







23种设计模式
参考:
https://blog.youkuaiyun.com/weixin_42139375/article/details/82503232 《大牛的23种设计模式及代码实现全解析》
https://blog.youkuaiyun.com/wwwdc1012/article/details/82780560 《设计模式|适配器模式及典型应用》
https://blog.youkuaiyun.com/weixin_41649320/article/details/81185915 《装饰模式》
https://blog.youkuaiyun.com/baidu_30325009/article/details/85028459《【设计模式学习笔记】原型模式》
Java设计模式(疯狂Java联盟版)
//第一次写博客有些紧张。
//借鉴了大牛的文章,大牛的文章没有建造者模式,抽象工厂方法也没代码 等,然后我从其他地方参考后补上了,还有一点点自己的想法。如果觉得我写得很差,可以去看大牛的。瑟瑟发抖。
//类图下次补,文章里有些很蠢的问题,但当时我心中确实有这种想法。
概要
总体来说设计模式分为三大类:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
简单工厂设计模式不属于23种。
0.简单工厂设计模式
### 普通简单工厂
简单工厂
实现方法:先创建一个接口Food,produce();
两个类cookies和bread实现接口Food
工厂类 接收到什么就生产什么
/*接口Food*/
public interface Food {
public void produce();
}
/*面包Bread实现Food*/
public class Bread implements Food {
@Override
public void produce() {
System.out.println("this is bread");
}
}
/*饼干Cookies实现Food*/
public class Cookies implements Food {
@Override
public void produce() {
System.out.println("this is Cookies");
}
}
/*工厂类 prdouce方法根据接收到的String 返回相应的类*/
public class Factory {
public Food produce(String type){
if(type=="Bread")
{
Bread br=new Bread();
return br;
}else if(type=="Cookies"){
Cookies co=new Cookies();
return co;
}
return null;
}
}
/*主函数*/
public static void main(String[] args) {
/*建立一个工厂*/
Factory fa=new Factory();
/*让工厂生产面包*/
Food food=fa.produce("Bread");
/*生产面包*/
food.produce();
}
优点:解耦 ,不同“食物”无直接关系。
比如 :如果现在需要生产第三类"面条",那么只需要写一个noodles类 实现Food接口,再修改工厂类的produce方法即可。
缺点:
还需要修改工厂类方法,如果生产的食物种类过多,该方法过于复杂,则很容易出问题。
多方法简单工厂
是对普通工厂方法模式的改进,在普通工厂方法模式中,如果传递的字符串出错,则不能正确创建对象,而多个工厂方法模式是提供多个工厂方法,分别创建对象。
实现方法:只需修改工厂类,将produce拆分成breadProduce和cookiesProduce
/*多方法工厂*/
public class MultimethodFactory {
public Food breadProudce(){
Bread bre=new Bread();
return bre;
}
public Food cookiesProudce(){
Cookies coo=new Cookies();
return coo;
}
}
/*主函数*/
public static void main(String[] args) {
MultimethodFactory fa=new MultimethodFactory();
/*调用面包生产方法*/
Food food=fa.breadProudce();
food.produce();
}
多方法工厂增加新的生产种类的时,工厂类就只需添加新方法而不需修改方法,降低了出错的可能,但如果生产种类过多会让工厂类变得很庞大
静态方法简单工厂
将上面的多个工厂方法模式里的方法置为静态的,不需要创建实例,直接调用即可。
/*静态方法简单工厂*/
public class StaticFactory {
public static Food breadProudce() {
return new Bread();
}
public static Food cookiesProudce() {
return new Cookies();
}
}
/*主函数*/
public static void main(String[] args) {
Food food=StaticFactory.breadProudce();
food.produce();
}
工厂类变小,出错的可能降低了很多
简单工厂方法的问题就在与需要修改工厂类,这违反了开闭原则,且生产种类过多时不利于单一职责原则,最少知道原则
创造型
单例模式(Singleton)
只允许有一个实例;
懒汉模式:(以时间换空间)
实现方法: 创建一个类(Task),在类中定义一个静态实例(task)和getinstance方法。在主函数中创建实例时调用此方法,getinstance方法先判断tak是否为空,为空则建造一个,不为返回tak(这样保证了同时只会存在一个实例);
/*创建一个Task类*/
public class Task {
/*定义三变量:血量,速度,方向*/
double flood;
int speed;
String direction;
/*创建一个静态Task 实例 为什么是静态?*/
private static Task tak;
/*得到实例方法*/
public static Task getinstance(){
if(tak==null){
tak=new Task();
}
return tak;
}
/*测试是否是同一个Task实例*/
/*Task构造函数*/
private Task(){
flood=Math.random();
}
/*得到实例速度*/
public double getFlood(){
return flood;
}
}
/*主函数*/
public static void main(String[] args) {
Task tak1=Task.getinstance();
Task tak2=Task.getinstance();
System.out.println(tak1.getFlood());
System.out.println(tak2.getFlood());
}
为什么要创建getinstance方法()而不直接用构造函数?;
我一开始就是准备用构造函数实现;我们需要判断tak是否为空,为空则建造一个,不为返回tak,所以用构造函数写就需要返回tak;
Task Task(){
if(tak==null){
/*随机初始化血量,调用重载的构造函数Task(double flo)*/
initialFlood=Math.random();
tak=new Task(initialFlood);
}
return tak;
}
但构造函数不能有返回值;
但我们经常看见这样的代码: Student stu=new Student(201933555654852,"张胜男"); 这似乎是调用了构造函数返回对象;
The Java Programming Language上说:
Constructors are invoked after the instance variables of a newly created object of the class have been assigned their default initial values and after their explicit initializers are executed.
