






一 .mysql 架构
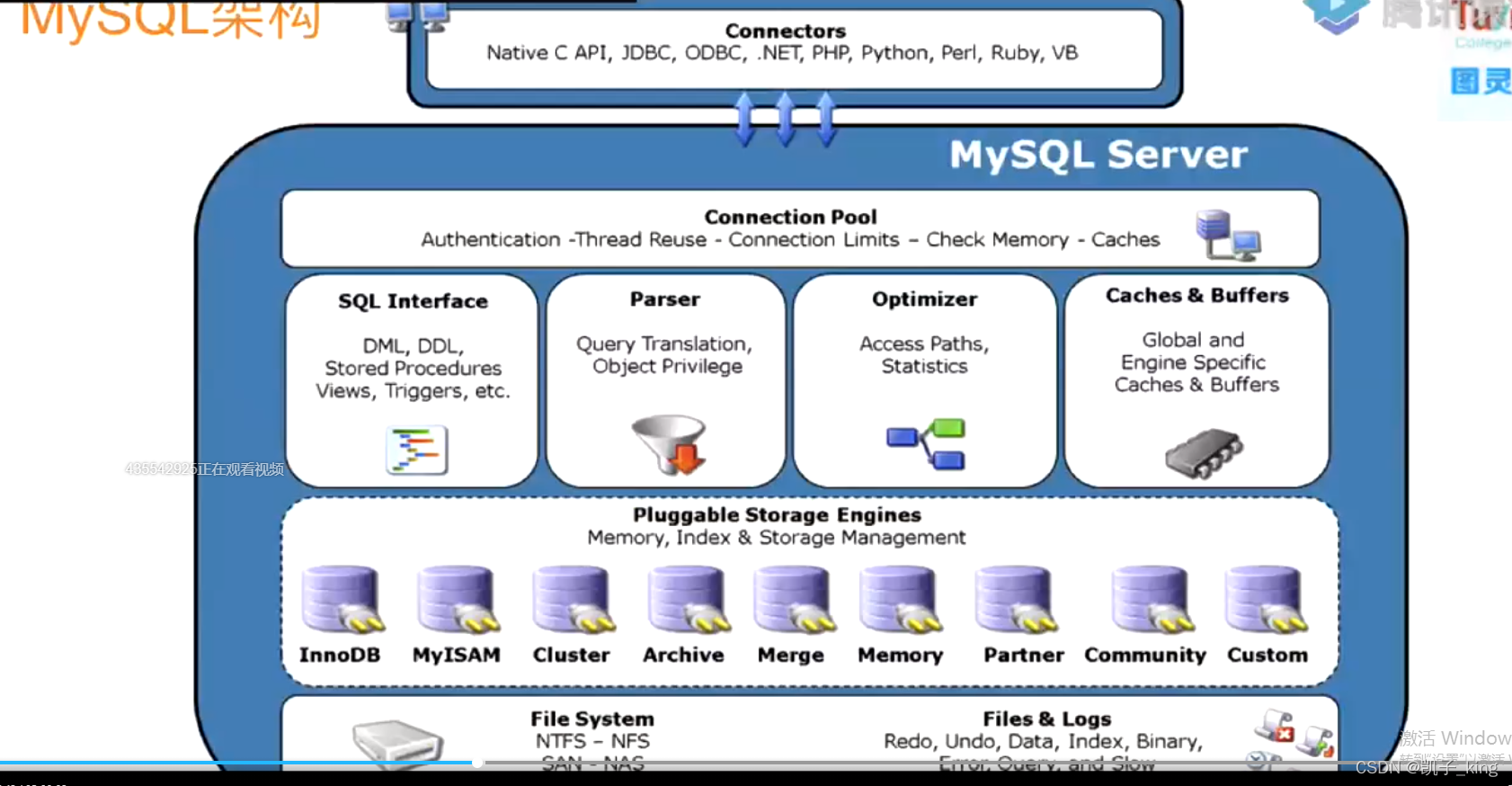
1.主从
2.集群
3.分布式
(1)路由
(2)存储
(3实例
二.索引底层数据结构与算法
1.索引面试面试题优化
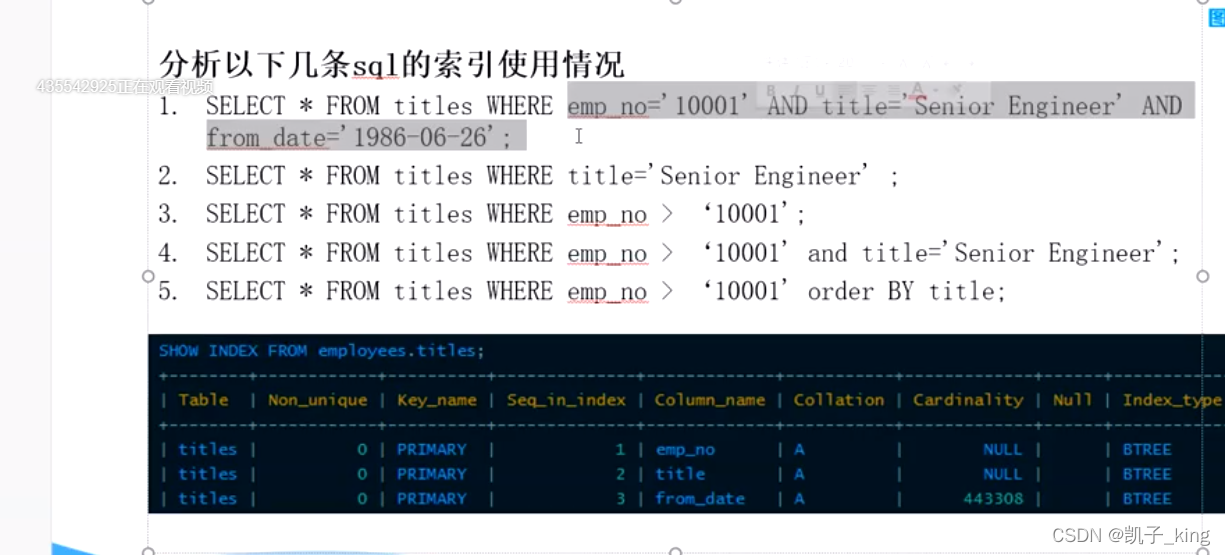
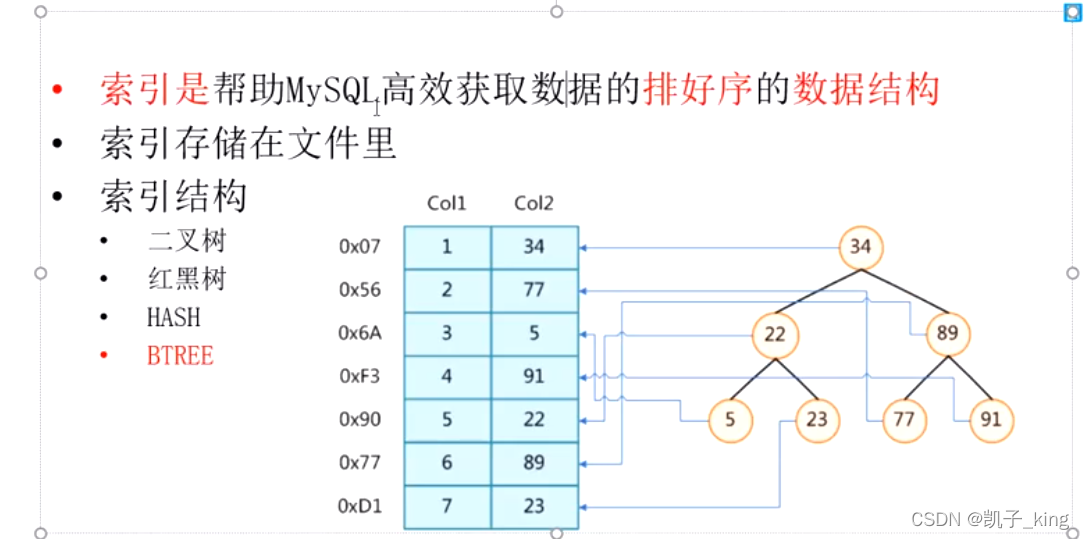 2.索引的数据结构
2.索引的数据结构
