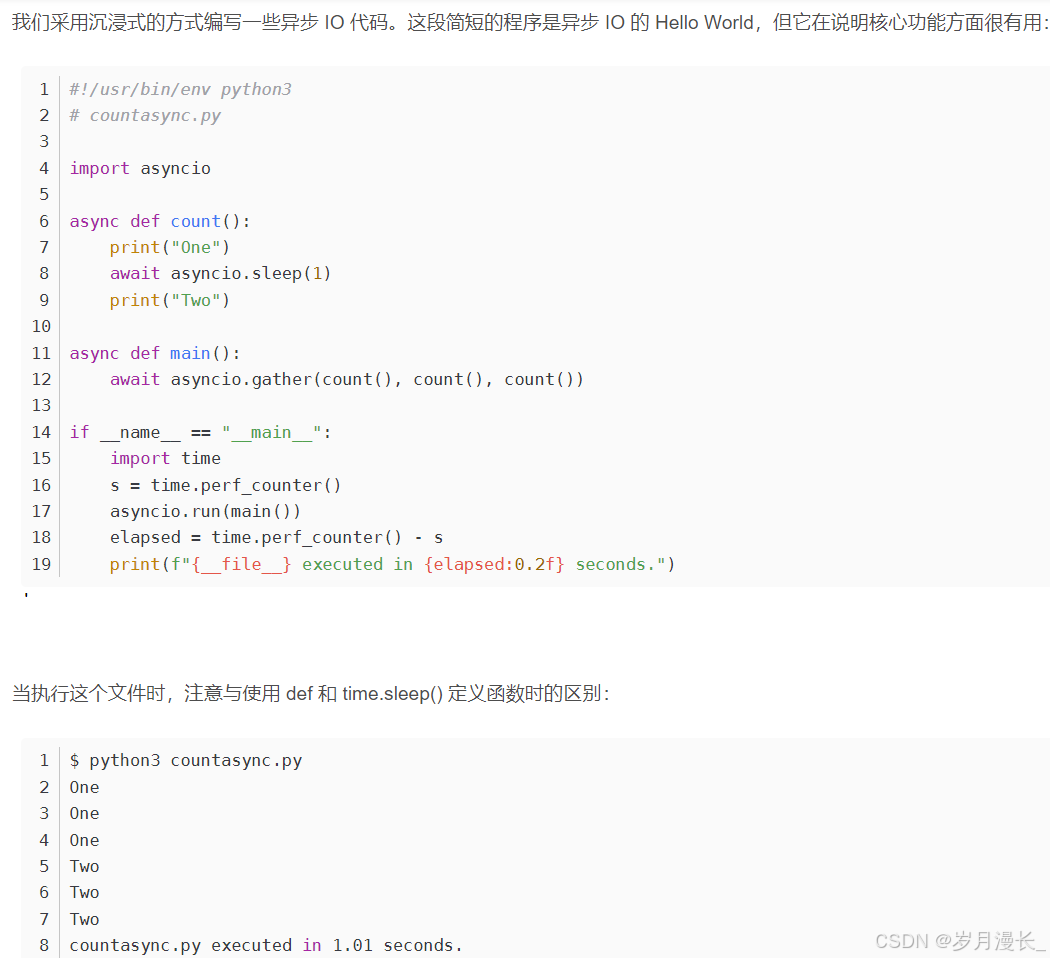
下面是同步版本的

import asyncio
semaphore = asyncio.Senmaphore(concurrency_limit) # 设置信号量为最大并发数concurrency_limit
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
整个项目的异步任务处理精简如下:
from concurrent.futures import thread
import queue
from threading import Thread
from flask import Flask, request, jsonify
import asyncio
import redis
import json
from gevent import pywsgi
Queue = queue.Queue()
redis_client = redis.Redis(
host='localhost',
port=6379,
db=0,
password='password',
decode_responses=True,
socket_keepalive=True,
socket_connect_timeout=10,
socket_timeout=10
)
queue_name = "genai_queue"
concurrency_limit = 10
semaphore = asyncio.Semaphore(concurrency_limit)
async def process_item(data):
try:
await asyncio.wait_for(asyncio.sleep(1), timeout=10)
print(f"Processing data: {data}")
return {"status": "success:" + data["id"]}
except asyncio.TimeoutError:
print(f"Timeout processing data: {data}")
return {"status": "timeout", "data": data}
async def consumer(loop):
while True:
try:
data = await loop.run_in_executor(None, Queue.get)
if data is None:
break
async with semaphore:
try:
result = await process_item(data)
except Exception as e:
print(f"Error processing data: {e}")
result = {"status": "error", "message": str(e)}
finally:
try:
if redis_client.ping():
redis_client.lrem(queue_name, 0, json.dumps(data))
except redis.RedisError as re:
print(f"Redis error: {re}")
except Exception as e:
print(f"Consumer error: {e}")
finally:
loop.run_in_executor(None, Queue.task_done)
def start_consumer_loop(concurrency_limit):
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
consumers = [consumer(loop) for _ in range(concurrency_limit)]
loop.run_until_complete(asyncio.gather(*consumers))
def create_app():
app = Flask(__name__)
thread = Thread(target=start_consumer_loop, args=(concurrency_limit,))
thread.start()
@app.teardown_appcontext
def shutdown(exception=None):
for _ in range(concurrency_limit):
Queue.put(None)
thread.join(timeout=10)
redis_client.close()
return app
app = create_app()
@app.route('/process', methods=['POST'])
def process_data():
data = request.get_json()
Queue.put(data)
redis_client.rpush(queue_name, json.dumps(data))
return jsonify({"status": "success"})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000, debug=False, threaded=True)
server = pywsgi.WSGIServer()
server.serve_forever()
4.3 日志记录
默认的logging
4.3.1 日志以json格式保存
参考:python的logging模块实现json格式的日志输出 版本三
需要先安装 pip install python-json-logger
import sys
import time
import json
import datetime
import logging
import logging.config
from pythonjsonlogger.jsonlogger import JsonFormatter
class JsonFormatter(JsonFormatter):
def __init__(self, *args, **kwargs):
self.message_type = "json"