构造方法是新创建的对象的实例变量缺省初始化以及显式初始化之后才执行的;
为什么是静态 ?(private static Task tak;);
static关键字声明一个属性或方法是和类相关的,而不是和类的某个特定的实例相关,因此,这类属性或方法也称为“类属性”或“类方法”。在没有实例的时候就调用 该方法。
饿汉模式 (以空间换时间)
一开始就创建实例
工厂方法模式(Factory Method)
简单工厂模式如果想要拓展程序,必须对工厂类进行修改,这违背了闭包原则。而工厂方法模式,创建一个工厂接口和创建多个工厂实现类,这样一旦需要增加新的功能,直接增加新的工厂类就可以了,不需要修改之前的代码。
实现方法:两个接口 Food和Factory,每个接口两个实现类Bread,Cook以及BreadFactory,CookFactory
/*Food接口及两个实现类的代码同上*/
/*工厂接口*/
public interface Factory {
public Food getFoodType() ;
}
/*工厂实现类*/
public class BreadFactory implements Factory {
@Override
public Food getFoodType() {
return new Bread();
}
}
public class CookiesFactory implements Factory {
@Override
public Food getFoodType() {
return new Cook();
}
}
/*主函数*/
public class FactoryMain {
public static void main(String[] args) {
Factory fa=new BreadFactory();
Food fo =fa.getFoodType();
fo.proudce();
}
}
如果想增加一个食物种类,则只需做一个实现类,实现Food接口,同时做一个工厂类,实现Factory接口,就OK了,无需去改动现成的代码
抽象工厂模式(AbstractFactory)
提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。
工厂方法模式和抽象工厂模式不好分清楚,他们的区别如下:
工厂方法模式:
一个抽象产品类,可以派生出多个具体产品类。
一个抽象工厂类,可以派生出多个具体工厂类。
每个具体工厂类只能创建一个具体产品类的实例。
抽象工厂模式:
多个抽象产品类,每个抽象产品类可以派生出多个具体产品类。
一个抽象工厂类,可以派生出多个具体工厂类。
每个具体工厂类可以创建多个具体产品类的实例,也就是创建的是一个产品线下的多个产品。
区别:
工厂方法模式只有一个抽象产品类,而抽象工厂模式有多个。
工厂方法模式的具体工厂类只能创建一个具体产品类的实例,而抽象工厂模式可以创建多个。
工厂方法创建 "一种" 产品,他的着重点在于"怎么创建",也就是说如果你开发,你的大量代码很可能围绕着这种产品的构造,初始化这些细节上面。也因为如此,类似的产品之间有很多可以复用的特征,所以会和模版方法相随。
抽象工厂需要创建一些列产品,着重点在于"创建哪些"产品上,也就是说,如果你开发,你的主要任务是划分不同差异的产品线,并且尽量保持每条产品线接口一致,从而可以从同一个抽象工厂继承。
对于java来说,你能见到的大部分抽象工厂模式都是这样的:
---它的里面是一堆工厂方法,每个工厂方法返回某种类型的对象。
比如说工厂可以生产鼠标和键盘。那么抽象工厂的实现类(它的某个具体子类)的对象都可以生产鼠标和键盘,但可能工厂A生产的是罗技的键盘和鼠标,工厂B是微软的。
这样A和B就是工厂,对应于抽象工厂;
每个工厂生产的鼠标和键盘就是产品,对应于工厂方法;
用了工厂方法模式,你替换生成键盘的工厂方法,就可以把键盘从罗技换到微软。但是用了抽象工厂模式,你只要换家工厂,就可以同时替换鼠标和键盘一套。如果你要的产品有几十个,当然用抽象工厂模式一次替换全部最方便(这个工厂会替你用相应的工厂方法)
所以说抽象工厂就像工厂,而工厂方法则像是工厂的一种产品生产线
public interface AbstractFactory {
public Cat createCat();
public Dog createDog();
}
//都是黑色
public class BlackFactory implements AbstractFactory {
@Override
public Cat createCat() {
return new BlackCat();
}
@Override
public Dog createDog() {
return new BlackDog();
}
}
//都是白色
public class WhiteFactory implements AbstractFactory {
@Override
public Cat createCat() {
return new WhiteCat();
}
@Override
public Dog createDog() {
return new WhiteDog();
}
}
//猫
public interface Cat {
public void product();
}
public class BlackCat implements Cat {
@Override
public void product() {
System.out.println("this is black cat");
}
}
public class WhiteCat implements Cat {
@Override
public void product() {
System.out.println("this is white cat");
}
}
//狗
public interface Dog {
public void product();
}
public class BlackDog implements Dog {
@Override
public void product() {
System.out.println("this is black dog");
}
}
public class WhiteDog implements Dog {
@Override
public void product() {
System.out.println("this is white dog");
}
}
public static void main(String[] args) {
AbstractFactory blf=new BlackFactory();
AbstractFactory whf=new WhiteFactory();
Cat bc=blf.createCat();
Cat wc=whf.createCat();
Dog bd=blf.createDog();
Dog wd=whf.createDog();
bc.product();
wc.product();
bd.product();
wd.product();
}
上述代码中将产品分为黑,白两类,也就是两种的接口,然后在相应的工厂里面通过调用方法(),与抽象产品类结合,产生具体的产品类。
原型模式(Prototype)
该模式的思想就是将一个对象作为原型,对其进行复制、克隆,产生一个和原对象类似的新对象。
Serializable
浅复制:将一个对象复制后,基本数据类型的变量都会重新创建,而引用类型,指向的还是原对象所指向的。
深复制:将一个对象复制后,不论是基本数据类型还有引用类型,都是重新创建的。简单来说,就是深复制进行了完全彻底的复制,而浅复制不彻底.
浅拷贝:
public class Prototype implements Cloneable ,Serializable{
private String string;
/*引用类型*/
private Test tes;
public String getString() {
return string;
}
public void setString(String string) {
this.string = string;
}
public Test getTes() {
return tes;
}
public void setTes(Test tes) {
this.tes = tes;
}
public Prototype(String string, Test tes) {
super();
this.string = string;
this.tes = tes;
}
@Override
public String toString() {
return "Prototype [string=" + string + ", tes=" + tes + "]";
}
/*浅拷贝*/
public Object clone() throws CloneNotSupportedException{
Prototype pr=(Prototype) super.clone();
return pr;
}
}
/*主函数*/
public static void main(String[] args) throws CloneNotSupportedException, ClassNotFoundException, IOException {
Test t=new Test(1,2,3,4);
Prototype pr=new Prototype("ffff",t);
Prototype pr2=(Prototype) pr.clone();
System.out.println(pr.toString());
System.out.println(pr2.toString());
}
结果:
Prototype [string=ffff, tes=prototype.Test@15db9742]
Prototype [string=ffff, tes=prototype.Test@15db9742]
引用类型:还是同一个
深拷贝:
public Prototype deepClone() throws IOException, ClassNotFoundException {
/* 写入当前对象的二进制流 */
ByteArrayOutputStream bos=new ByteArrayOutputStream();
ObjectOutputStream oos=new ObjectOutputStream(bos);
oos.writeObject(this);
/* 读出二进制流产生的新对象 */
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Prototype) ois.readObject();
}
要实现Serializable接口!不仅你的Prototype需要实现,Test tes也就是你在Prototype用到的引用类型也要实现Serializable接口!要实现Serializable接口!要实现Serializable接口!
