







最近的一个项目需要根据业务,在服务器端根据数据动态生成word,包括填入数据、图片,根据内容控制表格的行数。所以就去网上搜索java操作word的第三方库。然后试了一下,感觉到很麻烦,光是填入数据这个小小的功能,都十分难写。正当一筹莫展之际,看到了网上大佬的方法: 将word转成xml,再使用freeMark对xml文档操作,最后将xml转成word。最后自己看别人的文章实现了下,确实简单方便。大佬文章链接。
下面教大家如何实现:简单数据填充、插入图片、动态插入表格。
下面是我写好了的模板word:
我们现在要做的是,根据数据动态填写姓名、头像图片、成绩。
一、将word文件转成xml文件
不要直接改后缀名,不然打开全是乱码!在保存界面选择“另存为”,然后保存类型选择xml。

二、对xml文件进行处理
使用freemarker语法对xml文档进行处理,然后才能填充。freemarker功能强大,一些逻辑判断都是可以实现的,在此就只讲我们需要用到的语法。先将xml文件拷贝复制进idea中,然后使用idea的格式化功能,就能比较清晰的看到xml文档的结构。
1、首先,我们定位到“我叫小明”这一句: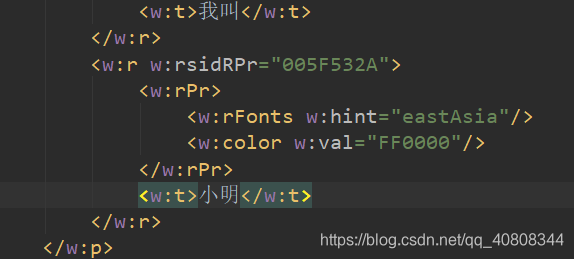
将其替换: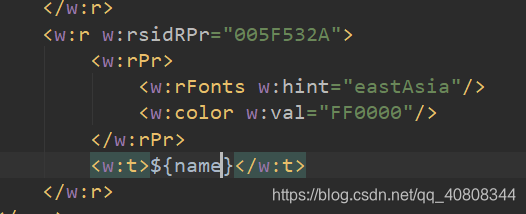
2、替换图片。图片在xml中以base64的方式存储,当你看到一大段不知所云的字符时你就找到了。
将字符替换为${image}
3、动态生成表格的操作。<w:tr></w:tr>代表word表格的一行。下面的xml对应word表格中的一行 “数学” “97”。
<w:tr w:rsidR="00EB70DF" w:rsidTr="00EB70DF">
<w:tc>
<w:tcPr>
<w:tcW w:w="4148" w:type="dxa"/>
</w:tcPr>
<w:p w:rsidR="00EB70DF" w:rsidRDefault="00EB70DF" w:rsidP="00EB70DF">
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
<w:t>数学</w:t>
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:tcPr>
<w:tcW w:w="4148" w:type="dxa"/>
</w:tcPr>
<w:p w:rsidR="00EB70DF" w:rsidRDefault="00EB70DF" w:rsidP="00EB70DF">
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
<w:t>97</w:t>
</w:r>
</w:p>
</w:tc>
</w:tr>只需在这一段最外层,包上循环语句<#list grades as grade></#list>,然后将“数学”改为${grade.courseName},“97” 改为${grade.score}。
<#list grades as grade> //添加
<w:tr w:rsidR="00EB70DF" w:rsidTr="00EB70DF">
<w:tc>
<w:tcPr>
<w:tcW w:w="4148" w:type="dxa"/>
</w:tcPr>
<w:p w:rsidR="00EB70DF" w:rsidRDefault="00EB70DF" w:rsidP="00EB70DF">
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
<w:t>${grade.courseName}</w:t> //改为占位符
</w:r>
</w:p>
</w:tc>
<w:tc>
<w:tcPr>
<w:tcW w:w="4148" w:type="dxa"/>
</w:tcPr>
<w:p w:rsidR="00EB70DF" w:rsidRDefault="00EB70DF" w:rsidP="00EB70DF">
<w:pPr>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:rFonts w:hint="eastAsia"/>
</w:rPr>
<w:t>${grade.score}</w:t> //改为占位符
</w:r>
</w:p>
</w:tc>
</w:tr>
</#list> //添加至此,xml文件的处理完成。接下来进入代码编写阶段。
三、代码编写
首先要导入freemarker的依赖包。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
<version>2.1.2.RELEASE</version>
</dependency>测试代码编写:
public class FMarker {
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
DocumentHandler dh = new DocumentHandler();
Template t = dh.getTemplate();
Writer out = dh.getWriter();
List<Grade> grades = new ArrayList<>();
grades.add(new Grade("语文","70"));
grades.add(new Grade("英语","80"));
grades.add(new Grade("物理","90"));
//注意 变量名要与xml中占位符保持一致
map.put("name","小红");
map.put("grades",grades);
map.put("image",dh.getImageStr());
dh.createDoc(t, map, out);
}
}
class DocumentHandler {
private Configuration configuration = null;
public DocumentHandler() {
this.configuration = new Configuration();
this.configuration.setDefaultEncoding("utf-8");
}
//将xml文件转成模板
public Template getTemplate() {
configuration.setClassForTemplateLoading(this.getClass(),
"/com/test/word");
Template t = null;
try {
t = configuration.getTemplate("Doc1.xml");//模板xml路径
t.setEncoding("utf-8");
} catch (IOException e) {
e.printStackTrace();
}
return t;
}
//获得输出流对象
public Writer getWriter() {
//填充后,新文件路径
File outFile = new File("D:\\ideacode\\uploadServlet\\src\\main\\java\\com\\test\\word\\newDoc1.doc");
Writer out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(outFile), "utf-8"
));
} catch (UnsupportedEncodingException | FileNotFoundException e) {
e.printStackTrace();
}
return out;
}
//转化生成word文件
public void createDoc(Template t, Map dataMap, Writer out) {
try {
t.process(dataMap, out);
out.close();
} catch (TemplateException | IOException e) {
e.printStackTrace();
}
}
//将图片转化成BASE64
public String getImageStr(){
//新图片路径
String imageFile = "D:\\ideacode\\uploadServlet\\src\\main\\java\\com\\test\\word\\newImage.jpg";
InputStream in = null;
byte[] data = null;
try{
in = new FileInputStream(imageFile);
data = new byte[in.available()];
in.read(data);
in.close();
}catch (IOException e){
e.printStackTrace();
}
BASE64Encoder base64Encoder = new BASE64Encoder();
return base64Encoder.encode(data);
}
}项目结构:
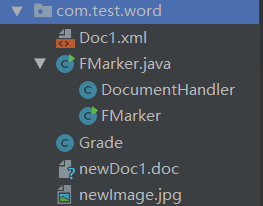
Doc1.xml就是预先准备的word模板
DocumentHanlder是核心操作类
FMarker是来写测试函数的
Grade类就两个成员变量:courseName,score。我就不写出来了。
newDoc1.doc是生成的word文档
newImage是准备插入的图片
最终结果:

而且不知道大家注意到没有,我们填充的“小红”也变成了红色字体,我们插入的图片,大小也是保持和原来一样!其实原理很简单,word在转成xml时,关于格式的控制信息也随之写入xml里,我们只是改了内容,而没改格式。所以后填入的数据格式会和之前的数据保持一致。这样,我们只要预先设置好模板的格式,就能动态生成自己想要的格式的文档!其次freemarker的语法功能还远不止这些,有兴趣的同学可以去看一下。

















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









