







目录:
使用Redis的原因:高性能、高并发
1、什么事Redis
Remote Dictionary Server(远程字典服务)是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
2、Redis的基本数据结构类型
五种基本类型:
- String(字符串)<key, value>
是二进制安全的,可以存储图片或者序列化的对象,值最大存储为512M。
应用场景:共享session、分布式锁,计数器、限流。 - Hash(哈希)<key, <key, value>>
哈希类型是指v(值)本身又是一个键值对(k-v)结构。
应用场景:缓存用户信息等。 - List(列表)
用来存储多个有序的字符串。
应用场景:消息队列,文章列表。 - Set(集合).
用来保存多个不允许重复的字符串元素。
应用场景:用户标签,生成随机数抽奖、社交需求。 - zset(有序集合)
已排序的字符串集合,同时元素不能重复。
应用场景:排行榜,社交需求(如用户点赞)。
三种特殊的数据结构类型:
- Geospatial:Redis3.2推出的,地理位置定位,用于存储地理位置信息,并对存储的信息进行操作。
- Hyperloglog:用来做基数统计算法的数据结构,如统计网站的UV。
- Bitmap:用一个比特位来映射某个元素的状态。
3、Redis运行快的原因
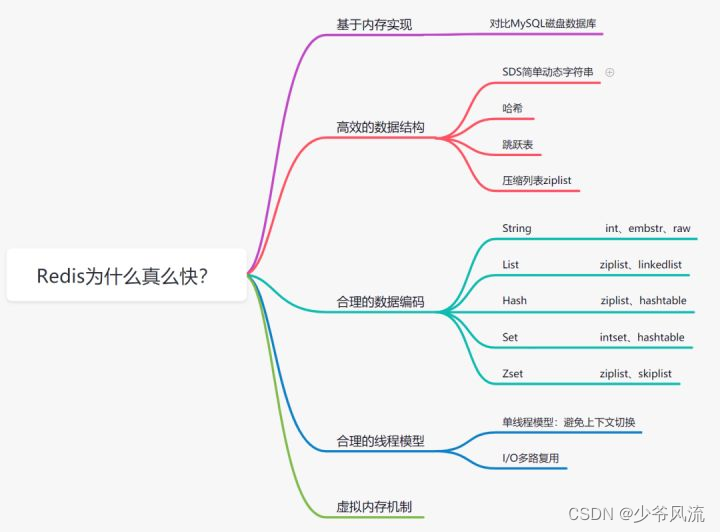
- 基于内存存储实现
相对于数据存在磁盘的MySQL数据库,省去磁盘I/O的消耗。 - 高效的数据结构
使用SDS动态字符串 - 合理的数据编码
根据不同的数据类型和数据大小选择不同的编码 - 合理的线程模型
使用多路I/O复用技术(多个网络 I/O复用同一个线程),不在网络I/O上浪费过多的时间。 - 单线程模型
避免了CPU不必要的上下文切换和竞争锁的消耗。 - 虚拟内存机制
Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。
Redis的虚拟内存机制是啥呢?
虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
4、缓存穿透、缓存击穿、缓存雪崩
- 缓存穿透:
读请求访问时,缓存和数据库都没有某个值,这样就会导致每次对这个值的查询请求都会穿透到数据库
产生原因:业务涉及不合理;操作失误;非法请求。
解决方案:
1、如果是非法请求,我们在API入口,对参数进行校验,过滤非法值。
2、如果查询数据库为空,我们可以给缓存设置个空值,或者默认值。但是如有有写请求进来的话,需要更新缓存哈,以保证缓存一致性,同时,最后给缓存设置适当的过期时间。
3、使用布隆过滤器快速判断数据是否存在。即一个查询请求过来时,先通过布隆过滤器判断值是否存在,存在才继续往下查。
- 缓存击穿:
指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
解决方案:
1.使用互斥锁方案。缓存失效时,不是立即去加载db数据,而是先使用某些带成功返回的原子操作命令,如(Redis的setnx)去操作,成功的时候,再去加载db数据库数据和设置缓存。否则就去重试获取缓存。
2. “永不过期”,是指没有设置过期时间,但是热点数据快要过期时,异步线程去更新和设置过期时间。
- 缓存雪崩:
指缓存中数据大批量到过期时间,而查询数据量巨大,请求都直接访问数据库,引起数据库压力过大甚至down机。
解决方案:构造Redis高可用集群。
5、Redis常见的应用场景
- 缓存
- 排行榜
- 计数器应用
- 共享Session
- 分布式锁
- 社交网络
- 消息队列
Redis提供了发布/订阅及阻塞队列功能,能实现一个简单的消息队列系统。但是,这个不能和专业的消息中间件相比。 - 位操作
6、实现Redis的高可用
Redis 实现高可用有三种部署模式:主从模式,哨兵模式,集群模式。
- 主从模式
Redis部署了多台机器,有主节点,负责读写操作,有从节点,只负责读操作。通过主从复制实现数据一致。
主从复制包括全量复制,增量复制两种。 - 哨兵模式
由一个或多个Sentinel实例组成的Sentinel系统,它可以监视所有的Redis主节点和从节点,并在被监视的主节点进入下线状态时,自动将下线主服务器属下的某个从节点升级为新的主节点。 - 集群模式
Cluster集群模式:实现了Redis的分布式存储。对数据进行分片,也就是说每台Redis节点上存储不同的内容,来解决在线扩容的问题。为了保证高可用,Cluster集群引入了主从复制,一个主节点对应一个或者多个从节点。当其它主节点 ping 一个主节点 A 时,如果半数以上的主节点与 A 通信超时,那么认为主节点 A 宕机了。如果主节点宕机时,就会启用从节点。
7、Redis如何设计分布式锁
锁:同一时间只允许一个线程或者一个应用程序进入执行
分布式锁:必须要求Redis有【互斥】能力,可以使用SETNX命令:即key不存在了才会设置它的值,否则什么也不做。
如何避免死锁?
场景:程序处理业务逻辑异常,或者进程挂了,无法释放锁
避免方案:给锁设置租期(过期时间)
锁的过期时间不好评估这么办?
加入看门狗:开启守护线程,定期检测锁的失效时间,如果快要过期了,业务还没执行完,则续期。
8、Redis如何解决key冲突
- 业务隔离
- key的设计
业务模块+系统名称+关键(id),针对用户可以加入(userid) - 分布式锁
场景:多个客户端并发写key
客户端拿到锁,才能进行操作,避免多个客户端竞争该key - 时间戳
key拼接时间戳,根据时间戳保证多个客户端的业务执行顺序

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