建造者模式(Builder)
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
比如创建人类实例,person类用来表示人类,而构建人类的过程在personBuilder中,personBuilder可分为manBuilder,womanBuilder等等
PersonDirector.construction()接受建造器,建造“产品”,最后的产品是什么样由建造器决定
public class Person {
private String body;
public void setBody(String body){
this.body=body;
}
public String getBody(){
return body;
}
}
public class Man extends Person {
}
public class Woman extends Person {
}
以上是产品也就是“人”,只有属性和get(),set()。
public interface PersonBuilder {
//给“产品”的属性赋值
public void buildBody();
//返回“产品”
public Person buildPerson();
}
public class ManBuilder implements PersonBuilder {
private Person man;
//构造ManBuilder的同时构造了一个男人
public ManBuilder() {
this.man = new Man();
}
//给这个男人造了个身体,你也可以造别的
public void buildBody(){
this.man.setBody("制造男人");
}
//返回男人实例
@Override
public Person buildPerson() {
return man;
}
}
public class WomanBuilder implements PersonBuilder {
private Person woman;
//构造WomanBuilder的同时构造了一个女人
public WomanBuilder() {
this.woman = new Woman();
}
//制造身体
@Override
public void buildBody() {
this.woman.setBody("制造女人");
}
@Override
public Person buildPerson() {
return woman;
}
}
以上是建造类,主要是 构造产品(),赋值产品(),返回产品()
public class PersonDirector {
public Person construction(PersonBuilder pb){
//这里制造人
pb.buildBody();
//返回人
return pb.buildPerson();
}
}
//主函数
public static void main(String[] args) {
PersonDirector pd=new PersonDirector();
Person p1=pd.construction(new ManBuilder());
Person p2=pd.construction(new WomanBuilder());
System.out.println(p1.getBody());
System.out.println(p2.getBody());
}
结果:
制造男人
制造女人
如果还需要其他的,比如 老人,小孩,只需要相应的构造器(ChildBuilder),和实行person的类(如Child),主函数的操作不变
结构型
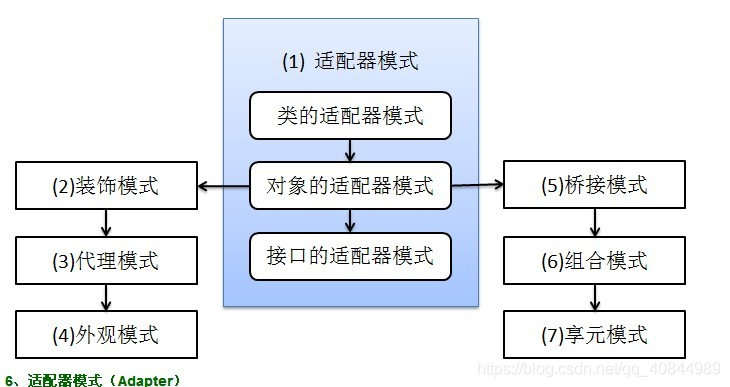
适配器模式(Adapter)
适配器模式将某个类的接口转换成客户端期望的另一个接口表示,目的是消除由于接口不匹配所造成的类的兼容性问题。主要分为三类:类的适配器模式、对象的适配器模式、接口的适配器模式。
类的适配器模式
将一个类转换成满足另一个新接口的类
在类适配器模式中,适配器与适配者之间是继承(或实现)关系。
实现方法:
Target(目标抽象类):目标抽象类定义客户所需接口,可以是一个抽象类或接口,也可以是具体类。
Adaptee(适配者类):适配者即被适配的角色,它定义了一个已经存在的接口,这个接口需要适配,适配者类一般是一个具体类,包含了客户希望使用的业务方法;
Adapter(适配器类):适配器可以调用另一个接口,作为一个转换器,对Adaptee和Target进行适配。
/*适配者*/
public class Adaptee {
public void adapteeMethon(){
System.out.println("被适配者方法");
}
}
/*目标抽象类*/
public interface Target {
void call();
}
我们如何在目标接口中的call()调用适配者的adapteeMethon()?;
/*适配器类*/
public class Adapter extends Adaptee implements Target {
@Override
public void call() {
super.adapteeMethon();
}
}
/*主函数*/
public class AdapterMain {
public static void main(String[] args) {
Target target=new Adapter();
target.call();
}
}
当我们将Adaptee类与另一个接口适配时,就只需修改适配器类
对象的适配器模式
对象适配器与类适配器不同之处在于,类适配器通过继承来完成适配,对象适配器则是通过关联来完成,这里稍微修改一下 Adapter 类即可将转变为对象适配器
/*对象适配器*/
public class ObjectAdapter implements Target {
Adaptee ada=new Adaptee();
@Override
public void call() {
ada.adapteeMethon();
}
}
接口的适配器模式
又叫缺省适配器模式(Default Adapter Pattern),单接口适配器模式。当不需要实现一个接口所提供的所有方法时,可先设计一个抽象类实现该接口,并为接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可以选择性地覆盖父类的某些方法来实现需求,它适用于不想使用一个接口中的所有方法的情况
装饰模式(Decorator)
顾名思义,装饰模式就是给一个对象增加一些新的功能,而且是动态的,要求装饰对象和被装饰对象实现同一个接口,装饰对象持有被装饰对象的实例。
/*被装饰的类的接口*/
public interface DecoratedObjectInterface {
void menthon();
}
/*被装饰的类*/
public class DecoratedObject implements DecoratedObjectInterface {
@Override
public void menthon() {
System.out.println("this is original menthon");
}
}
如何给DecoratedObject类动态的添加新功能,方法?
/*装饰类实现被装饰的类的接口,持有被装饰类对象,重载构造函数,新方法*/
public class Decorator implements DecoratedObjectInterface {
/*被装饰类对象*/
private DecoratedObjectInterface dec;
/*新方法*/
public void menthon() {
/*添加的新方法*/
System.out.println("this is new menthon");
/*旧类调用旧方法*/
dec.menthon();
}
/*重载构造函数*/
Decorator(DecoratedObjectInterface dec){
/*this指针指向当前对象,这里指向Decorator的实例;此语句使构造函数收到的对象赋值给当前实例持有的DecoratedObjectInterface 实例(dec)*/
this.dec=dec;
}
}
/*主方法函数*/
public static void main(String[] args) {
/*被装饰对象实例*/
DecoratedObjectInterface object = new DecoratedObject();
/*装饰 被装饰实例*/
DecoratedObjectInterface decoratedobject=new Decorator(object);
/*装饰后的实例调用方法*/
decoratedobject.menthon();
}
这并不是增加一个方法,而是在原有方法的基础上改造,新增新功能,但方法数量没变。
案例:机甲战士,首先机甲的装备能被机甲使用,一定是有共性,将共性抽象成一个接口(Mecha)(机甲),自己使用的帝王机甲(MonarchMecha)实现该接口,给搞两装备加特林(Gatlin),巴雷特(Barrett)也实现接口
/*抽象机甲类*/
public interface Mecha {
public void Fight();
}
/*帝王机甲*/
public class MonarchMecha implements Mecha {
@Override
public void Fight() {
System.out.println("帝王拳");
}
}
/*加特林*/
public class Gatlin implements Mecha {
private Mecha mecha;
@Override
public void Fight() {
System.out.println("加特林的金属洪流!");
mecha.Fight();
}
Gatlin(Mecha mecha){
this.mecha=mecha;
}
}
/*巴雷特*/
public class Barrett implements Mecha {
private Mecha mecha;
public void Fight() {
System.out.println("来自巴雷特的制裁");
mecha.Fight();
}
Barrett(Mecha mecha){
this.mecha=mecha;
}
}
/*主函数*/
public static void main(String[] args) {
/*召唤机甲*/
Mecha mecha=new MonarchMecha();
/*加载武器*/
Gatlin gatlinMecha=new Gatlin(mecha);
Barrett barrettGatlinMecha =new Barrett(gatlinMecha);
barrettGatlinMecha.Fight();
}
来自巴雷特的制裁
加特林的金属洪流!
帝王拳
(1)在主函数中 首先创建一个机甲对象mecha(实际是帝王铠甲类的对象)
(2)再创建一个带加特林的机甲gatlinMecha,调用了重载的构造函数,构造函数将mecha赋值给gatlinMecha私有的机甲对象(假定对象名为GM);
(3)再创建带巴雷特(带加特林)的机甲,构造函数将gatlinMecha赋值给barrettGatlinMecha私有的机甲对象(假定对象名为BGM);
(4)最后调用barrettGatlinMecha.Fight(),Fight先打一发大炮,再调用mecha.Fight(),此时的mecha是BGM,BGM就是gatlinMecha,所以就是调用gatlinMecha.Fight(),再来波金属洪流,再调用GM,帝王拳警告!