self.version = "v1.0"
super(JsonFormatter, self).__init__(*args, **kwargs)
def get_extra_fields(self, record):
# The list contains all the attributes listed in
# http://docs.python.org/library/logging.html#logrecord-attributes
builtin_attr_list = [
'args', 'asctime', 'created', 'exc_info', 'exc_text', 'filename', 'id', 'levelname', 'levelno', 'module',
'msecs', 'msecs', 'message', 'msg', 'name', 'pathname', 'relativeCreated', 'extra']
fields = {}
for key, value in record.__dict__.items():
if key not in builtin_attr_list:
fields[key] = repr(value)
fields["project"] = "WEHOST"
fields["team"] = "OPS"
fields["department"] = "IT"
fields["log_debug"] = True
return fields
def format_timestamp(self, time):
return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S %f')
def format(self, record):
# 这里最好改成一行,不要换行,方便后面读取json
message = {
'@timestamp': self.format_timestamp(record.created),
'@version': 'v1.0',
'name': record.name,
'host': self.host,
'pathname': record.pathname,
'levelno': record.levelno,
'filename': record.filename,
'module': record.module,
'exc_info': ''.join(traceback.format_exception(*record.exc_info)),
'exc_text': record.exc_text,
'stack_info': record.stack_info,
'created': time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(record.created)),
'msecs': record.msecs,
'relativeCreated': record.relativeCreated,
'type': self.message_type,
'level': record.levelname,
'message': record.getMessage(),
}
# Add extra fields
message.update(self.get_extra_fields(record))
return json.dumps(message, indent=4)
def get_logger():
LOGGING = {
# 基本设置
'version': 1, # 日志级别
'disable_existing_loggers': False, # 是否禁用现有的记录器
# 日志格式集合
'formatters': {
# 标准输出格式
'json': {
# [具体时间][线程名:线程ID][日志名字:日志级别名称(日志级别ID)] [输出的模块:输出的函数]:日志内容
# 'format': '[%(asctime)s][%(threadName)s:%(thread)d][%(name)s:%(levelname)s(%(lineno)d)]\n[%(module)s:%(funcName)s]:%(message)s',
# 'format': '[%(asctime)s][%(threadName)s:%(thread)d][%(created)s:%(process)d:%(processName)s][%(relativeCreated)s:%(msecs)s][%(pathname)s:%(filename)s][%(name)s:%(levelname)s:%(lineno)d)][%(module)s:%(funcName)s]:%(message)s',
# '()': JsonFormatter.format,
# 'class': 'pythonjsonlogger.jsonlogger.JsonFormatter',
'()': JsonFormatter,
}
'file_json': {
# [具体时间][线程名:线程ID][日志名字:日志级别名称(日志级别ID)] [输出的模块:输出的函数]:日志内容
'format': '[%(asctime)s][%(threadName)s:%(thread)d][%(name)s:%(levelname)s(%(lineno)d)]\n[%(module)s:%(funcName)s]:%(message)s',
# 'format': '[%(asctime)s][%(threadName)s:%(thread)d][%(created)s:%(process)d:%(processName)s][%(relativeCreated)s:%(msecs)s][%(pathname)s:%(filename)s][%(name)s:%(levelname)s:%(lineno)d)][%(module)s:%(funcName)s]:%(message)s',
# '()': JsonFormatter.format,
'class': 'pythonjsonlogger.jsonlogger.JsonFormatter',
# '()': JsonFormatter,
}