mysql 底层 b+tree 和hash
(a). 二叉树:容易一条链到底单边增长,不会分叉.
(b). 红黑树:深度很长 (数据量大的时候深度会很深)
©. hash:用hash 不太适用于范围查找 比如a>5
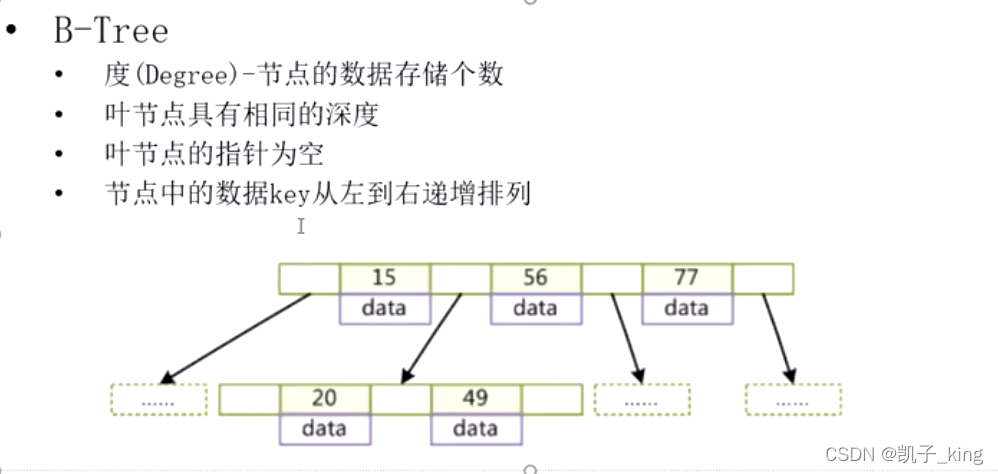
(d). b-tree:每个节点(度)增加存储数量,且深度保持一样 ,横向发展 百万数据 最多6层 ,每个类型都是k,v 类型 k 索引 v数据值.