代理模式(Proxy)
代理模式就是多一个代理类出来,替原对象进行一些操作,代理对象控制对目标对象的引用
案例:A(PeopleA)让B(PeopleB)代购,AB为人(People类,都有购买方法())
public interface People {
public void buy();
}
public class PeopleA implements People {
@Override
public void buy() {
System.out.println("Buy something A");
}
}
public class PeopleB implements People {
People peoplea=new PeopleA();
@Override
public void buy() {
peoplea.buy();
this.addMenthon();
}
public void addMenthon(){
System.out.println("包装A");
}
}
/*主函数*/
public class ProxyMain {
public static void main(String[] args) {
PeopleB peopleb=new PeopleB();
peopleb.buy();
}
}
代理模式的重点在主函数中表示出来了,从表面上看是调用的B的方法,实际是A的方法,且添加的操作控制访问A。
代理模式在安卓开发中常用。
装饰模式是指增强被包装对象的功能
代理模式是修改被代理对象的行为
外观模式(Facade)
外观模式是为了解决类与类之家的依赖关系的
实现方法:三个类 cpu,memory,disk中都只有开启,关闭两个方法。三个类之间的关系放到类Computer中,通过调用Computer的方法,处理三者的关系。
public class CPU {
public void startup(){
System.out.println("cpu startup!");
}
public void shutdown(){
System.out.println("cpu shutdown!");
}
}
public class Memory {
public void startup(){
System.out.println("memory startup!");
}
public void shutdown(){
System.out.println("memory shutdown!");
}
}
public class Disk {
public void startup(){
System.out.println("disk startup!");
}
public void shutdown(){
System.out.println("disk shutdown!");
}
}
/**/
public class Computer {
private CPU cpu;
private Memory memory;
private Disk disk;
public Computer(){
cpu = new CPU();
memory = new Memory();
disk = new Disk();
}
public void startup(){
System.out.println("start the computer!");
cpu.startup();
memory.startup();
disk.startup();
System.out.println("start computer finished!");
}
public void shutdown(){
System.out.println("begin to close the computer!");
cpu.shutdown();
memory.shutdown();
disk.shutdown();
System.out.println("computer closed!");
}
}
/*主函数*/
public static void main(String[] args) {
Computer computer = new Computer();
computer.startup();
computer.shutdown();
}
外观模式降低了类类之间的耦合度,该模式中没有涉及到接口。如果我们没有Computer类,那么,CPU、Memory、Disk他们之间将会相互持有实例,产生关系,这样会造成严重的依赖,修改一个类,可能会带来其他类的修改,
桥接模式(Bridge)
桥接模式就是把事物和其具体实现分开,使他们可以各自独立的变化。桥接的用意是:将抽象化与实现化解耦,使得二者可以独立变化。
实现方法:接口Sourceable,两个类(桥要连接的地方——sub1,sub2)实现该接口;抽象类桥(bridge),我的桥(Mybridge)实现桥接口。桥要连接Scourse,所以要有Scourse实例,桥要调用Scourse方法,所以要有和Scourse方法名相同的方法,要实现切换,所以Scourse实例根据连接的地方更改;
public interface Sourceable {
public void menthon();
}
public class Sub1 implements Sourceable {
@Override
public void menthon() {
System.out.println("this is sub1");
}
}
public class Sub2 implements Sourceable {
@Override
public void menthon() {
System.out.println("this is sub2");
}
}
/*桥 为什么是抽象类?*/
public abstract class Bridge {
private Sourceable scouce;
public void setScouce(Sourceable scouce){
this.scouce=scouce;
}
public void menthon(){
scouce.menthon();
}
}
/*这个类好像可以不要*/
public class MyBridge extends Bridge {
}
/*主函数*/
public static void main(String[] args) {
Sourceable sub1=new Sub1();
Sourceable sub2=new Sub2();
Bridge myBridge=new MyBridge();
myBridge.setScouce(sub1);
myBridge.menthon();
myBridge.setScouce(sub2);
myBridge.menthon();
}
将抽象化与实现化解耦?
“桥”可以通过setScouce要连接的实例,来调用它的方法不需要修改任何地方
JDBC就是这样的
组合模式(Composite)
**组合模式有时又叫部分-整体模式在处理类似树形结构的问题时比较方便。**Vector
TreeNode:name;父节点;子节点Vector;添加子节点();删除子节点();
Tree:根节点;
public class TreeNode {
private String name;
private TreeNode parent;
private Vector<TreeNode> children = new Vector<TreeNode>();
public TreeNode(String name){
this.name = name;
}
/*添加子节点*/
public void add(TreeNode node){
children.add(node);
}
/*删除子节点*/
public void remove(TreeNode node){
children.remove(node);
}
/*取得孩子节点*/
public Enumeration<TreeNode> getChildren(){
return children.elements();
}
/*寻找某孩子节点,找到了返回true,深度优先*/
public boolean find(String name) {
if (children != null) {
for (TreeNode node : children) {
if (node.getName() == name) {
return true;
}
if (node.find(name)){
return true;
}
}
}
return false;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public TreeNode getParent() {
return parent;
}
public void setParent(TreeNode parent) {
this.parent = parent;
}
}
public class Tree {
/*根节点*/
TreeNode root = null;
public Tree(String name) {
root = new TreeNode(name);
}
}
/*主函数*/
public static void main(String[] args) {
Tree tree=new Tree("a");
TreeNode node1=new TreeNode("b");
TreeNode node2=new TreeNode("c");
TreeNode node3=new TreeNode("d");
TreeNode node4=new TreeNode("e");
tree.root.add(node1);
tree.root.add(node2);
node2.add(node3);
node1.add(node4);
/*直接子节点true*/
System.out.println(tree.root.find("b"));
/*间接子节点true*/
System.out.println(tree.root.find("d"));
/*无此节点*/
System.out.println(tree.root.find("x"));
}
true
true
false
将多个对象组合在一起进行操作,常用于表示树形结构中,例如二叉树等
享元模式(Flyweight)
享元模式的主要目的是实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,//通常与工厂模式一起使用。
FlytFactory负责创建和管理享元单元,当一个客户端请求时,共享池需要检查当前对象池中是否有符合条件的对象,如果有,就返回已经存在的对象,如果没有,则创建一个新对象,FlyWeight是超类。
public interface FlyWeight {
public void action(int k);
}
//具体被共享对象
public class ConcreteFlyWeight implements FlyWeight {
private int fno;
//判断是哪个对象在操作
@Override
public void action(int k) {
System.out.println("对象:"+k);
}
//构造函数 同时可以判断创建了多少对象
public ConcreteFlyWeight(int fno) {
super();
this.fno = fno;
System.out.println("cfw 构造函数");
}
//判断两个对象的值是否相等
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
ConcreteFlyWeight other = (ConcreteFlyWeight) obj;
if (fno != other.fno)
return false;
return true;
}
}
//共享池,管理对象
public class FlyFactory {
private static Map flys=new HashMap();
public FlyFactory(int a){
flys.put(a, new ConcreteFlyWeight(a));
}
//判断共享池中是否有需要的对象,有就返回,无则创建
public ConcreteFlyWeight getConcreteFlyWeight(int a){
if(flys.get(a)==null){
flys.put(a, new ConcreteFlyWeight(a));
}
return (ConcreteFlyWeight) flys.get(a);
}
}
//主函数
public static void main(String[] args) {
//创建共享池,池中初始有一个元素 1
FlyFactory fly=new FlyFactory(1);
//从共享池中得到对象 1
ConcreteFlyWeight cf1=fly.getConcreteFlyWeight(1);
cf1.action(1);
//从共享池中得到对象2,池中没有自行创建
ConcreteFlyWeight cf2=fly.getConcreteFlyWeight(2);
cf2.action(2);
//从共享池中得到对象 1
ConcreteFlyWeight cf3=fly.getConcreteFlyWeight(1);
cf3.action(1);
//判断cf1和cf3是否来自同一个对象
System.out.println(cf1.equals(cf3));
}
结果:
cfw 构造函数
对象:1
cfw 构造函数
对象:2
对象:1
true
从结果可知一共只创建了两个对象,所以cf1与cf3得到的是同一个对象;
行为型
第一类:通过父类与子类的关系进行实现。
第二类:两个类之间。
第三类:类的状态。
第四类:通过中间类
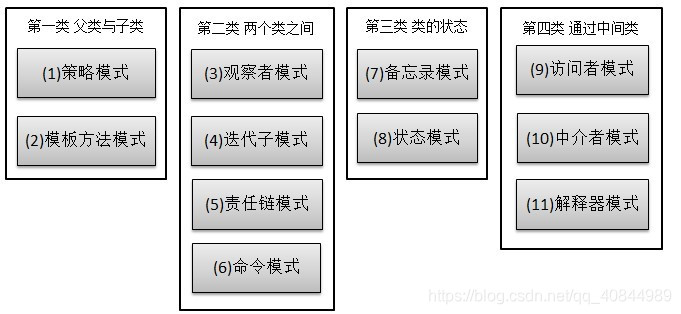
父类与子类关系
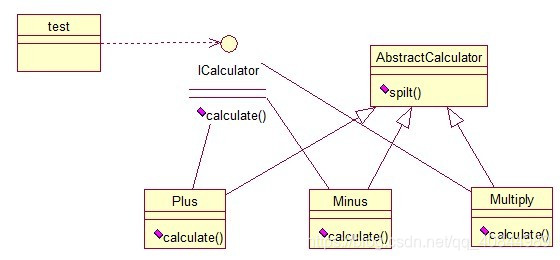
策略模式(strategy)
策略模式定义了一系列算法,并将每个算法封装起来,使他们可以相互替换,且算法的变化不会影响到使用算法的客户。需要设计一个接口,为一系列实现类提供统一的方法,多个实现类实现该接口,设计一个抽象类(可有可无,属于辅助类),提供辅助函数.