},
# 处理器集合
'handlers': {
# 输出到控制台
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
'formatter': 'json',
'stream': sys.stdout
},
# 输出到日志文件
'file_handler': {
'level': 'DEBUG',
'class':'logging.handlers.TimeRotatingFileHandler',
'when':'midnight', # S,M,H,D,W
'formatter': 'json',
'stream': sys.stdout
},
},
# 日志管理器集合
'loggers': {
# 管理器
'mylog': {
'handlers': ['console','file_handler'],
'level': 'DEBUG',
'propagate': True, # 是否传递给父记录器
},
}
}
logging.config.dictConfig(LOGGING)
logger = logging.getLogger("mylog")
return logger
# 测试用例,你可以把get_logger()封装成一个模块,from xxx import get_logger()
logger = get_logger()
def main():
try:
a = 1 / 0
except Exception as e:
# 如果需要添加额外的信息,使用extra关键字即可
logger.info("This is a info message", extra={"type": "json", "department": "IT", "bussiness": "game"},
exc_info=True)
logger.info("Hello World", extra={"key1": "value1", "key2": "value2"}, exc_info=True)
# 其他错误处理代码
pass
if __name__ == '__main__':
main()
一些常用参数:
20241219 更新
换成了nb_log,因为TimeRotatingFileHandler在多进程下并不安全,会导致多次日志分割,导致部分日志丢失
from nb_log import get_logger
logger = get_logger('lalala',) # get_logger 只有一个name是必传递的,其他的参数不是必传。
# logger = get_logger('lalala',log_filename='lalala.log',formatter_template=5,log_file_handler_type=2) # get_logger有很多其他入参可以自由定制logger。
常用参数:
:param log_filename: 日志文件名字,仅当log_path和log_filename都不为None时候才写入到日志文件。
:param log_file_handler_type :这个值可以设置为1 2 3 4 5 6 7,
1为使用多进程安全按日志文件大小切割的文件日志
2为多进程安全按天自动切割的文件日志,同一个文件,每天生成一个日志 (替换TimeRotatingFileHandler)
3为不自动切割的单个文件的日志(不切割文件就不会出现所谓进程安不安全的问题)
4为 WatchedFileHandler,这个是需要在linux下才能使用,需要借助lograte外力进行日志文件的切割,多进程安全。
5 为第三方的concurrent_log_handler.ConcurrentRotatingFileHandler按日志文件大小切割的文件日志,
这个是采用了文件锁,多进程安全切割,文件锁在linux上使用fcntl性能还行,win上使用win32con性能非常惨。按大小切割建议不要选第5个个filehandler而是选择第1个。
6 为作者发明的高性能多进程安全,同时按大小和时间切割的文件日志handler
7 为 loguru的 文件日志记录器
:param formatter_template :日志模板,如果为数字,则为nb_log_config.py字典formatter_dict的键对应的模板,
1为formatter_dict的详细模板,2为简要模板,5为最好模板。
如果为logging.Formatter对象,则直接使用用户传入的模板。
这里可以自己定义json的输出模板,比如用上面的JsonFormatter
其他的参数可以通过nb_log_config.py去修改
经Linux上测试,多进程下nb_log安全
4.3.2 查询日志
选择开始日期和结束日期查询日志,并实现分页,按key排序的API
from http import HTTPStatus
import json
import os
from flask import Flask, request, jsonify, make_response
import datetime
app = Flask(__name__)
base_dir = os.path.dirname(os.path.abspath(__file__))
log_path = os.path.join(base_dir, "flask_api", "logs")
@app.route("/query_log", methods=["GET"])
def query_log():
start_date = request.args.get("start_date")
end_date = request.args.get("end_date")
current_page = int(request.args.get("current_page"))
page_size = int(request.args.get("page_size"))
sort_propertie = request.args.get("sort_propertie")
sort_order = request.args.get("sort_order")