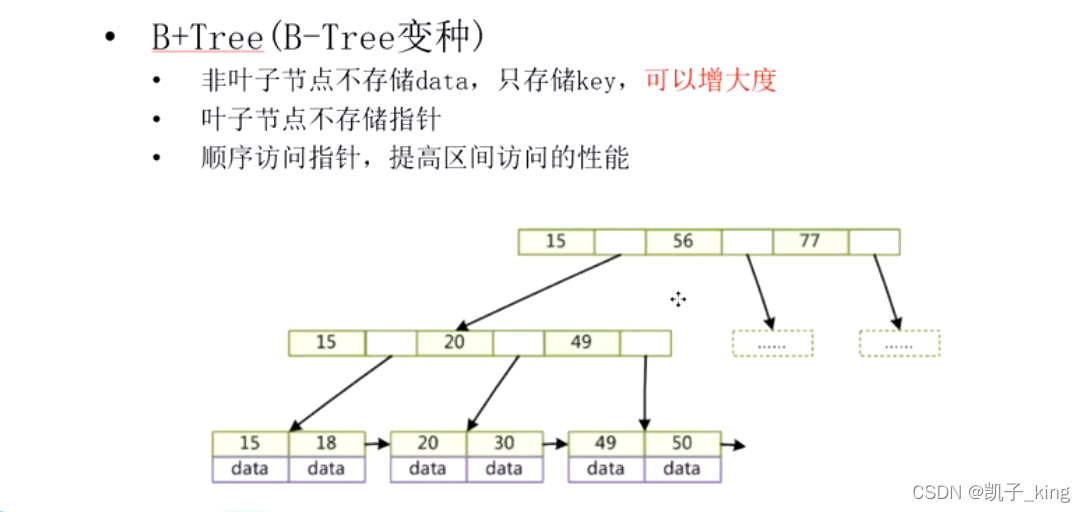
,但是mysql 是用b+tree(因为磁盘和内存的交互页的大小限制了交互 所以用了b+tree 把度里面只存key)
(e). b+tree : 把度里面只存key ,数据value 放在叶子结点 ,增加了指针叶子节点的尾元素和下一个叶子结点的元素相连(方便范围查找)
数据交互
javv<—>CPU <–>RAM<----如果内存没有才会去硬盘查找交互单位是页(4K)- 页多整数倍(根计算机硬件有关)–> 硬盘

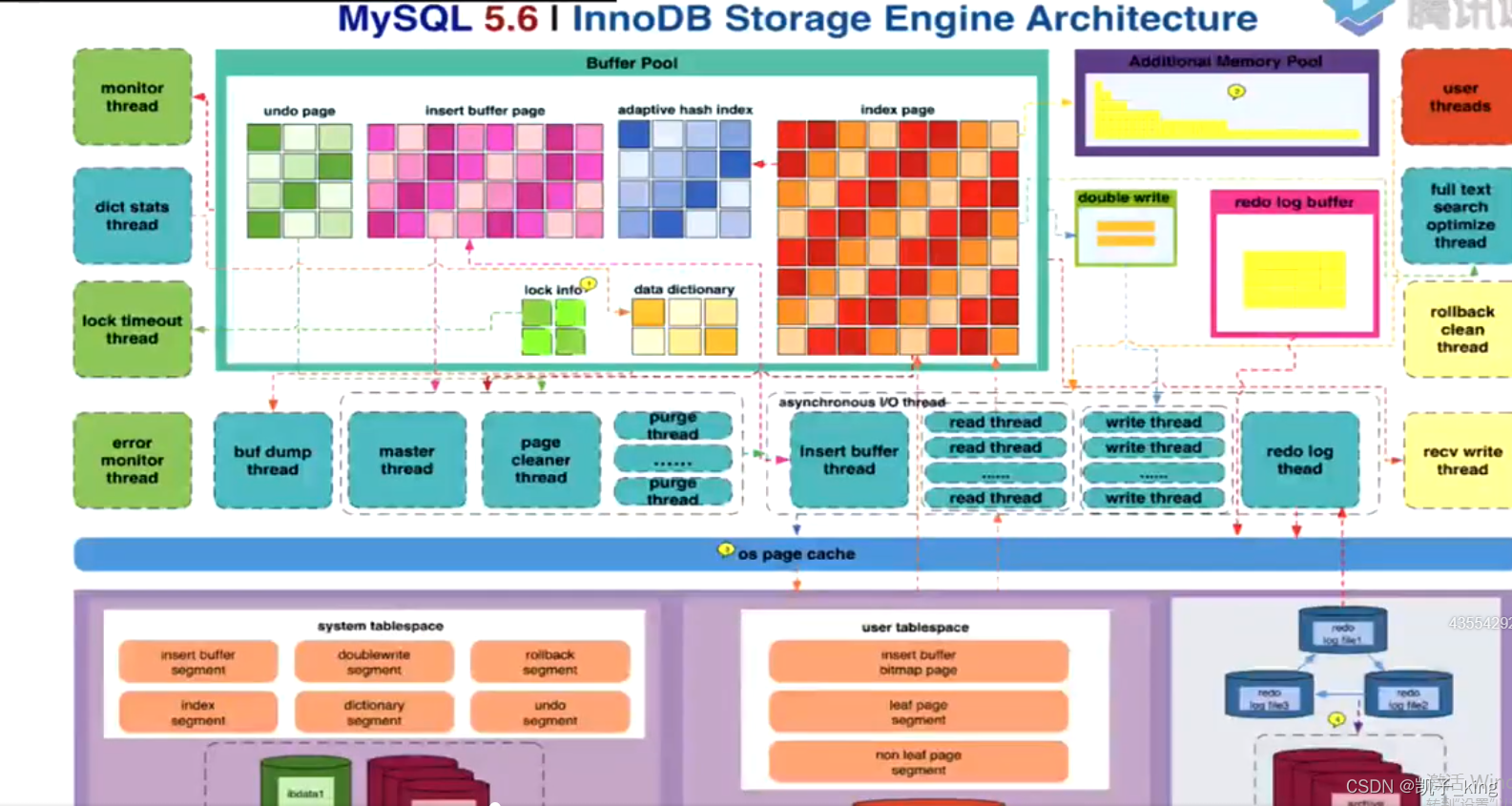
3. 存储引擎 (是表级别不是数据库级别) 默认是innoDB
4.MYISAM 和innodb
两个文件个数不一样
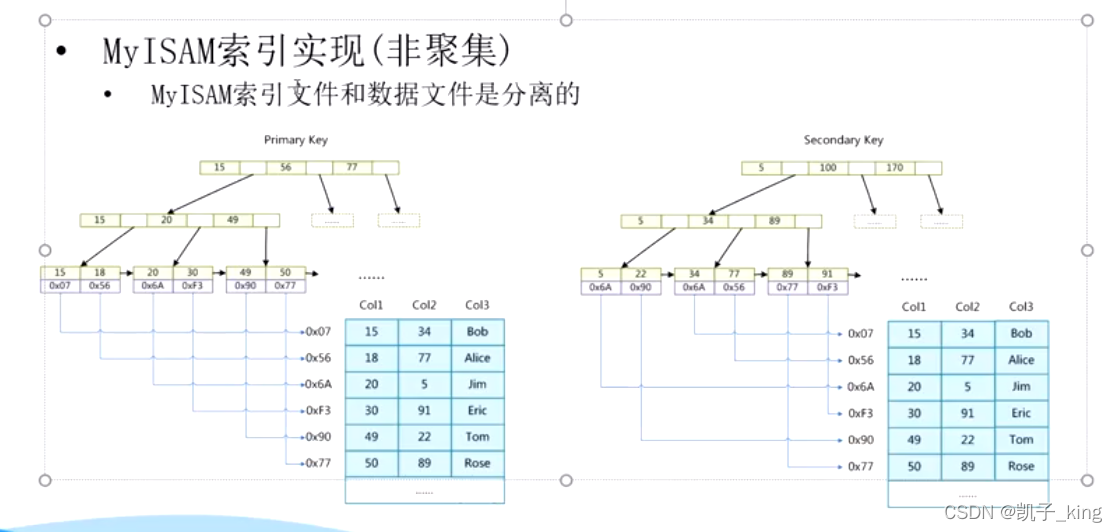
(a.)MYISAM (.frm 表结构 .MYD 数据 .MYI 索引<key 加上索引的列名 值 ,data 是值的磁盘地址> )