统一接口 Algorithm,三个实现接口的类加(plus),减(minus),乘(Multiply),继承抽象类(SplitString)提供辅助函数split()将字符串,如“2+8”,变成int 2,8。
public interface Algorithm {
public int operation(String str);
}
public class SplitString {
public int[] split(String str,String exp){
String array[]=str.split(exp);
int arrayInt[] = new int[2];
arrayInt[0] = Integer.parseInt(array[0]);
arrayInt[1] = Integer.parseInt(array[1]);
return arrayInt;
}
}
public class Plus extends SplitString implements Algorithm {
@Override
public int operation(String str) {
int arr[]=split(str, "\\+");
return arr[0]+arr[1];
}
}
public class Minus extends SplitString implements Algorithm {
@Override
public int operation(String str) {
int arr[]=split(str, "-");
return arr[0]-arr[1];
}
}
public class Multiply extends SplitString implements Algorithm {
@Override
public int operation(String str) {
int arr[]=split(str, "\\*");
return arr[0]*arr[1];
}
}
/**/
public static void main(String[] args) {
String exp = "8*2";
Algorithm cal = new Multiply();
int result = cal.operation(exp);
System.out.println(result);
//Plus Minus Multiply
}
模板方法模式(Template Method)
指:一个抽象类中,有一个主方法,再定义1…n个方法,可以是抽象的,也可以是实际t的方法,定义一个类,继承该抽象类,重写抽象方法,通过调用抽象类,实现对子类的调用
实现方法:抽象类Algorithm,主方法operation(),operation()调用spilt(),Plus和Minus分别继承Algorithm类,通过对Algorithm的调用实现对子类的调用
/**/
public abstract class Algorithm {
public final int operation(String str,String opt) {
int arr[]=split(str,opt);
return operation(arr[0],arr[1]);
}
public abstract int operation(int num1,int num2);
public int[] split(String str,String exp){
String array[]=str.split(exp);
int arrayInt[] = new int[2];
arrayInt[0] = Integer.parseInt(array[0]);
arrayInt[1] = Integer.parseInt(array[1]);
return arrayInt;
}
}
public class Plus extends Algorithm {
@Override
public int operation(int num1, int num2) {
return num1+num2;
}
}
public class TemMenthodMain {
public static void main(String[] args) {
String str="8+2";
Algorithm al=new Plus();
System.out.println(al.operation(str,"\\+"));
}
}
al调用operation(string,string),然后调用split(),再调用operation(int , int ),通过此方法调用子类的方法。
“\+”:因为 +、*、|、\等符号在正则表达示中有相应的不同意义,所以在使用时要进行转义处理。
("\\*")或("[*]")
类之间的关系
观察者模式(Observer)
包括这个模式在内的接下来的四个模式,都是类和类之间的关系,不涉及到继承,学的时候应该 记得归纳,记得本文最开始的那个图。观察者模式很好理解,类似于邮件订阅和RSS订阅,当我们浏览一些博客或wiki时,经常会看到RSS图标,就这的意思是,当你订阅了该文章,如果后续有更新,会及时通知你。其实,简单来讲就一句话:***当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化!***对象之间是一种一对多的关系。
MySubject类就是我们的主对象,Observer1和Observer2是依赖于MySubject的对象,当MySubject变化时,Observer1和Observer2必然变化。AbstractSubject类中定义着需要监控的对象列表,可以对其进行修改:增加或删除被监控对象,且当MySubject变化时,负责通知在列表内存在的对象。
一旦被观察者发生改变,所有观察它的观察者就是收到信息;两个接口(Observer,Subject),两个观察者(Observer1,Observer2),被观察者种类可能有很多,将其共性抽出组成AbstractSubject,然后MySubject继承抽象类。
/*观察者*/
public interface Observer {
public void update();
}
public class Observer1 implements Observer {
@Override
public void update() {
System.out.println("Observer1 has received");
}
}
public class Observer2 implements Observer {
@Override
public void update() {
System.out.println("Observer2 has received");
}
}
/*被观察者*/
public interface Subject {
public void add(Observer observer);
public void del(Observer observer);
public void informvObservers();
public void opertion();
}
public abstract class AbstractSubject implements Subject {
private Vector<Observer> vector = new Vector<Observer>();
@Override
public void add(Observer observer) {
vector.add(observer);
}
@Override
public void del(Observer observer) {
vector.remove(observer);
}
@Override
public void informvObservers() {
Enumeration<Observer> enumo = vector.elements();
while(enumo.hasMoreElements()){
enumo.nextElement().update();
}
}
@Override
public void opertion() {
}
}
public class MySubject extends AbstractSubject {
@Override
public void opertion() {
System.out.println("update self!");
informvObservers();
}
}
/*主函数*/
public static void main(String[] args) {
Subject sub=new MySubject();
sub.add(new Observer1());
sub.add(new Observer2());
sub.opertion();
}
迭代子模式(Iterator)@
迭代器模式就是顺序访问聚集中的对象,一般来说,集合中非常常见,如果对集合类比较熟悉的话,理解本模式会十分轻松。这句话包含两层意思:一是需要遍历的对象,即聚集对象,二是迭代器对象,用于对聚集对象进行遍历访问。
MyCollection中定义了集合的一些操作,MyIterator中定义了一系列迭代操作,且持有Collection实例.