sort_order = False if sort_order == "asc" else True
keyword = request.args.get("keyword")
# query the log data based on the given parameters
# and return the result as a JSON response
# 如果没有提供开始日期和结束日期,返回错误信息
if not start_date or not end_date:
# 返回错误信息和状态码
response_data = {
"code": HTTPStatus.BAD_REQUEST.value,
"message": "start_date and end_date are required",
}
return make_response(jsonify(response_data), HTTPStatus.BAD_REQUEST.value)
# 进行查询,并返回查询结果
try:
start_date = datetime.datetime.strptime(start_date, "%Y-%m-%d")
end_date = datetime.datetime.strptime(end_date, "%Y-%m-%d")
except ValueError as e:
response_data = {"code": HTTPStatus.BAD_REQUEST.value, "message": str(e)}
return make_response(jsonify(response_data), HTTPStatus.BAD_REQUEST.value)
data_list = []
current_date = start_date
last_day = False
while current_date <= end_date and not last_day:
if current_date.date() == datetime.datetime.today().date():
log_file_path = os.path.join(log_path, "log")
last_day = True
else:
log_file_path = os.path.join(
log_path, f"log.{current_date.strftime('%Y-%m-%d')}"
)
if not os.path.exists(log_file_path):
current_date += datetime.timedelta(days=1)
continue
try:
with open(log_file_path, "r") as f:
for line in f.readlines():
json_data = json.loads(line)
message = json_data.get("message", "")
if keyword == "" or keyword in message:
data_list.append(json_data)
except Exception as e:
continue
current_date += datetime.timedelta(days=1)
data_list = sorted(data_list, key=lambda x: x[sort_propertie], reverse=sort_order)
# 进行分页
total_count = len(data_list)
start_index = (current_page - 1) * page_size
end_index = start_index + page_size
total_page = (total_count + page_size - 1) // page_size
response_data = {
"code": HTTPStatus.OK.value,
"message": "success",
"data": data_list[start_index:end_index],
"total_count": total_count,
"total_page": total_page,
"current_page": current_page,
}
return make_response(jsonify(response_data), HTTPStatus.OK.value)
测试用例(ai生成,未验证):
def test_query_log():
# 测试用例1:正常查询
response = app.test_client().get(
"/query_log?start_date=2022-01-01&end_date=2022-01-02&page_size=10¤t_page=1&sort_propertie=timestamp&sort_order=desc&keyword=test"
)
assert response.status_code == 200
assert response.json["code"] == 200
assert response.json["message"] == "success"
assert len(response.json["data"]) == 10
assert response.json["total_count"] == 100
assert response.json["total_page"] == 10
assert response.json["current_page"] == 1
# 测试用例2:缺少参数
response = app.test_client().get(
"/query_log?start_date=2022-01-01&end_date=2022-01-02&page_size=10¤t_page=1&sort_propertie=timestamp&sort_order=desc"
)
assert response.status_code == 400
assert response.json["code"] == 400
assert response.json["message"] == "start_date and end_date are required"