非聚集索引
:主键索引 和其他列名索引存储相似 key 加上索引的列名 值 ,data 是值的磁盘地址
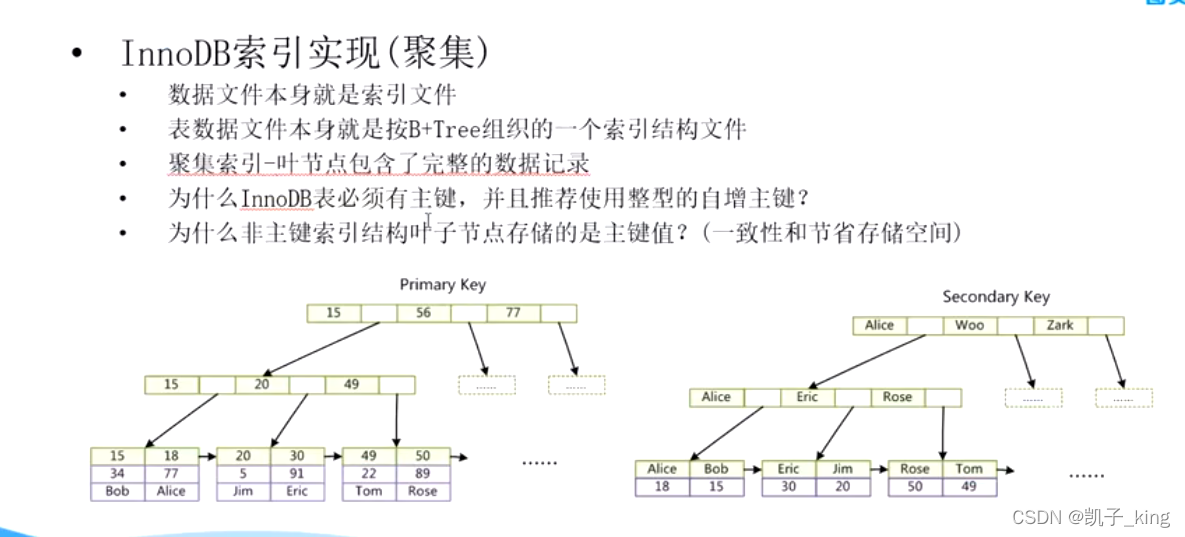
(b.)innodb (frm 表结构,ibd 数据+索引)
聚集索引(查询快,节省存储空间,数据一致性<一起存储减少分布式查找>)
主键索引 : key 加上索引的列名 值 ,data 整行记录保存
其他列索引:key 加上索引的列名 值 ,data 主键
innodb 必须要有主键 ,没有主键 默认会找一个做为主键
因为innodb 有一个主键文件,所以必须要有主键(要用自增主键<那让存储结构可以存在连续性>)
为什么用数字 不用uuid ?
(a) id 容易比较大小 字符串需要用ASCII 去比较 不容易比较大小,
(b) 而且id 容易有序排序 ,读取一页数据的时候方便范围查找.uuid 容易插入时候无序 且可能树分裂
5.联和索引的底层数据结构长什么样子?