Collection接口:创建Iterator(),得到元素的值get(),集合的大小size()
Iterator接口:判断是否有下个值 hasNext(),下一个并输出();
/*集合*/
public interface Collection {
public Iterator iterater();
public Object get(int i);
public int size();
}
public class MyCollection implements Collection {
/*字符数组存储集合内的元素值*/
String string[];
public String[] getString() {
return string;
}
public void setString(String[] string) {
this.string = string;
}
/*创建迭代器*/
@Override
public Iterator iterater() {
return new MyIterator(this);
}
/*得到集合的某个值*/
@Override
public Object get(int i) {
return string[i];
}
/*集合大小*/
@Override
public int size() {
return string.length;
}
}
/*迭代器*/
public interface Iterator {
public boolean hasNext();
public Object next();
public Object first();
}
/**/
public class MyIterator implements Iterator {
private Collection collection;
/*从一开始遍历*/
private int index=-1;
public MyIterator(Collection collection) {
this.collection = collection;
}
/*判断是否为空?*/
@Override
public boolean hasNext() {
if(index<collection.size()-1){
return true;
}
else{
return false;
}
}
/*前进输出*/
@Override
public Object next() {
if(index<collection.size()-1){
index++;
}
return collection.get(index);
}
/*置空index,每次遍历输出前都要置空*/
@Override
public Object first() {
index=0;
return null;
}
}
/**/
public static void main(String[] args) {
String str[]={"A","B","C","D","E","F","G"};
String str2[]={"A","B","C","D","E"};
MyCollection mco=new MyCollection();
Iterator it=mco.iterater();
mco.setString(str);
while(it.hasNext()){
System.out.print(it.next());
}
System.out.println();
mco.setString(str2);
it.first();
while(it.hasNext()){
System.out.print(it.next());
}
}
ABCDEFG
BCDE
责任链模式(Chain of Responsibility)
责任链模式,有多个对象,每个对象持有对下一个对象的引用,这样就会形成一条链,请求在这条链上传递,直到某一对象决定处理该请求。但是发出者并不清楚到底最终那个对象会处理该请求,所以,责任链模式可以实现,在隐瞒客户端的情况下,对系统进行动态的调整。
public interface Handler {
public void operator();
}
public abstract class AbstractHandler {
private Handler handler;
public Handler getHandler() {
return handler;
}
public void setHandler(Handler handler) {
this.handler = handler;
}
}
public class MyHandler extends AbstractHandler implements Handler {
String name;
public MyHandler(String name) {
this.name = name;
}
@Override
public void operator() {
System.out.println(name+"deal");
if(getHandler()!=null)
getHandler().operator();
}
}
/*主函数*/
public static void main(String[] args) {
MyHandler h1=new MyHandler("h1");
MyHandler h2=new MyHandler("h2");
MyHandler h3=new MyHandler("h3");
h1.setHandler(h2);
h2.setHandler(h3);
h1.operator();
}
责任链的重点在与发出者并不清楚到底最终那个对象会处理该请求,可以动态的调整。比如上面的例子中就可以再创建一个h4,让h4处理命令,而发出者并不知道是谁处理的。
此处强调一点就是,链接上的请求可以是一条链,可以是一个树,还可以是一个环,模式本身不约束这个,需要我们自己去实现,同时,在一个时刻,命令只允许由一个对象传给另一个对象,而不允许传给多个对象。
命令模式(Command)
司令员下令让士兵去干件事情,从整个事情的角度来考虑,司令员的作用是,发出口令,口令经过传递,传到了士兵耳朵里,士兵去执行。这个过程好在,三者相互解耦,任何一方都不用去依赖其他人,只需要做好自己的事儿就行,司令员要的是结果,不会去关注到底士兵是怎么实现的。
Invoker是调用者(司令员),Receiver是被调用者(士兵),MyCommand是命令,实现了Command接口,持有接收对象
将军类:构造函数时带命令,发布命令()
士兵类: 执行命令();
命令类: 构造函数时谁接受命令,调用接受命令的人的执行方法()
public interface Command {
void exe();
}
public class GeneralCommand implements Command {
private Soldier soldier=new Soldier();
public GeneralCommand(Soldier soldier) {
this.soldier = soldier;
}
@Override
public void exe() {
soldier.action();
}
}
public class Soldier {
public void action() {
System.out.println("士兵执行命令");
}
}
public class General {
private Command command;
public General(Command command) {
this.command = command;
}
public void action(){
command.exe();
}
}
/*主函数*/
public static void main(String[] args) {
Soldier soldier=new Soldier();
/*命令的接受者是士兵*/
GeneralCommand gc=new GeneralCommand(soldier);
/*这个命令是将军发布的*/
General gen=new General(gc);
soldier.action();
}
命令模式的目的就是达到命令的发出者和执行者之间解耦,实现请求和执行分开
类的状态
备忘录模式(Memento)
主要目的是保存一个对象的某个状态,以便在适当的时候恢复对象,个人觉得叫备份模式更形象些,通俗的讲下:假设有原始类A,A中有各种属性,A可以决定需要备份的属性,备忘录类B是用来存储A的一些内部状态,类C呢,就是一个用来存储备忘录的,且只能存储,不能修改等操作。
需要备份的类(Original)有GreatMemento(),restoreMemento()(给备忘录赋值);
备忘录类(Memento)
存储备忘录的类(Storage)(用来存放备忘录的,可以和备忘录合并吗?)
public class Original {
String value;
/*创建备忘录*/
public Memento GreatMemento() {
return new Memento(value);
}
/*从备忘录中恢复*/
public void restoreMemento(Memento memento){
this.value=memento.value;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public Original(String value) {
this.value = value;
}
}
public class Memento {
String value;
public Memento(String value) {
this.value = value;
}
}
public class Storage {
private Memento memento;
public Memento getMemento() {
return memento;
}
public Storage(Memento memento) {
this.memento = memento;
}
}
public static void main(String[] args) {
Original org=new Original("qqq");
//创建备忘录
Storage storage = new Storage(org.GreatMemento());
// 修改原始类的状态
System.out.println("初始化状态为:" + org.getValue());
org.setValue("niu");
System.out.println("修改后的状态为:" + org.getValue());
// 启用备忘录,回复原始类的状态
org.restoreMemento(storage.getMemento());
System.out.println("恢复后的状态为:" + org.getValue());
}
主函数 创建org,赋初值qqq;
创建storage ,调用org的GreatMemento(),这个方法返回一个Memento对象其值为org的值,也就是org的备份,这个备份被storage构造函数调用,这个备份被storage的私有Memento实例存储;
恢复时,调用storage.getMemento() 其返回被存储起来的备份,该备份被org.restoreMemento使用,org的value被复原;
//storage和Memento可以合并吗?
假设合并成storage,首先其构造函数能接受org的GreatMemento()返回的备份(storage类)
Storage storage = org.GreatMemento();//storage.value=org.value;
恢复备份的时候 将其value给org;
org.restoreMemento(storage);
功能是可以完成的。不合并可能是因为避免直接使用Memento类,导致备份被修改,实现信息的封装,采用列表、堆栈等集合来存储备忘录对象可以实 现多次撤销操作;
状态模式(State)(?)
核心思想就是:当对象的状态改变时,同时改变其行为,很好理解!就拿QQ来说,有几种状态,在线、隐身、忙碌等,每个状态对应不同的操作,而且你的好友也能看到你的状态,所以,状态模式就两点:1、可以通过改变状态来获得不同的行为。2、你的好友能同时看到你的变化。
public class State {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public void method1(){
System.out.println("execute the first opt!");
}
public void method2(){
System.out.println("execute the second opt!");
}
}
public class Context {
private State state;
Context(State state){
this.state=state;
}
void menthod(){
if(state.getValue().equals("state1")){
state.method1();
}else if(state.getValue().equals("state2")){
state.method2();
}
}
}
/*主函数*/
public static void main(String[] args) {
State state=new State();
state.setValue("state1");
Context context=new Context(state);
context.menthod();
}
method1 / 2()为什么要放在state里?