# 测试用例3:日期格式错误
response = app.test_client().get(
"/query_log?start_date=2022-01-01&end_date=2022-01-02&page_size=10¤t_page=1&sort_propertie=timestamp&sort_order=desc&keyword=test"
)
assert response.status_code == 400
assert response.json["code"] == 400
assert response.json["message"] == "time data '2022-01-01' does not match format '%Y-%m-%d'"
# 测试用例4:关键字为空
response = app.test_client().get(
"/query_log?start_date=2022-01-01&end_date=2022-01-02&page_size=10¤t_page=1&sort_propertie=timestamp&sort_order=desc&keyword="
)
assert response.status_code == 200
assert response.json["code"] == 200
assert response.json["message"] == "success"
assert len(response.json["data"]) == 100
assert response.json["total_count"] == 100
assert response.json["total_page"] == 1
assert response.json["current_page"] == 1
# 测试用例5:关键字不匹配
response = app.test_client().get(
"/query_log?start_date=2022-01-01&end_date=2022-01-02&page_size=10¤t_page=1&sort_propertie=timestamp&sort_order=desc&keyword=not_exist"
)
assert response.status_code == 200
assert response.json["code"] == 200
assert response.json["message"] == "success"
assert len(response.json["data"]) == 0
assert response.json["total_count"] == 0
assert response.json["total_page"] == 0
assert response.json["current_page"] == 1
# 测试用例6:日期范围错误
response = app.test_client().get(
"/query_log?start_date=2022-01-02&end_date=2022-01-01&page_size=10¤t_page=1&sort_propertie=timestamp&sort_order=desc&keyword=test"
)
assert response.status_code == 400
assert response.json["code"] == 400
assert response.json["message"] == "start_date should be earlier than end_date"
if __name__ == "__main__":
test_query_log()
5 Dashboard
5.1 定时任务apscheduler
防止gunicorn设置多个worker情况下多次执行导致结果错误,可以用max_instance参数控制执行任务次数
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
scheduler.add_job(your_job,'cron',minute='00',max_instance=1) # 每个00分执行,
scheduler.start()
def your_job():
#这里放要执行的代码
5.2 统计每小时redis最大队列长度
双key,每次put队列的时候,用k1记录当前队列最大长度,并且每小时定时清零(实际是取当前队列长度),每次清零前将值赋给k2,后端稍后请求k2即可。这种方式可以实现不丢失一小时内的任何数据。
原因:如果仅使用k1记录队列峰值,那么后端请求如果在清零前拿k1,则拿到的并不是完整一小时的队列峰值数据;如果在清零后拿,则拿不到任何数据,没有意义。
def __init__():
redis_queue.set("k1","0") # 初始化
redis_queue.set("k2","0")
def put(item):
redis_queue.rpush(redis_queue_name, item)
queue_length = redis_queue.llen(redis_queue_name)
max_length = max(queue_length,int(redis_queue.get("k1"))) # peak_length是设置的缓存值,存储最大值
redis_queue.set("k1",max_lengnth)
def clear(): # 定时任务,每小时执行一次
redis_queue.set("k2",redis_queue.get("k1"))
redis_queue.set("k1",redis_queue.llen(redis_queue_name)) # 当前队列长度
def get_redis_peak_length(): # 清零之后,url路由到这来拿k2
return redis_queue.get("k2")


















 90
90

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