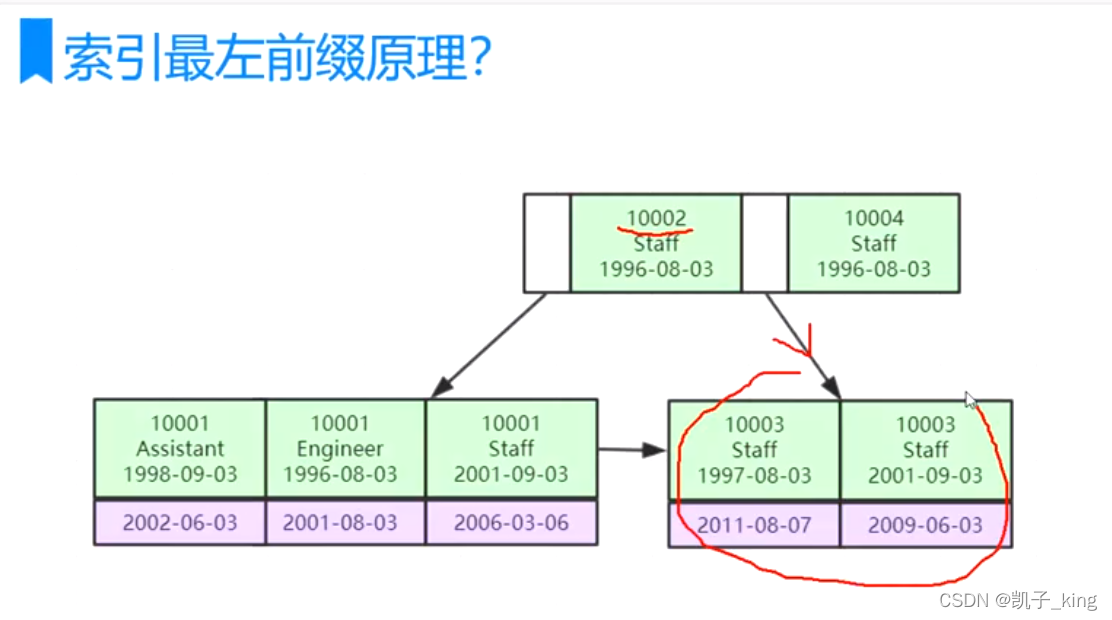 (a) 从第一个 一个一个比较.依次在第二个 一个一个比较
(a) 从第一个 一个一个比较.依次在第二个 一个一个比较
(b)
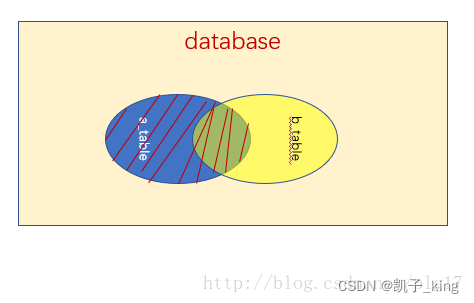
- inner join :组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。
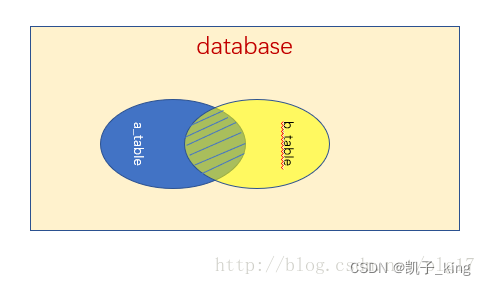 left join
left join
left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。
左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
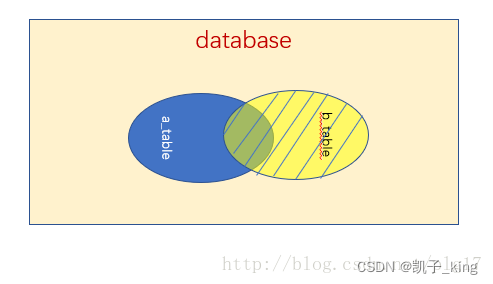
right join
right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。
与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
7. explan 如果后面加extended 可以加拓展语句 比如:show warnings 优化后语句
a.表字段值
(1).id: id 列的序号是select的序列号 有几个select 就有几个id 并且id序号 按照select 出现顺序增长的 msql 将select查询分为简单查询(simple) 和复杂查询(praimary) 复查类查询分为:简单子查询 ,派生表(from 语句中的子查询),union 查询.id列越大执行优先级越高,id 相同则由上往下执行 id为null 最后执行
(2).select_type : 语句类型 表示是简单还是复杂查询 ,如果是复杂查询又是上述三种复杂查询中的一种
simple:简单查询,查询不包括子查询和unnion
primary :复杂查询中最外层select
subquery 包含在selec中的子查询 (不在from 子句中)
derived:包含from 子句中的子查询.mysql 会将结果存放在一个临时表中,也称为派生表
union: 在union中的第二个和随后的select
union resoult :从union 临时表检索结果的select
(3).table:表名
(4.)type(重点): 这一列表示关联类型 即mysql 决定如何查询表中的行,查找数据行记录的大概范围.依次最优到最差 system>const>eq_ef>ref>range>index>all 一般来说 要保证查询达到range级别 最高达到ref
null:mysql 能在优化阶段j分解查询语句,在执行阶段用不着在访问表或索引.例如在索引列选取最小值.可以单独来完成,不需要在只从时访问表.
cost: mysql 能对查询到某部分进行优化并将其转化为一个常量(可以看show warnings的结果) 用于primarykey或者unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取一次.速度快.(根据主键或者唯一键查询 只会存在一条语句的).
system: 是const的特例 表里只有一条元组匹配是为system(查询的表就一条记录).
eq_ref:primary kry 或者unique key 索引的所有部分被连接使用,最多只会被返回一条符合条件的记录,这可能是在const 之外最好的 的连接类型,简单的select 查询不会出现这种 type.(作为关联使用,最多返回一条满足的记录)
ref:相比eq_ref 不实用唯一索引,而是使用普通索引或者唯一索引的部分前缀,索引要和某个值相比较,可能会找到多个条件的行(不是主键索引 是其他索引)
range:范围扫描通常出现在 in() ,between,>,<,>=,<=等操作中,使用一个索引来检索给定的范围.
index:扫描浅表索引,通常比all 快一些 (index是从索引中读取的,all 是从硬盘中读取的).
all : 全表扫描 意味着musql 需要从头到尾去查找所需要的行,通常情况下这个需要增加索引来进行优化了.