因为是context根据stated 状态改变方法,所以主函数里context调用的方法名是不变的,固定的method().而将method1 / 2()整合到context中,则method()变成:
void menthod(){
if(state.getValue().equals("state1")){
/*state1 context的操作*/
System.out.println("execute the first opt!");
}else if(state.getValue().equals("state2")){
/*state2 context的操作*/
System.out.println("execute the second opt!");
}
}
在我们的例子中好像可以。可能是因为放在state里,集中起来好修改,但是这样要增加或删除 被state 影响的类,就要修改state,不符合开闭原则。
通过中间类
访问者模式(visitor)
访问者模式把数据结构和作用于结构上的操作解耦合,使得操作集合可相对自由地演化。访问者模式适用于数据结构相对稳定算法又易变化的系统。因为访问者模式使得算法操作增加变得容易。若系统数据结构对象易于变化,经常有新的数据对象增加进来,则不适合使用访问者模式。访问者模式的优点是增加操作很容易,因为增加操作意味着增加新的访问者。访问者模式将有关行为集中到一个访问者对象中,其改变不影响系统数据结构。其缺点就是增加新的数据结构很困难。—— From 百科
简单来说,访问者模式就是一种分离对象数据结构与行为的方法,通过这种分离,可达到为一个被访问者动态添加新的操作而无需做其它的修改的效果。
可以在不改变这个数据结构的前提下定义作用于这些元素的新的操作。
访问者是一个接口,它拥有一个 visit 方法,这个方法对访问到的对象结构中不同类型的元素做出不同的处理;处理方法由数据结构(subject)和操作(visitor)共同决定
Visitor:它定义了对每一个元素(Element)访问的行为,它的参数就是可以访问的元素,它的方法数理论上来讲与元素个数是一样的,因此,访问者模式要求元素的类族要稳定,如果经常添加、移除元素类,必然会导致频繁地修改Visitor接口,如果这样则不适合使用访问者模式。
/*访问者接口*/
public interface Visitor {
/*有两个数据结构A,B,所以有两个方法*/
public void visit(SubjectA sub);
public void visit(SubjectB sub);
}
/*访问者A*/
public class VisitorA implements Visitor {
/*VisitorA 对subjectA,subjectB的操作并不一样*/
@Override
public void visit(SubjectA sub) {
System.out.println("the subject : " + sub.getSubject()+" the operation : VisitorA to SubjectA");
}
@Override
public void visit(SubjectB sub) {
System.out.println("the subject : " + sub.getSubject()+" the operation : VisitorA to SubjectB");
}
}
/*访问者B*/
public class VisitorB implements Visitor {
/*VisitorB 对subjectA,subjectB的操作又与VisitorA的不一样*/
@Override
public void visit(SubjectA sub) {
System.out.println("the subject : " + sub.getSubject()+" the operation : VisitorB to SubjectA");
}
@Override
public void visit(SubjectB sub) {
System.out.println("the subject : " + sub.getSubject()+" the operation : VisitorB to SubjectA");
}
}
/*结构接口*/
public interface Subject {
public void accpect(Visitor visitor);
public String getSubject();
}
/*数据结构A*/
public class SubjectA implements Subject {
@Override
public void accpect(Visitor visitor) {
visitor.visit(this);
}
@Override
public String getSubject() {
return "数据结构A";
}
}
/*数据结构B*/
public class SubjectB implements Subject {
@Override
public void accpect(Visitor visitor) {
visitor.visit(this);
}
@Override
public String getSubject() {
return "数据结构B";
}
}
/*主函数*/
public static void main(String[] args) {
VisitorA visitorA=new VisitorA();
VisitorB visitorB=new VisitorB();
SubjectA subA=new SubjectA();
SubjectB subB=new SubjectB();
subA.accpect(visitorA);
subA.accpect(visitorB);
subB.accpect(visitorA);
subB.accpect(visitorB);
}
the subject : 数据结构A the operation : VisitorA to SubjectA
the subject : 数据结构A the operation : VisitorB to SubjectA
the subject : 数据结构B the operation : VisitorA to SubjectB
the subject : 数据结构B the operation : VisitorB to SubjectA
输出结果取决于Subject,Visitor,这实现了数据结构和作用于结构上的操作解耦合。
//尝试添加SubjectC和VisitorC
VisitorC只需要实现Visitor接口就行,理论上实现和数据结构数量相同的方法即可。
public class VisitorC implements Visitor {
@Override
public void visit(SubjectA sub) {
System.out.println("the subject : " + sub.getSubject()+" the operation : VisitorC to SubjectA");
}
@Override
public void visit(SubjectB sub) {
System.out.println("the subject : " + sub.getSubject()+" the operation : VisitorC to SubjectA");
}
}
SubjectC除了实现Subject接口外,从Visitor接口到各种Visitor类都要修改,增加visit(SubjectC sub)。
所以如果经常添加、移除Subject类则不适合使用访问者模式。
//结构对象角色
对象结构是一个抽象表述,它内部管理了元素集合,并且可以迭代这些元素供访问者访问。可以遍历结构中的所有的元素;如果需要,提供一个高层次的接口让访问者对象可以访问每一个对象,可以设计成一个复合对象或一个集合(Set),(List)
public class SubjectStructure {
private Vector subjects;
private Subject subject;
public SubjectStructure(){
subjects = new Vector();
}
/*执行访问操作*/
public void action(Visitor visitor){
for(Enumeration e=subjects.elements();e.hasMoreElements();){
subject=(Subject)e.nextElement();
subject.accpect(visitor);
}
}
/*增加一个新元素*/
public void add(Subject sub){
subjects.add(sub);
}
}
/*主函数*/
public static void main(String[] args) {
SubjectStructure substr=new SubjectStructure();
VisitorA visitorA=new VisitorA();
SubjectA subA=new SubjectA();
SubjectB subB=new SubjectB();
substr.add(subA);
substr.add(subB);
substr.action(visitorA);
}
the subject : 数据结构A the operation : VisitorA to SubjectA
the subject : 数据结构B the operation : VisitorA to SubjectB
该模式适用场景:如果我们想为一个现有的类增加新功能,不得不考虑几个事情:1、新功能会不会与现有功能出现兼容性问题?2、以后会不会再需要添加?3、如果类不允许修改代码怎么办?面对这些问题,最好的解决方法就是使用访问者模式,访问者模式适用于数据结构相对稳定的系统,把数据结构和算法解耦,
中介者模式(Mediator)
中介者模式也是用来降低类类之间的耦合的,因为如果类类之间有依赖关系的话,不利于功能的拓展和维护,因为只要修改一个对象,其它关联的对象都得进行修改。如果使用中介者模式,只需关心和Mediator类的关系,具体类类之间的关系及调度交给Mediator就行,这有点像spring容器的作用。
假设:Mediator类用来减低user1和user2之间的耦合,user1和user2之间的关系及调度交给Mediator。
因为user被Mediator调度,所以Mediator应有user1,user2的实例,有得到user1,user2实例的方法(getUser()).