(5) ppssible_keys: 这一列显示查询可能使用哪些索引来查找.explan 时可能出现possible_keys 有列,而key 显示为null,这种情况是因为表中数据不多,mysql 认为索引对查询影响不大,选择全表查询.如果该列为null 则没有相关的索引,在这种情况下where 子句看是否可以创造一个适当的索引来提高查询性能.然后用explan 查看效果
(6)key: 这一列显示mysql 实际在用哪个索引来优化对表的访问,如果没有使用索引,则该列为null,如果请示mysql 使用或者忽视possible_keys列中的索引,在查询中使用 force index,ignore index.
(7)key_len: 这一列显示mysql 在索引列使用的字节数,通过这个值可以算出具体使用索引中的哪些列
举例来说.film_actor的联合缩影 idx_file_actor_id有film_id和actor_id两个int 列组成,并且每个int 4字节,通过结果中的 key_len =4 可以推断出查询使用了第一列:《film_id来执行索引查找.(表示走了哪个字段索引)》
《name varchar(10) =3*10+2 ,id int (4) =4 》 如果支持为null 还要+1
(8)ref: 这一列显示了在key列记录的索引中,表查找值所用到的列或者常量,常见的有:const(常量值) ,字段名(filn.id).(引用的是索引的值 还是字段)
(9)rows: 这一列是mysql 估计要读取并且检测的行数,注意这个不是结果集里面的行数.
(10)Extra: 这一列展示额外信息,常见的重要值如下:
using index: 查询的列被索引覆盖,并且where 筛选条件是索引的前导列(联合索引最左匹配),是性能高的表现.一般是使用了覆盖索引(索引包含了所查询的字段),对于innodb 来说,如果是辅助索引性能会有不少提高(select 里面的列 全是索引的,并且where 条件是索引前导列)
user where:查询列未被索引覆盖,where 筛选条件非索引前导列(select 里面的列,不全都是索引列《select *》,并且where 条件也不是索引前导列)
using where using index:查询的列被索引覆盖,并且where筛选条件是索引列之一但是 不是索引的前导列.意味着无法直接通过索引查找来查询到符合条件的数据(select 里面的列 全是索引列,并且where 条件 有索引列之一 但不是索引前导列)
null:查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现,不是单纯的用到索引,也不是完全没用到索引.(select 里面的列 不全是索引列,并且where 条件是索引前导列)
using index condition: 与using where 类似,查询列不完全被索引覆盖,where 条件中是一个前导列的范围(select 里面的列,不全都是索引列《select *》,并且where 条件也是索引前导列,范围查询《a>1》)
using tempory:mysql 需要创建一张临时表来处理查询.出现这种情况一般要进行优化的,首先想到用索引来优化.
(select distinct name from table name 没索引这种 《考虑把name 加索引就可以了》)
using filesort:mysql 会对结果使用一个外部索引排序,而不是按照索引次序从表里取行,此时mysql会跟据连接类型浏览符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息,这种情况下一般也是要考虑索引优化.
(用order by name 排序 name 没索引这种 《考虑把name 加索引就可以了,因为索引提前排好序了》)

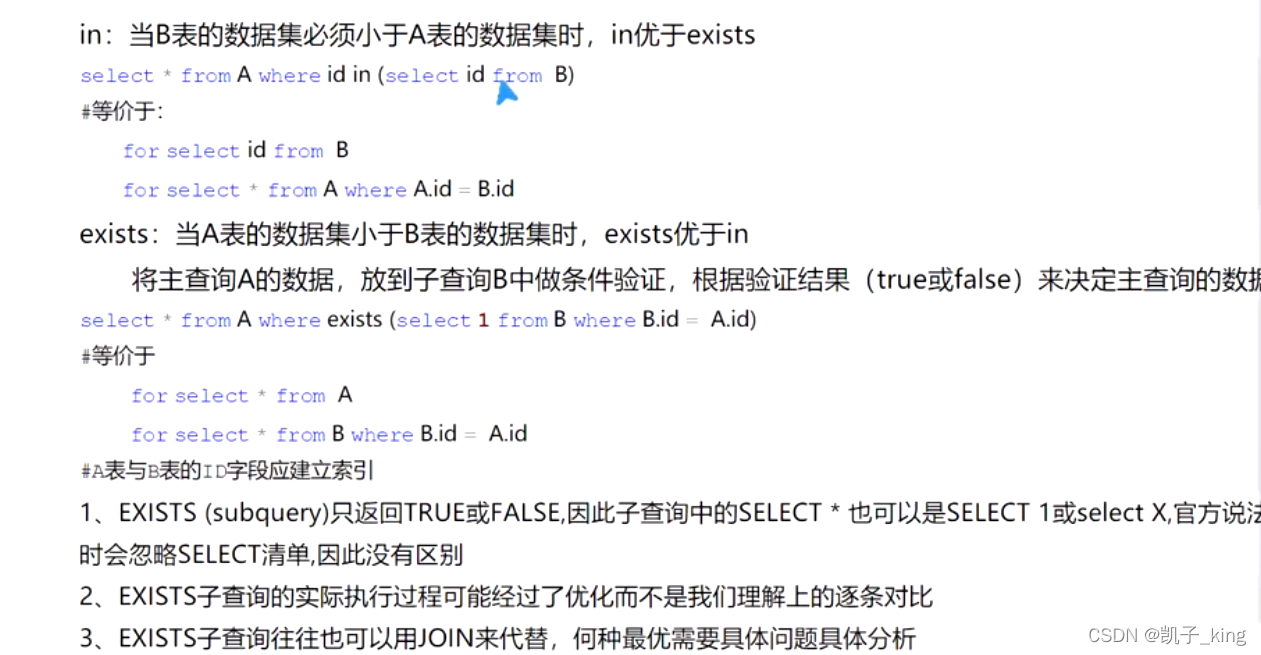
8. exist 和 in 原则
in 小表驱动打表,即小的数据集驱动大的数据集 (小的先执行)
exist 大表驱动打表,即小的数据集驱动小的数据集 (大的先执行)
存储过程:
··· demo1
drop procedure if exists kai_demo_procedure;
CREATE PROCEDURE kai_demo_procedure (in delegationNo VARCHAR(32),out orderNum int,INOUT billNoInfo VARCHAR(128)
,out message VARCHAR(64),out caseMessage VARCHAR(64))
BEGIN
-- 注意点:1.出入参数 如果是 VARCHAR 或者 CHAR 需要指定长度,不然报错;
-- 2.逻辑处理部分 需要用 BEGIN AND 包裹;
-- 3.out出参,不支持对象返回,如果单条记录且 返回的字段较少 可以用多个out,如果是集合可以用临时表;
-- 4.出入参数名称或者 变量名称不要和表字段名称一样,如果一样给表取个别名;
-- 5.into 使用 在一个select中只能出现一次,否则报错 具体demo 往下看 ***demo 这个标记的方法 举例:select a,b,c into A,B,C from table limit 1;
-- 6.if 条件 结束需要 end if; , elseif 不能写成 else if , if/elseif 记得加 then;
-- demo调用语法 :set @billNoInfo='提单号信息';
-- CALL kai_demo_procedure('2022081301',@orderNum,@billNoInfo,@message,@caseMessage);
-- SELECT @orderNum,@billNoInfo,@message,@caseMessage;
-- 声明局部变量 (变量分为四种:局部变量 (bengin......and 中有效),用户变量@age(当前连接有效),全局变量@@global.age(整个mysql服务器有效),会话变量 @@session.age(当前连接有效))
DECLARE bookingId BIGINT(20) DEFAULT 0 ;
DECLARE billNo VARCHAR(32);
-- 进行局部变量赋值
SET bookingId =747766892512256;
-- 用户变量
set @englishName='KING';
-- 执行sql 语句 根据 set 赋值之后的bookingId进行查询
SELECT * from booking_order where booking_id =bookingId;
-- into 赋值 除了 set 之外的另一种赋值
SELECT bill_no into billNo FROM booking_order where booking_id =bookingId;
-- 根据 into 赋值之后的提单号进行查询
SELECT * FROM booking_expand WHERE bill_no =billNo;
-- ***demo 根据传入的参数 delegationNo查询数量 并且返回出去
SELECT CONCAT(billNoInfo,':',GROUP_CONCAT(bill_no)),COUNT(1) into billNoInfo, orderNum FROM booking_expand WHERE delegation_no = delegationNo GROUP BY delegation_no;
-- if 条件判断
if orderNum = 0 then
set message = '委托编号下面没有数据';
elseif orderNum =1 then
set message = '委托编号下面存在1条数据';
else
set message='委托编号下面数据大于1' ;
end if;
CASE
when orderNum = 0 then
set caseMessage = '委托编号下面没有数据';
when orderNum = 1 then
set caseMessage = '委托编号下面存在1条数据';
else
set caseMessage='委托编号下面数据大于1' ;
end case;
END
set @billNoInfo='提单号信息';
CALL kai_demo_procedure('2022081301',@orderNum,@billNoInfo,@message,@caseMessage);
SELECT @orderNum,@billNoInfo,@message,@caseMessage;
demo2
drop procedure if exists kai_demo1_procedure;
CREATE PROCEDURE kai_demo1_procedure(in forParam INT,inout loopResp VARCHAR(128),inout repeatResp VARCHAR(128),inout whileResp VARCHAR(128))
BEGIN
-- 注意点 1.loop一定要有LEAVE 不然会死循环
-- 2. while 和 loop,repeat 不同的是 不需要起别名
-- 3.cursor游标 ,fetch 取的值 也是按照 select a,b,c from table ,a,b,c 顺序取的
-- 4.fetch坑: 循环中如果没有数据可以取会报异常 解决办法 1. 事先获取数量(按数量设置循环次数) 2. handler句柄处理
-- 5.声明的游标 变量一定要放在最前面
-- 6.具柄什么要放在游标后面
-- 7. 动态创建表方式: prepare create_table_stmt FROM @create_table_sql; 后面不能使用局部变量 excute create_table_stmt; DEALLOCATE prepare create_table_stmt;
-- demo 调用 : set @loopResp='loop循环次数'; set @repeatResp='repeat循环多次次之后跳出循环'; set @whileResp='while循环多次次之后跳出循环';
-- call kai_demo1_procedure(0,@loopResp,@repeatResp,@whileResp); select @loopResp,@repeatResp,@whileResp; select * from temp_info;
-- 声明两个变量用于接收参数
declare groupName VARCHAR(64);
declare useStatus VARCHAR(32);
-- 声明变量用于控制是否继续循环
declare continueFlag boolean default true;
-- 声明游标
declare cursor_demo cursor for SELECT group_name,use_status from booking_order_group ;
-- 声明具柄 用于改变 continueFlag 值
-- 1329 是错误码 具体自己去看 下面这句话的含义是 如果 发现异常码是1329(也可以用别名 02*** 对应的NOT FUND) 就把continueFlag变为false 继续(continue)往下走 这里如果用 exit select forParam 这里就不会继续走了
declare continue handler for 1329 set continueFlag =false;
-- loop 循环 +leave(相当于java break) +iterate
-- loop_demo 是循环的别名,如果 loop 和 end loop 之间没有 leave loop_demo; 这就是一个死循环;死循环解决办法 SHOW PROCESSLIST ; kill id;
loop_demo:loop
set loopResp = CONCAT(loopResp,'-',forParam);
if forParam < 5 then
set forParam = forParam + 1; -- 自增
iterate loop_demo; -- 代表继续循环loop
end if;
LEAVE loop_demo; -- 离开循环
end loop loop_demo;
-- 方便下面循环使用 赋值0
set forParam = 0;
-- REPEAT 循环demo 相当于 java do while
repeat_demo :repeat
set repeatResp = CONCAT(repeatResp,'-',forParam);
set forParam = forParam + 1; -- 自增
until forParam >5 -- forParam 大于5 跳出循环
end repeat repeat_demo;
-- 方便下面循环使用 赋值0
set forParam = 0;
-- while 相当于 java while
while forParam <5 do
set whileResp = CONCAT(whileResp,'-',forParam);
set forParam = forParam + 1; -- 自增
end while;
-- 游标(cursor) + 句柄(handler) demo (把booking_order_group 放进临时表里)
-- 四个步骤 :1.声明 declare cursor_demo cursor for select * from table 2.打开 open cursor_demo
-- 3.逐个取值(fetch 一次 拿一行 需要配合 循环用) fetch cursor_demo into a,b,c....., 4.关闭 close cursor_demo)
-- 创建临时表 temp_info
CREATE TEMPORARY TABLE IF NOT EXISTS temp_info (
id INT AUTO_INCREMENT PRIMARY KEY,
group_name varchar(64) NOT NULL COMMENT '分组名称',
use_status varchar(32) NOT NULL DEFAULT '' COMMENT '使用状态: UNUSED -未使用 USED-已使用'