getUser()应能调用user1,user2的构造函数:
/*中介者接口*/
public interface Mediator {
public void getUser();
public void workAll();
}
/*具体中介者类*/
public class MyMediator implements Mediator {
private User user1;
private User user2;
@Override
public void getUser() {
user1=new User1(this);
user2=new User2(this);
}
@Override
public void workAll() {
user1.work();
user2.work();
}
}
/**/
public abstract class User {
/*user类中有Mediator类型字段,让每一个user类知道它的中介者对象。(可以不要吗?)*/
private Mediator mediator;
public abstract void work() ;
public User(Mediator mediator){
this.mediator=mediator;
}
}
/**/
public class User1 extends User {
public User1(Mediator mediator) {
super(mediator);
}
@Override
public void work() {
System.out.println("User1 work!");
}
}
/**/
public class User2 extends User {
public User2(Mediator mediator) {
super(mediator);
}
@Override
public void work() {
System.out.println("User2 work!");
}
}
/*主函数*/
public static void main(String[] args) {
Mediator mediator = new MyMediator();
mediator.getUser();
mediator.workAll();
}
user类中Mediator类型字段在本例子中没作用,实事上在广义的中介者模式中user类中可以不要Mediator类型字段
中介者模式的功能就是:封装对象之间的交互。如果一个对象的操作会引起其他相关对象的变化,或者是某个操作需要引起其他对象的后续或连带操作,而这个对象又不希望自己处理这些关系,那么就找中介者,只需要通知中介者,其他中介者去处理就可以。
解释器模式(Interpreter)
解释器模式一般主要应用在OOP开发中的编译器的开发中,所以适用面比较窄。
定义一个语言的文法,并且建立一个解析器解析该语言中的句子,“语言”是指使用规定格式和语法的代码。
核心模块(抽象表达式Expression)
public interface Expression {
public int explain(Context context);
}
/*加*/
public class Plus implements Expression {
@Override
public int explain(Context context) {
return context.getNum1()+context.getNum2();
}
}
/*减*/
public class Minus implements Expression {
@Override
public int explain(Context context) {
return context.getNum1()-context.getNum2();
}
}
/*环境*/
public class Context {
private int num1;
private int num2;
public Context(int num1, int num2) {
super();
this.num1 = num1;
this.num2 = num2;
}
public int getNum1() {
return num1;
}
public void setNum1(int num1) {
this.num1 = num1;
}
public int getNum2() {
return num2;
}
public void setNum2(int num2) {
this.num2 = num2;
}
}
/*主函数*/
public static void main(String[] args) {
// 计算9+2-8
int result = new Minus().explain((new Context(new Plus()
.explain(new Context(9, 2)), 8)));
System.out.println(result);
}
//不要Context ?
不要Context显然该例子的功能是可以实现,那为什么要context? 不知道
总结
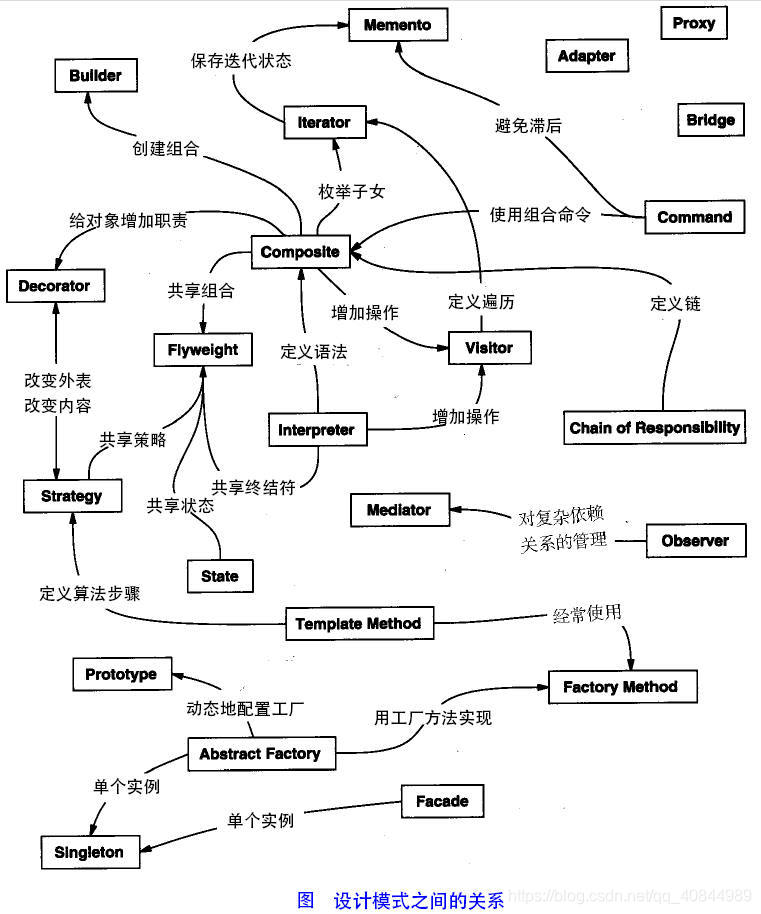
设计原则
开闭原则(Open Close Principle)
开闭原则的意思是:对扩展开放,对修改封闭。在程序需要进行扩展的时候,不能去修改或影响原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性更好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类。
里氏代换原则(Liskov Substitution Principle)
里氏代换原则是面向对象设计的基本原则之一。
里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。里氏代换原则是继承复用的基石,只有当子类可以替换掉基类,且软件单位的功能不受到影响时,基类才能真正被复用,而且子类也能够在基类的基础上增加新的行为。里氏代换原则是对开闭原则的补充。实现开闭原则的关键步骤就是抽象化,而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
依赖倒转原则(Dependence Inversion Principle)
这个原则是开闭原则的基础,核心内容:针对接口编程,高层模块不应该依赖底层模块,二者都应该依赖抽象而不依赖于具体。
接口隔离原则(Interface Segregation Principle)
这个原则的意思是:使用多个隔离的接口,比使用单个庞大的接口要好。其目的在于降低耦合度。由此可见,其实设计模式就是从大型软件架构出发,便于升级和维护软件的设计思想。它强调低依赖、低耦合。
单一职责原则(Single Responsibility Principle)
类的职责要单一,不能将太多的职责放在一个类中。
可能有的人会觉得单一职责原则和前面的接口隔离原则很相似,其实不然。其一,单一职责原则原注重的是职责;而接口隔离原则注重对接口依赖的隔离。其二,单一职责原则主要约束的是类,其次才是接口和方法,它针对的是程序中的实现和细节;而接口隔离原则主要约束接口,主要针对抽象,针对程序整体框架的构建。
最少知道原则(Demeter Principle)
最少知道原则也叫迪米特法则,就是说:一个实体应当尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立。
一个对象应该对其他对象保持最少的了解。类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。如果两个类不必彼此直接通信,那么这两个类就不应当发生直接的相互作用。如果其中一个类需要调用另一个类的某一个方法的话,可以通过第三者转发这个调用。所以在类的设计上,每一个类都应当尽量降低成员的访问权限。
合成复用原则(Composite Reuse Principle)
合成复用原则就是在一个新的对象里通过关联关系(组合关系、聚合关系)来使用一些已有的对象,使之成为新对象的一部分;新对象通过委派调用已有对象的方法达到复用功能的目的。简而言之,尽量多使用组合/聚合 的方式,尽量少使用甚至不使用继承关系。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