);
-- 打开游标
open cursor_demo ;
-- 死循环取值
loop_cursor_demo: LOOP
-- fetch 获取数据 ,这里是顺序获取列属性
fetch cursor_demo into groupName,useStatus;
INSERT into temp_info (group_name,use_status) VALUES(groupName,useStatus);
IF continueFlag=false THEN
LEAVE loop_cursor_demo;
END IF;
END LOOP loop_cursor_demo;
-- select forParam
-- 关闭游标
close cursor_demo;
END
set @loopResp='loop循环次数';
set @repeatResp='repeat循环多次次之后跳出循环';
set @whileResp='while循环多次次之后跳出循环';
call kai_demo1_procedure(0,@loopResp,@repeatResp,@whileResp);
select @loopResp,@repeatResp,@whileResp;
select * from temp_info
myabtsi 调用
```java
public ProcedureDemoResponse callProcedure() {
Map<String, Object> params = new HashMap<>();
params.put("forParam", 0);
params.put("loopResp", "loop循环次数:");
params.put("repeatResp", "repeat循环次数:");
params.put("whileResp", "while循环次数:");
//sqlSession 可以 接收出入参数
try {
ProcedureDemoRepository mapper = sqlSession.getMapper(ProcedureDemoRepository.class);
mapper.callProcedureDemo(params);
String respInfo = (String) params.get("respInfo");
System.out.println("respInfo: " + respInfo);
}catch (Exception e){
System.out.println("2222222");
}
//可以接收出入参数 接收不了 select * from table limit 1
Map<String, Object> map = new HashMap<>();
map.put("forParam", 0);
map.put("loopResp", "loop循环次数:");
map.put("repeatResp", "repeat循环次数:");
map.put("whileResp", "while循环次数:");
procedureDemoRepository.queryCallProcedure(map);
//如果 存储过程有 返回值不是出参的那种 里面有select * from table limit 1可以用这种 接收
ProcedureDemoResponse procedureDemoResponse = procedureDemoRepository.selectCallProcedure(0, "loop循环次数:", "repeat循环次数:", "while循环次数:");
return procedureDemoResponse;
}
```java
public interface ProcedureDemoRepository {
ProcedureDemoResponse selectCallProcedure(@Param("forParam") Integer forParam
, @Param("loopResp") String loopResp, @Param("repeatResp") String repeatResp, @Param("whileResp") String whileResp);
void queryCallProcedure(Map<String,Object> map);
void callProcedureDemo(Map<String,Object> map);
}
<select id="selectCallProcedure" resultMap="procedureResultMap" statementType="CALLABLE">
{call kai_demo1_procedure(#{forParam, mode=IN, jdbcType=INTEGER}, #{loopResp, mode=INOUT, jdbcType=VARCHAR}, #{repeatResp, mode=INOUT,jdbcType=VARCHAR},
#{whileResp, mode=INOUT,jdbcType=VARCHAR}, #{respInfo, mode=OUT,jdbcType=VARCHAR})}
</select>
<select id="queryCallProcedure" parameterType="java.util.Map" statementType="CALLABLE">
{call kai_demo1_procedure(#{forParam, mode=IN, jdbcType=INTEGER}, #{loopResp, mode=INOUT, jdbcType=VARCHAR}, #{repeatResp, mode=INOUT,jdbcType=VARCHAR},
#{whileResp, mode=INOUT,jdbcType=VARCHAR}, #{respInfo, mode=OUT,jdbcType=VARCHAR})}
</select>
<select id="callProcedureDemo" parameterType="java.util.Map" statementType="CALLABLE">
{call kai_demo1_procedure(#{forParam, mode=IN, jdbcType=INTEGER}, #{loopResp, mode=INOUT, jdbcType=VARCHAR}, #{repeatResp, mode=INOUT,jdbcType=VARCHAR},
#{whileResp, mode=INOUT,jdbcType=VARCHAR}, #{respInfo, mode=OUT,jdbcType=VARCHAR})}
</select>
**细节:**
distinct,group by (执行执之前都会order by 一次), 子查询 会主动帮建临时表,不用临时表可以用索引字段


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









